

AWS Glue DataBrewを一度も利用したことがなかったので、学習ついでに実際にさわりながら自分へのメモを兼ねて情報を残します。
AWS Glue DataBrewとは
2020/11にリリースされたAWS Glueに新たな機能になります。 データアナリストやデータサイエンティストがデータを簡単にクリーンアップおよび正規化して、分析や機械学習に備えることができる新しい情報可視化の準備ツールです。
執筆時点で 250を超える変換処理が用意されておりユーザーはその機能を利用し、コードを記載することなくGUIでタスクを組み、よく使われる言葉でいうところの「データ前処理」を自動化できます。
AWS Glue DataBrewはサーバーレス構成のマネージドサービスとなっているので、インフラの作成やら管理とかを気にせずにスポットで大量のRawデータを検索したり変換に利用する事ができます。
料金については以下AWS Glueの料金ページに新たなタブとして項目が追加されています。
AWS News Blog の関連エントリー
少し前にも、AWS Glue関連 (AWS Glue Studio)で実際にさわってみて blogを書いた記憶があるのですが、AWS Glue は GUI強化のアップデートが活発ですね。
さわってみる
今回は、AWS公式に開始方法として入門編のチュートリアルのようなもの(Getting started with AWS Glue DataBrew)が用意されていましたのでこちらを実施してみます。
ざっくりこれからやることをサマると以下です。
・事前準備(IAM関連のリソース作成、アウトプット用のS3 bucket作成)
・サンプルのデータセット事前に用意されているAmazon S3上のcsvファイルを読み込み
・フィルタやグルーピング、変換処理等のAWS Glue DataBrewの機能を駆使して前処理を実施
・アウトプットや各画面の確認
・クリーンアップ
step0.事前準備
当チュートリアルにはない内容ではないですが、AWS Glue DataBrewのセットアップ項目として以下公式ドキュメントに記載がされていますので確認のうえ必要な対応を実施します。 docs.aws.amazon.com
本筋ではない内容なので細かい手順について説明は割愛しますが
IAMユーザーやグループに関しては、検証環境であれば強いアカウントで省略しても良いとは思われますが
AwsGlueDataBrewDataAccessRole のロール(内部で指定されているIAMポリシー AwsGlueDataBrewDataResourcePolicy を含む)については
チュートリアル内で利用する為、作成しておく必要がある点に注意してください。
あとチュートリアルでS3バケットを利用するので、チュートリアル用として 任意の名称のS3バケットを1つ作成し、その直下に databrew-output という名称のフォルダ(厳密にいうとフォルダではないですが) を用意しておくとチュートリアルがスムーズに行えますので事前に作成しておくと良いでしょう。
Step1: プロジェクトを作成する
ここからチュートリアルに入っていきます。
マネジメントコンソールでAWS Glue DataBrewを開く
サービス一覧画面から glueやdatabrew等のキーワード検索するとHITします。

プロジェクトの作成
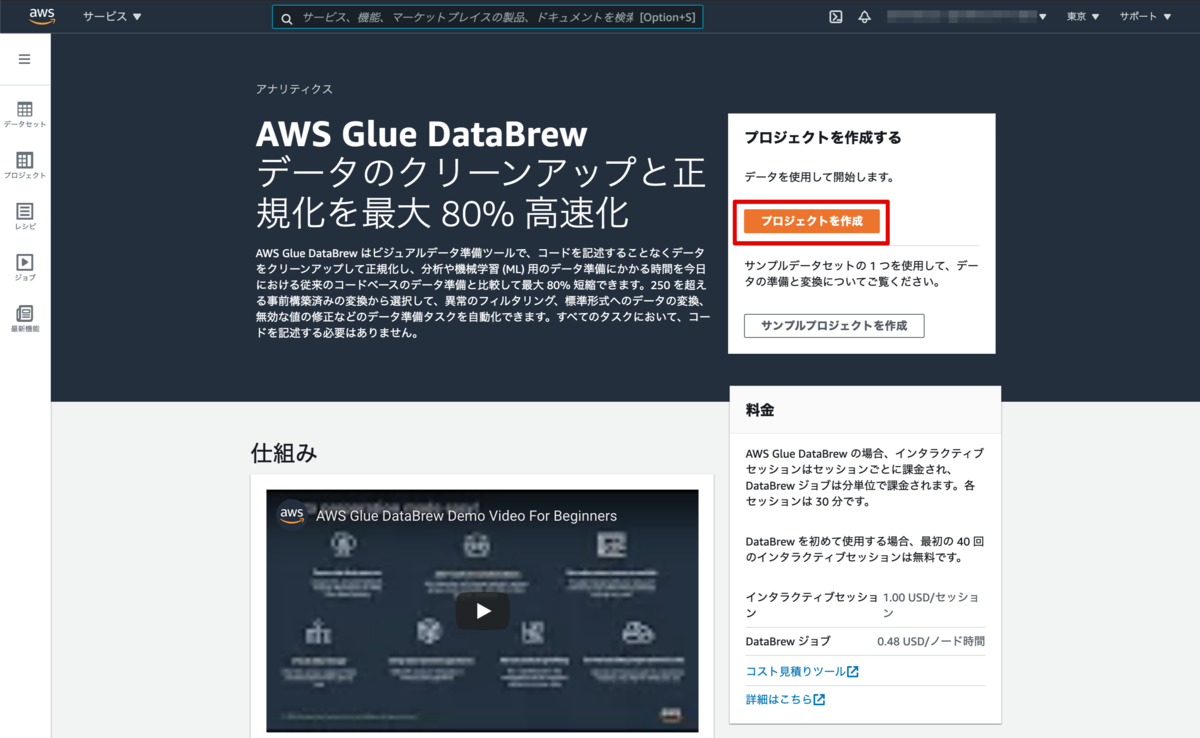
既存の情報がないと以下のようなサービストップ画面が表示されるので [プロジェクトを作成] を押下します。
サンプルファイルの選択
プロジェクト作成のフォーム画面が表示されるので以下の通り入力して指定します。
プロジェクト名: chess-project と入力
レシピ名: chess-project-recipe と入力
データセットを選択: サンプルファイル のラジオボタンを選択
サンプルファイル: 有名なチェスゲームの動き のラジオボタンを選択
データセット名: chess-games と入力
サンプルする行の数: 500 のラジオボタンを選択
アクセス許可: AwsGlueDataBrewDataAccessRole のIAMロール(step.0 事前準備で作成) を指定



プロジェクト作成が開始されると以下のような画面で処理が開始されます。 画面にもインジケーターや目安が表示され、少し時間(約1min程度)がかかります。

作成が完了すると指定したデータセットの内容が以下画面のようにプレビューで表示されます。 指定したサンプルデータ500行がただ単に表示されただけでなく、上に各カラムのメタデータらしき情報が表示されている以下点に注目してください。
・文字列だったらその該当文字列が何%を占めているのか
・Boolean型の認識
・数値だったら 最小値、最大値、中央値、平均値 や データ内の値の存在傾向 等

Step2. データを要約する
フィルターする
・変換ツールバーで、[フィルター]->[条件別]->[以上]を選択します。
右ペインにフィルタ値として条件を指定出来るようになりますので以下の通り指定し、[適用] を押下します。
ソース列: white_rating をプルダウンから指定
フィルター条件: 以上 をプルダウンから指定し、値に 1800 と入力
(このようにAWS Glue DataBrewのプロジェクト画面は、上のバーで機能を、右ペインで具体的な操作をする形となります。操作イメージが掴めたところで以後、赤枠はお休みです...zzz)
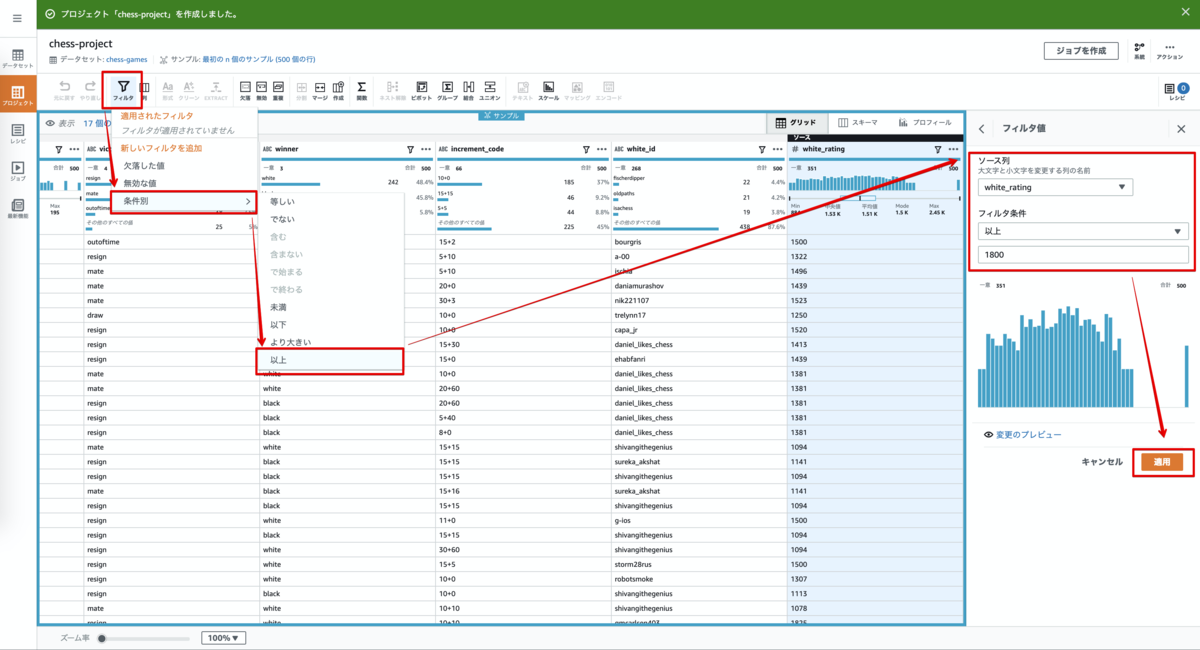
右ペインのレシピが (1) となり、先程作成したフィルタ内容が1番として表示され white_ratingカラムの値プレビューを確認するとすべて1800以上のものとなっている事が確認出来ます。

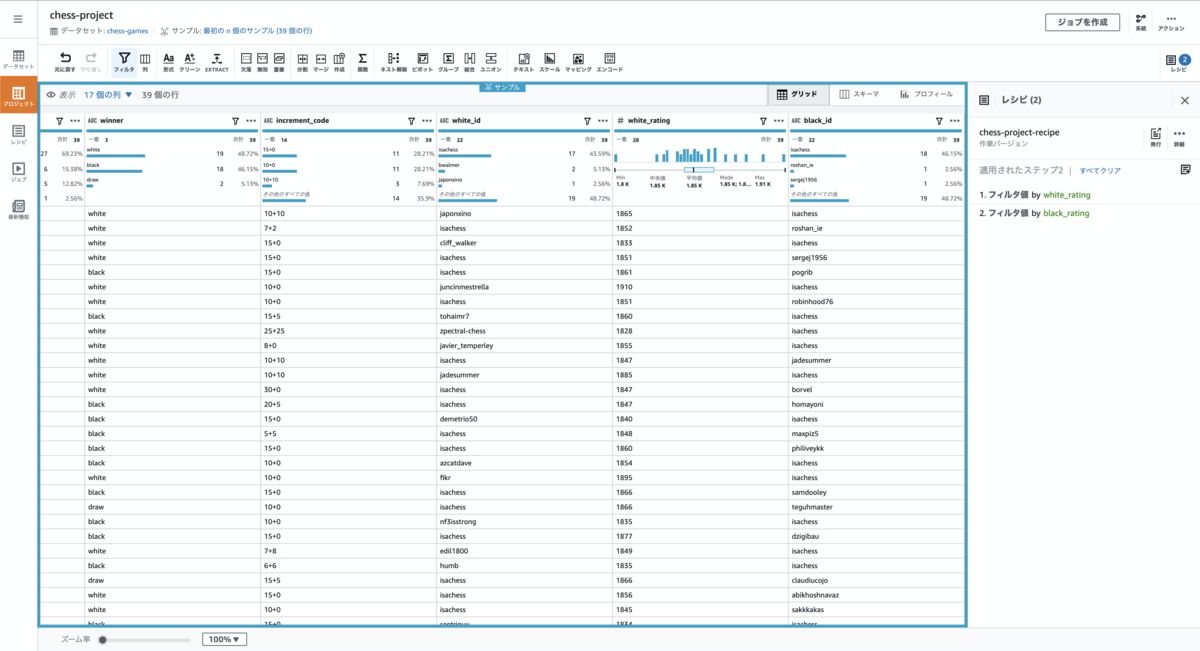
次にwhite_ratingと同じ手順でソース列- black_rating にも同様のフィルタ(1800以上)を適用します。

すると両側(黒と白)のプレイヤーがクラスA(レーティング1800)以上であったゲームのみに情報を絞れます。
グルーピング
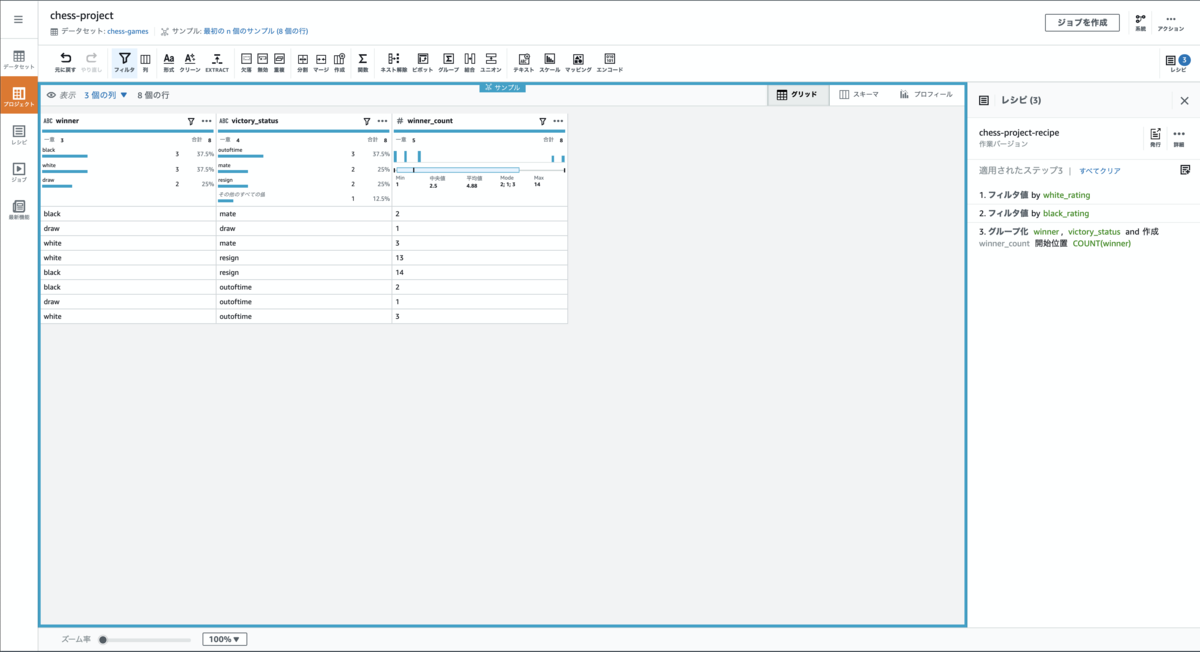
次にグルーピングの機能を利用し、勝利数のデータ集計をしてみます。
変換ツールバーで[グループ]を押下すると以下画面が表示されるので以下内容を入力して[終了]を押下します。
winnerカラムは、集計をグループ化(Group by)
victory_statusカラムは、集計を グループ化(Group by)
[別の列を追加] を押下し、行を追加し
新たなwinnerカラムは集計 Count で新しい列名は winner_count と入力
参考:
下にプレビューの結果が表示されるので想定通りの結果となっているか確認しながら作業ができます。
グループタイプの選択では、指定の処理結果を新しいテーブルとしてて作成するか、既存のテーブルに列として追加するかを選択が可能です。

グルーピングの処理が適用され、先程のプレビュー通りの結果が表示されます。 右ペインを確認すると フィルタが2つ、グループ化が1つと3ステップのレシピが適用されていることが確認出来ます。
レシピの公開
右ペイン(レシピペイン)の発行(publish)を押下すると以下画面となり、画面下の「レシピのステップ」にこれまで作業し作成してきたフィルタやグルーピング処理があることが確認出来ます。
バージョンの説明欄にバージョンの説明に First version of my recipe と入力し、[発行] を押下します。

Step3. さらに変換を追加する
ここではレシピにさらに変換を追加し、別のバージョンのレシピとして公開していきます。
drawの除外
チェスというゲームは、必ず勝敗がつくわけではなく引き分け(draw)が存在するため、今回はdrawを除外します。
・変換ツールバーで、[フィルター]->[ 条件別]->[でない(is not)]を選択します。
右ペインで ソース列: victory_status
フィルタ条件– でない(is not) で 値に draw を選択し、[適用]を押下します。


指定通り victory_status から draw の内容がフィルタされ消えている事が確認出来ます。

victory_statusの値を分かりやすい内容に置換
victory_statusの値を意味がわかりやすいものになるようにデータの値を変更します。 今回は mate -> checkmate に文字列を置換します。
これを行うには、変換ツールバーから[クリーン]->[ 置換]->[値またはパターンを置換]を選択します。
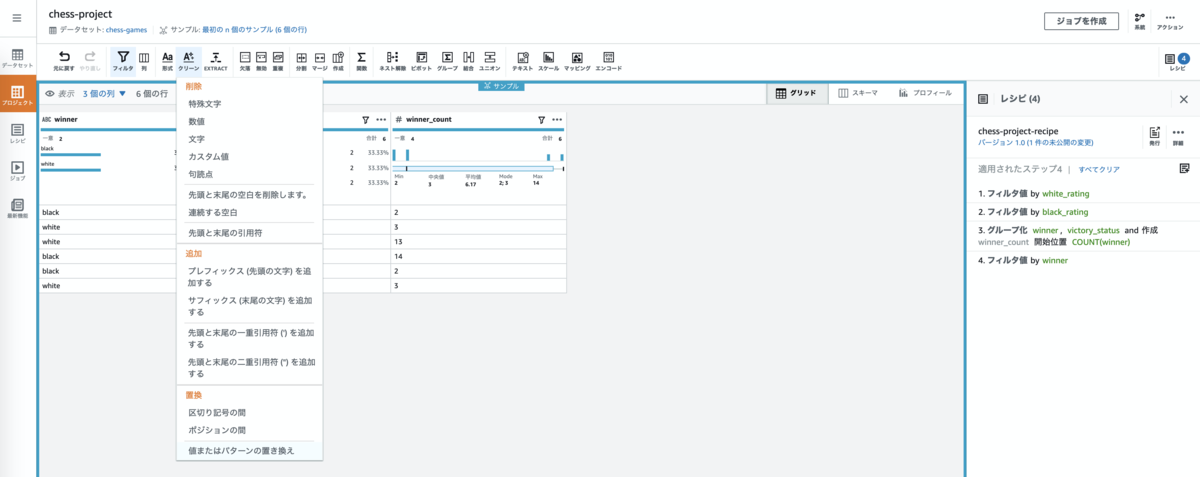
右ペインに値を置換するための項目が表示されるので以下の通り指定して、[適用]を押下します。
ソース列: victory_status
置き換える値を指定します: 値またはパターン のラジオボタンを選択
置き換える値: カスタム値の入力 のラジオボタンを選択し
元の値 mate と入力
置き換える値に checkmate と入力
変換の適用: すべての行 のラジオボタンを選択

想定通りvictory_statusカラムの値が checkmate となっていることを確認します。

上と同様の手順で victory_statusの値を
resign -> other player resigned に
outoftime -> time ran out に
それぞれ文字列を置換する処理(レシピのステップ)を追加します。
異なるバージョンとして公開する
右ペイン(レシピペイン)の発行(publish)を押下すると以下画面となりますので 今回は Step 3: Add more transformations と入力し、[発行] を押下します

Step4. DataBrewリソースを確認する
ここまでサンプルのプロジェクトで作業し、作成してきたDataBrewのリソースの内容を確認していきます。 (このステップは文字通りオペレーションは参照のみとなります)
(1). データセットの確認
左ナビゲーションペインの [データセット] を選択すると 利用しているデータファイルが確認できます。今回のサンプルでは Amazon S3に保存された Microsoft Excelのファイル chess-games.xlsx が確認できます。

(2). プロジェクトの確認
左ナビゲーションペインの [プロジェクト]を選択すると、前のstepで作業した「chess-project」の内容が表示され確認出来ます。

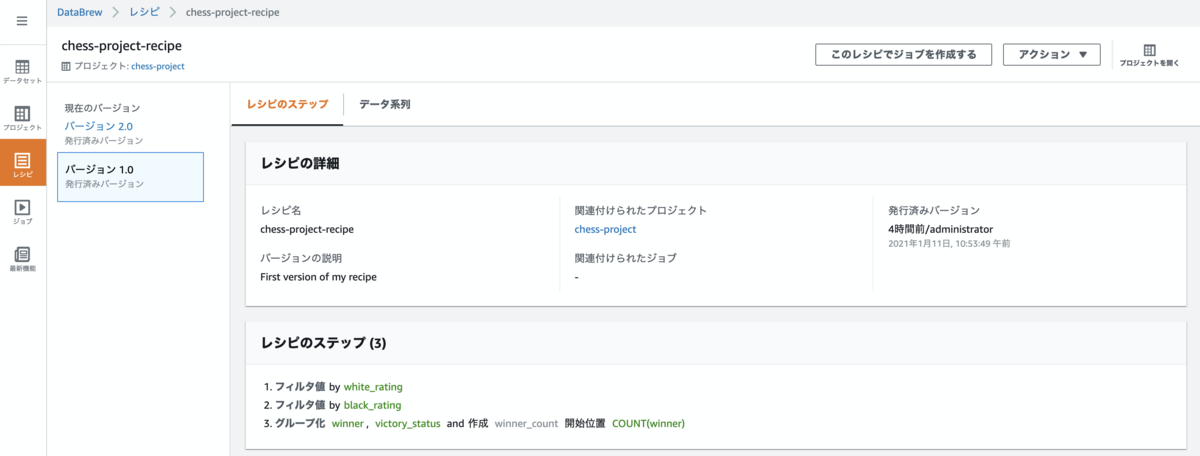
(3). レシピの確認
左ナビゲーションペインで、[レシピ] を選択するとDataBrewが作成した存在するレシピが確認出来ます。
画面に表示されている通り、バージョンの説明にStep3の内容が確認でき、バージョン2.0の内容が表示されていることがわかります。

(4). レシピのバージョン確認
表示さているレシピ名のリンクを押下すると(レシピのステップタブ)でレシピの詳細やステップが確認出来ます。
左ペインのバージョンを選択する事で過去のバージョンの内容も確認出来ます。

(5). レシピのデータ系統の確認
データ系統タブを選択すると、アイコンつきで画面のようなフローが確認出来ます。 アイコンを押下する事でその処理の詳細表示がされ、そのまま編集画面にアクセスが可能です。

(例) プロジェクトを選択すると、以下のようにプロジェクト詳細が表示され [プロジェクトを開く] のボタンから開く事が可能
このように処理のフロー図から内容を確認しつつ、編集にすぐ取りかかれるので便利ですね。

Cloudtrailログのタブを開くとそのレシピに関するアクティビティを追うことができます。 画面の通り、デフォルトで対象リソースとレシピがフィルタ条件で指定された状態となっているだけなので、お好みでフィルタ条件も見直せます。

Step5. データプロファイルを作成する
データセットをプロファイリングするにはジョブを作成する必要があります。
左ナビゲーションペインから [ジョブ]を選択し、[ジョブを作成] を押下します。
chess-data-profile

ジョブを作成画面にが表示されるので、 [ジョブを作成し実行する] を押下します。
(すぐに実行したくない場合は [ジョブを作成] を選択)
ジョブ名: chess-data-profile
ジョブタイプ: プロファイルジョブの作成 のラジオボタンを選択
データセットの選択: chess-games を選択
S3の場所: 作成したS3バケットの databrew-output を指定
ロール名: AwsGlueDataBrewDataAccessRole を選択

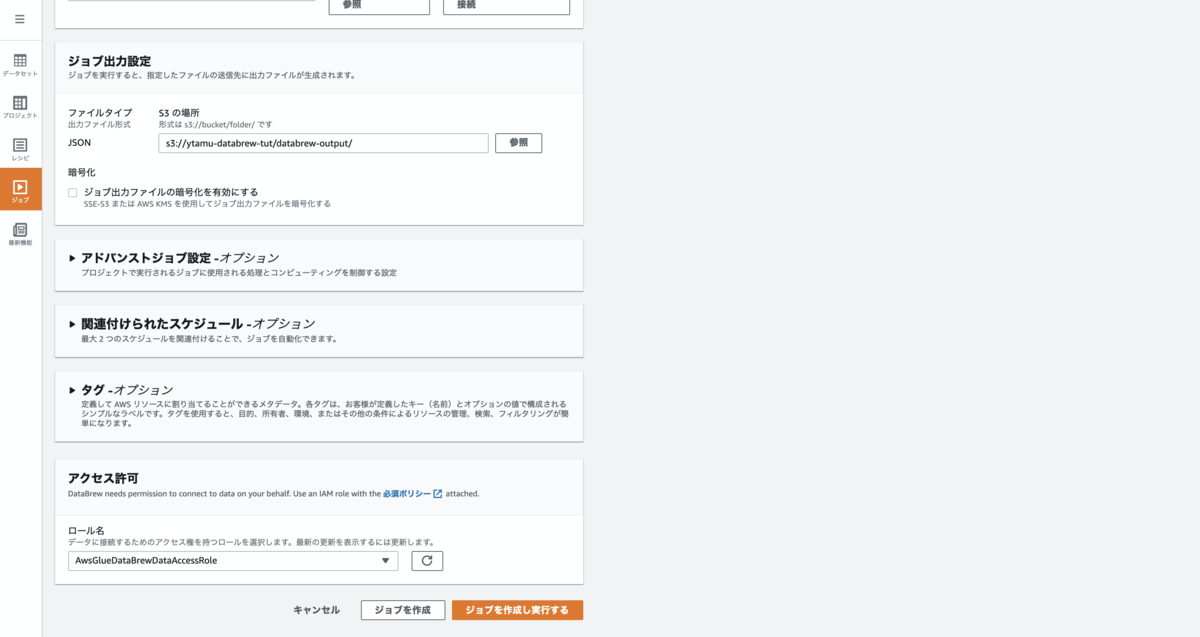
(参考) ジョブ出力設定の、Amazon S3のURIは[参照] ボタンからグラフィカルに指定も可能です。

ジョブ実行が始まります。

ジョブが正常終了すると、以下のように 成功 と表示され、その隣で実行時間が確認出来ます。
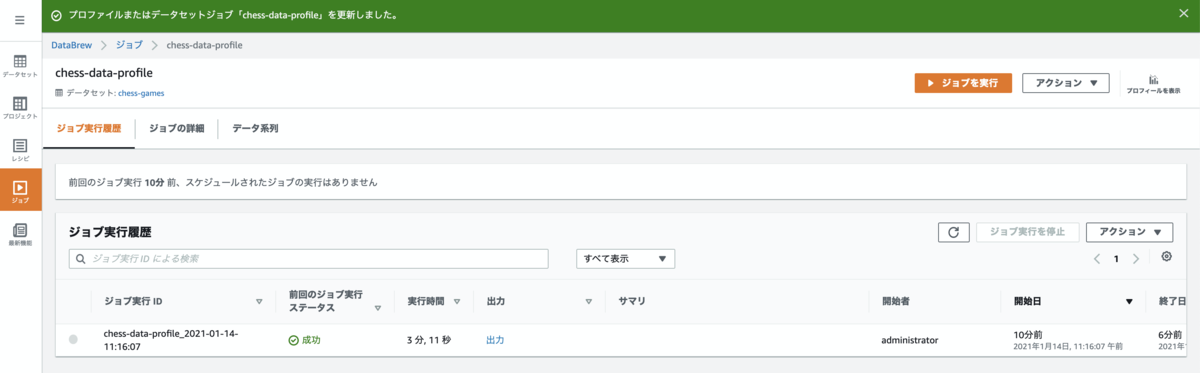
本チュートリアルでは、成功が確認できた後のオペレーションとして[データセット] の以下タブを時間をかけて調べてみてください。とあるので今回は画面キャプチャーを置いておきます。
・データセットのプレビュー
・プロファイルの概要
・列の統計
・データ系列
左ナビゲーションペインで [データセット]を選択
データセットのプレビュー

データプロファイルの概要

列の統計

データ系列

Step6. データセットを変換する
先程と同様にジョブ作成画面で作成していきます。 (先程はプロファイルジョブの作成でしたが、今回はレシピジョブの作成となります)
左ナビゲーションペインから [ジョブ]を選択し、[ジョブを作成] を押下します。
ジョブを作成画面が表示されるので、 [ジョブを作成し実行する] を押下します。
(すぐに実行したくない場合は [ジョブを作成] を選択)
ジョブ名: chess-winner-summary
ジョブタイプ: レシピジョブを作成 のラジオボタンを選択
データセットの選択: chess-games を選択
レシピを選択: chess-project-recipe を選択
ファイルタイプ: CSV を選択
S3の場所: 作成したS3バケットの databrew-output を指定
ロール名: AwsGlueDataBrewDataAccessRole を選択


処理が完了したらアウトプット先に指定した S3バケットを確認します。 当チュートリアルでは以下のようなpartでわかれたファイルが5つ出力されていました。
% aws s3 ls s3://ytamu-databrew-tut/databrew-output/chess-winner-summary_14Jan2021_1610592704339/ 2021-01-14 11:52:05 70 chess-winner-summary_14Jan2021_1610592704339_part00000.csv 2021-01-14 11:52:05 55 chess-winner-summary_14Jan2021_1610592704339_part00001.csv 2021-01-14 11:52:05 95 chess-winner-summary_14Jan2021_1610592704339_part00002.csv 2021-01-14 11:52:05 55 chess-winner-summary_14Jan2021_1610592704339_part00003.csv 2021-01-14 11:52:06 60 chess-winner-summary_14Jan2021_1610592704339_part00004.csv %
中身を確認すると、1ファイル毎にカラム情報と1レコードという格納がされていました。
% cat chess-winner-summary_14Jan2021_1610592704339_part0000*.csv winner,victory_status,winner_count black,"other player resigned",1039 winner,victory_status,winner_count black,checkmate,258 winner,victory_status,winner_count black,"time ran out",149 white,"other player resigned",1063 winner,victory_status,winner_count white,checkmate,297 winner,victory_status,winner_count white,"time ran out",136 %
見ての通りビッグデータの処理向けのような形で配置されるのが標準で、ファイルの細かい出力に関する指定は現状出来ないようです。
このアウトプットを確認したらチュートリアルは終了となります。
Step7. クリーンアップ
最後に、ここまで構築した各リソースを削除していきます。
プロジェクトの削除
左ナビゲーションペインから [プロジェクト]を選択し、chess-project にチェックをし、[アクション]のプルダウンから 削除 を押下します。
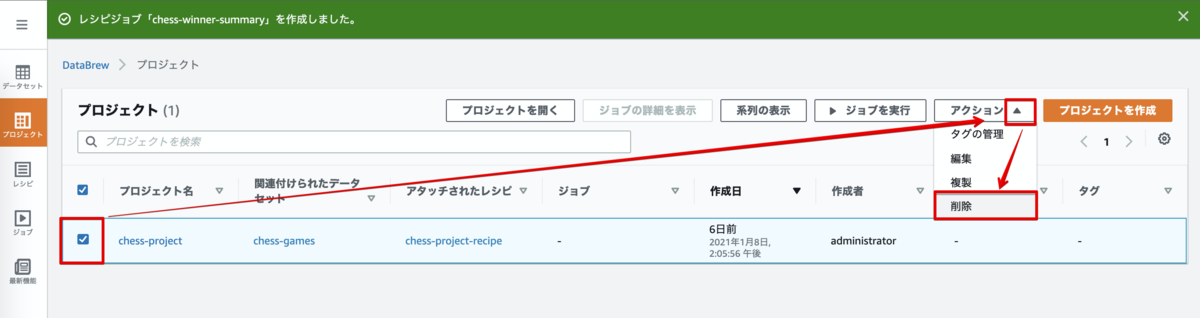
削除対象が想定通りのプロジェクトか再度確認して[削除] を押下します。 (プロジェクトにアタッチされたレシピは残したい場合は、チェックを外します)

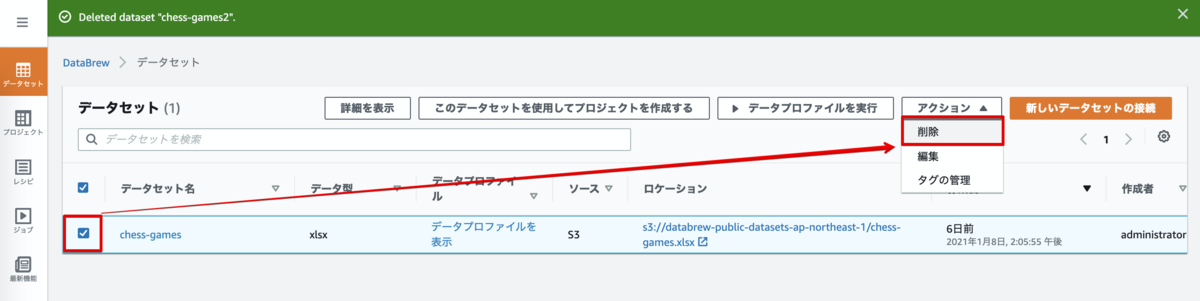
データセットの削除
次にデータセットも削除します。
左ナビゲーションペインから [データセット]を選択し、chess-games にチェックをし、[アクション]のプルダウンから 削除 を押下します。
S3バケットと作成したIAMリソースの削除
必要に応じてOutput先に指定したご自身の S3バケットやこのチュートリアルのために作成したIAMユーザーやロール等のリソースを削除します。
チュートリアルをやってみて
GUIでぽちぽちと直感的な操作で、データ前処理が簡単に行えました。
グラフィカルにフローや組み込む処理についてプレビューで確認しながら直感的に作業を進められる点が良かったです。コストもあまり気にならず短時間で学べる良いチュートリアルなので興味がある方やデータ前処理にお困りの方は是非、実際にご自身でも試してみてください。
まとめ
今後、データ前処理で困った時は使います。