

こんにちは。AWS CLIが好きな福島です。
この記事では、私が生成AIを用いたRAGシステムの構築をする中で RAGシステムのアーキテクチャは特定のコンポーネントに分解することができ、 それぞれの部分で考慮が必要な点があると感じたため、その内容を記載します。
ここで指すRAGシステムは社内のドキュメントを活用し、社内の問い合わせをLLM * RAGで効率化させるシステムを想定しております。
また、はじめの方には、RAGシステムを構築する必要性について簡単に解説しております。
RAGとは?
ご存知の方も多いかと思いますが、簡単に言うとLLMが知らないことを回答させる手法になります。 LLMが知らないこととは、最新の情報であったり、企業などにおける固有情報になります。
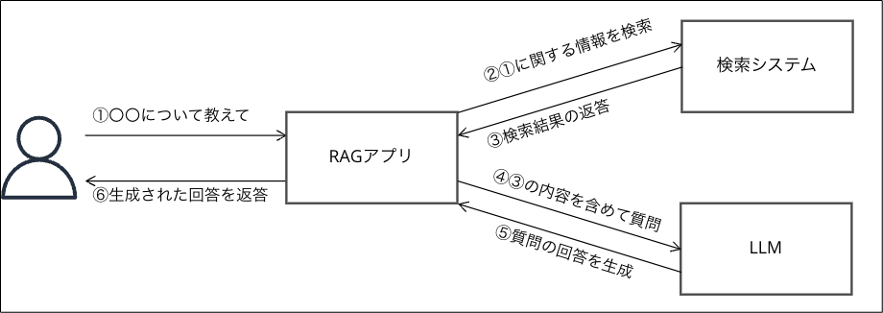
手法についてもう少し具体的に解説するとLLMへの質問に参考情報を含めて質問するイメージです。
RAGのイメージ
以下は弊社代表のことを質問しています。
- RAGを利用しない場合
弊社のHPなどで代表の名前はインターネットに公開されているため、LLMが学習している可能性もありましたが、 残念ながらClaudeは代表の名前を答えることはできませんでした。
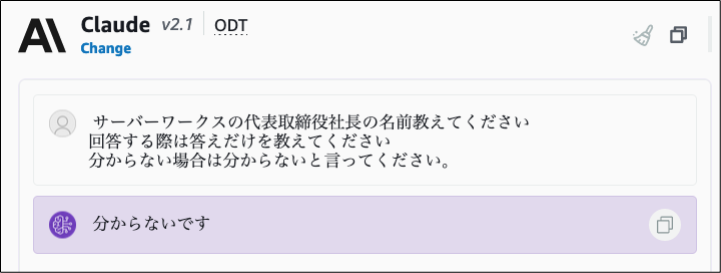
- RAGを利用した場合
RAGを利用しなかった場合は代表の名前を答えることはできませんでしたが、 以下のようなイメージで参考情報を加えて質問することで代表の名前を正しく答えることができています。
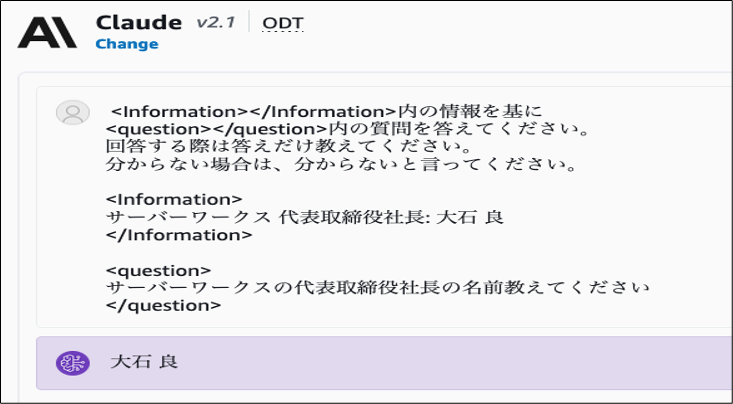
これがLLMが知らないことを回答させる手法であるRAGになります。
RAGの課題(RAGシステムの必要性)
課題
RAGのイメージを見て分かる通り、参考情報の入力が手間かと思います。 また、そもそも参考情報を知っているのであれば、質問する必要がないことがほとんどです。(情報を知らないからこそ、LLMに質問したい)
解決方法
そこで以下のようなシステムを構築することが解決策になります。
- 最新情報や固有情報を検索できるシステムの構築
- LLMへの質問を基に関連情報を検索システムから検索し、LLMへの質問に関連情報を含めるアプリ構築
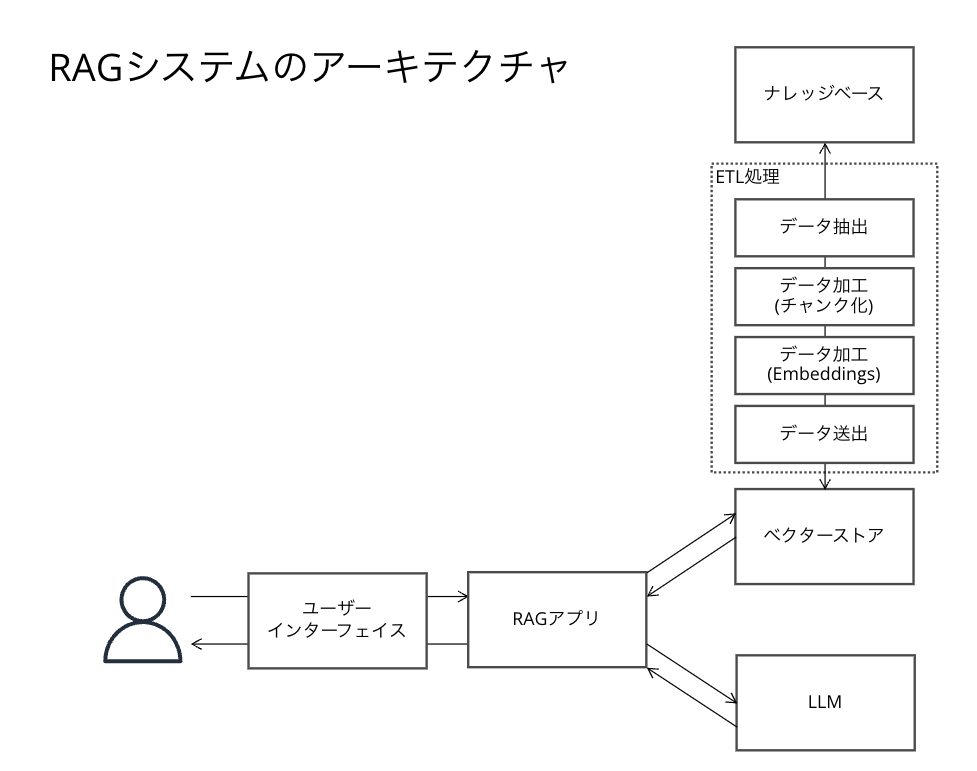
アーキテクチャ図
RAGシステムについて、RAGのイメージ図を私なりにもう少し分解した図が以下の通りです。 検索システムでは一般的にベクトル検索が使われることが多いため、それを前提に記載しています。
アーキテクチャの各要素について
ここからアーキテクチャの各要素について、まとめていきたいと思います。
①ユーザーインターフェイス
まずは、ユーザーがLLMに質問するためのインターフェイスについてです。
ここでは、独自のUIを構築するのか、SlackやTeamsなどのチャットに組み込むのかを検討する必要があると考えます。
独自のUIを構築する場合
当たり前ですが、独自のUIを構築するためコストや時間がかかる反面、UIのカスタマイズなど柔軟性がある点がメリットかと思います。
- 実装例
フロントエンドの開発経験がない場合は、ローコードでWebアプリを構築できるStreamlitを選択肢として考えられます。 ただし、手軽にフロントを構築できる反面、サーバーサイドで動くため、AWSであればECSなどを使う必要があります。 そうなると、利用者が増えた際にリソースを追加する必要があり、ランニングコストが高くなることが想定される点は注意が必要です。
フロントエンドの開発経験がある場合は、Reactなどを使うことができるかと思います。 Reactは、主にクライアントサイドで実行されるJavaScriptライブラリであるため、利用者が増えてもランニングコストは高くなりにくいです。
SlackやTeamsなどのチャットに組み込む
SlackやTeamsなどのチャットがある場合は、フロントを作る必要がないかつ RAGシステムのために認証機能も考慮する必要がなくなる点がメリットかと思います。
ただ、AWSのサンプルアプリのようにRAG以外の機能を実装する場合は独自のUIがあったほうが便利かもしれません。
引用: https://github.com/aws-samples/generative-ai-use-cases-jp/blob/main/imgs/sc_lp.png
{kind=link}
また社内のドキュメントに関する「認可」を考慮する場合は、チャットでどう認可を実現するのかは検討が必要になると思います。
②ナレッジベース
続いてナレッジベースについてです。 ナレッジベースは今回の例では、社内のドキュメントを格納している場所になります。
ファイルサーバ、データベースサーバ、Googleドライブ、Box、Microsoft OneDrive、Confluenceなどなどあらゆるものが考えられますが、どういったデータが活用できるか検討する必要があります。 また、古い情報や間違った情報があった場合は、それを基にLLMが回答してしまうため、データの整理も重要です。
③ETL処理
続いてETL処理です。 まず前提としてRAGシステムでは、ナレッジベースのデータを検索するために一般的にベクトル検索を行います。 ベクトル検索とは、簡単に言うと、意味を汲み取った検索ができる検索手法になります。 そしてベクトル検索をするためには、データをベクトル化(数値の配列)する必要があり、以下のことを検討する必要があります。
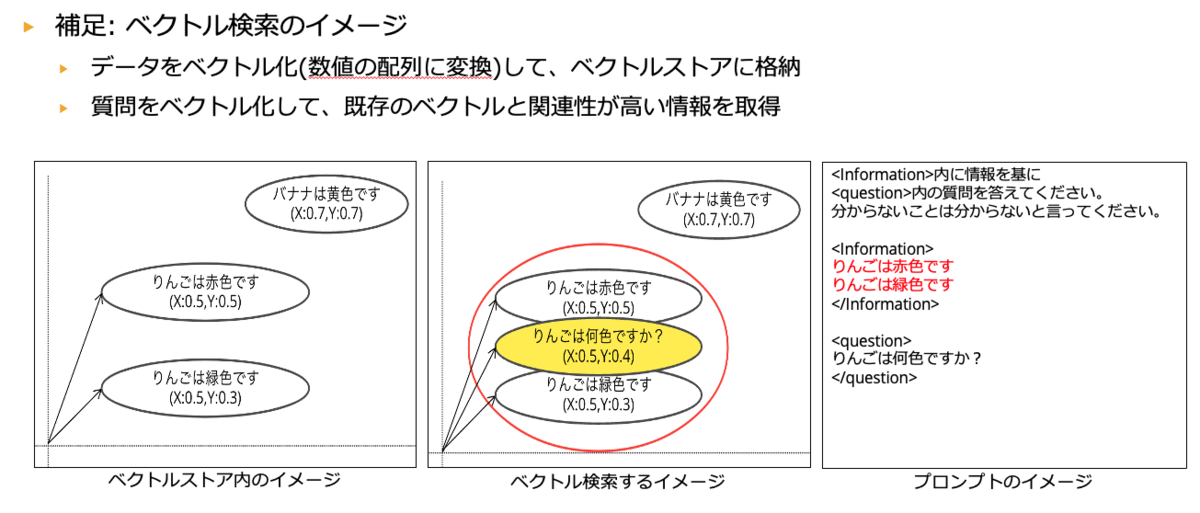
上記は二次元で表現していますが、本来はもっと高次元になります。
検討項目1
- ナレッジベースからどのようにデータを抽出するのか?
- 抽出したデータをどのようにチャンク化(分割)するのか?
- ベクターストアへどのようにデータ送出するのか?
※チャンク化は、長い文章を分割することで検索しやすい形式に分割することを指します。
対応案
対応案としては大きくマネージドサービスを利用するのか、スクラッチ開発するのかに分かれるかと思います。
マネージドサービスを利用する場合、AWSであれば、Amazon KendraもしくはKnowledge Bases for Amazon Bedrockが考えられます。
スクラッチ開発する場合は、基本的にはLLMのアプリ開発に役立つフレームワークであるLangChainを利用することになるかと思います。
検討項目2(Amazon Kendraの場合検討不要)
- チャンク化したデータをどのEmbeddingモデルを利用して埋め込むか?
Amazon Bedrockを利用する場合は、以下のモデルが考えられます。 テキストに加え画像も埋め込みたい場合は、マルチモーダルなモデルを利用し、 テキストのみの場合は、通常のモデルを利用することになるかと思います。
・cohere.embed-multilingual-v3
・amazon.titan-embed-g1-text-02
・amazon.titan-embed-text-v1
私の見解では、ETL処理の必要性を考慮する必要がないAmazon Kendraの使用が適していると考えます。 Amazon Kendraは、初期のRAGシステムの導入において非常に便利です。 ただし、Amazon Kendraの利用には、月額$810からの料金が発生するため、コスト面には注意が必要です。 さらに、RAGシステムの精度を向上させるためには、将来的に別のサービスの利用を検討する可能性もあります。
しかし、初期段階での利便性とETL処理の省略を考慮すると、Amazon Kendraの利用は良い選択だと思います。
④ベクターストア
ベクターストアとは、ETL処理で加工(ベクトル化)したデータをロードする場所になりますが、 このロード先をどうするのか検討する必要があります。
AWSであれば以下のサービスを利用することが考えられます。
- Amazon Kendra
- Amazon RDS / Aurora for PostgreSQL
- Vector engine for OpenSearch Service Serverless など
※Amazon Kendraはベクターストアと呼べるか不明ですが、ベクターストアと同じ役割をするという意味で記載しています。
個人的には③ETL処理の考慮が不要になるKendraを利用するのが良いと考えますが、 前述した通り、月額の利用料が$810~発生する点は注意かつRAGシステムの精度を向上させるためには、 将来的に別のサービスの利用を検討する可能性もあります。
⑤LLM
LLMとしてどのモデルを利用するのか検討する必要があります。
Amazon Bedrockを利用する場合は、複数のモデルがありますが、 日本語をサポートしているClaudeを利用するのが有力かと思います。
また、性能を考えるとClaude2.1が有力ですが、速度とコストを考えClaude Instantも選択肢に入ると考えております。
⑥RAGアプリ
RAGアプリは、RAGで必要な以下のような処理を実装する必要があります。
- ユーザーインターフェイスからの質問を受け取る
- 会話履歴を踏まえた質問に言い換える質問をLLMに行う
- 言い換えた質問を基にベクターストアに検索する
- ベクターストアの検索結果を基にLLMに質問する
- 生成された回答をユーザーに返す
こういったタスクを実装するためには、LangChainを利用することになるかと思います。
補足
最後に上記要素をベースにAWSサービスにRAGシステムを組む場合のそれぞれの構成のカバー範囲を以下の載せておきます。
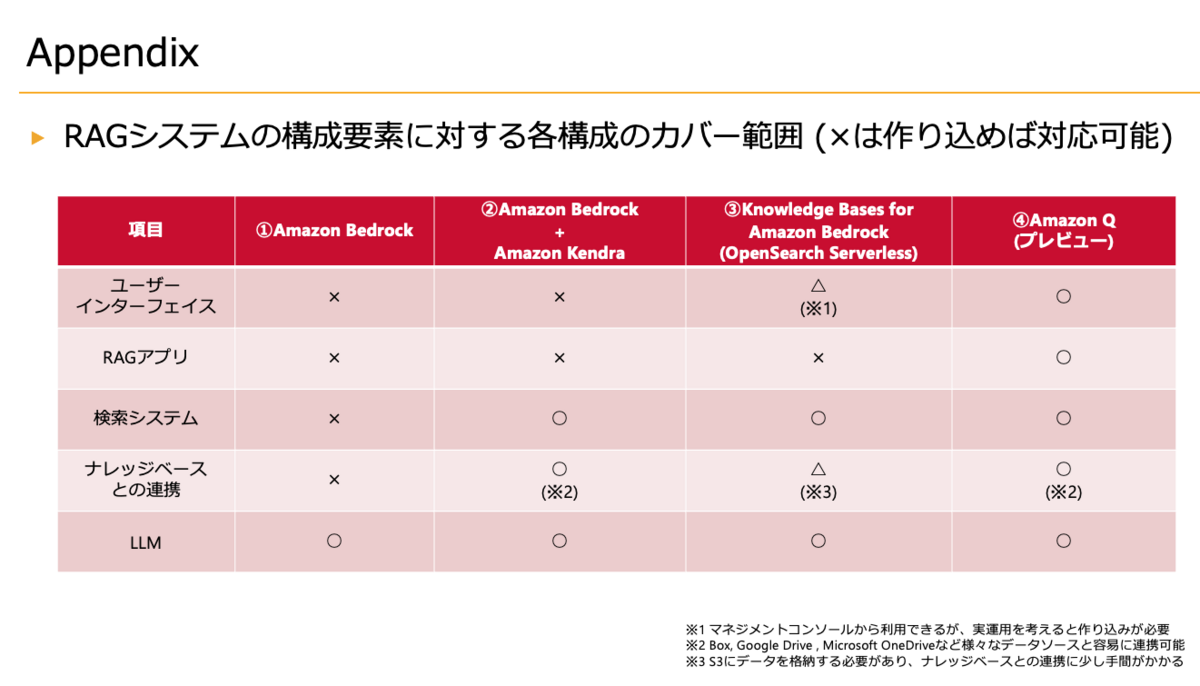
プレビュー中ですが、Amazon Qの凄さが伝わるかなと思います。 ただし、Amazon Qはユーザーあたりの$20の課金になるため(プレビュー中のため変わる可能性はあります)、 利用者が増えた場合、コストを許容できなくなる可能性はあるかと思います。
その場合は、Amazon Bedrock * Amzon KendraやKnowledge Bases for Amazon Bedrockの利用が考えられます。
終わり
今回は私なりにRAGシステムのアーキテクチャを分解し、それぞれ考慮するべきことを簡単にまとめてみました。 どなたかのお役に立てれば幸いです。