

こんにちは😺 カスタマーサクセス部の山本です。
AWS Summit Tokyo 2024に行ってきました。
セッションのスピーカーと直接話せる場所もあり、家で動画を見るよりも発表内容を深く理解できました。同じ興味を持つ人たちとも出会えたので、モチベーションも上がりました。
1日目は張り切って9つのセッションに参加したので、帰り道には頭が熱くなっていて、夜はぐっすり眠れました。
2日目も同じように濃厚な時間でした。
- 参考:2日目のレポートの前半です。
本記事は、2日目のレポートの後半です。
セッション:Amazon Aurora の技術とイノベーションDeep dive(Level 400 : 上級者向け)by アマゾン ウェブ サービス ジャパン合同会社
本記事では、セッション「Amazon Aurora の技術とイノベーションDeep dive」の内容を、スライドの情報と共にお伝えします。
7/5 までオンデマンド配信中の URL です。※登録(無料)とログインが必要です。
japansummit.awslivestream.com
PDF の資料もあります。こちらは閲覧期限はないかもです。
スピーカーは AWS Fault Injection Service で AZ 障害を体験しよう などでおなじみの 塚本 真理さん(ソリューションアーキテクト)です。AWS Fault Injection Service も興味深いサービスです。
アジェンダ

普段あまり触れることのないグローバルデータベースやBlue/Greenデプロイメントについて詳しく知ることができて、とても嬉しいセッションでした。
また、RedshiftとのゼロETLについても初めて知り、とても勉強になりました。
前半ではグローバルデータベース部分までを記載しました。
- 参考:前半のレポートはこちらです。
後半の記事では「管理性の向上」以降について記載します。
管理性の向上
Aurora Serverless
Aurora Serverlessは予期しないトラフィック増加に強いです。
CPUやメモリを追加して、1秒以内にスケールします。
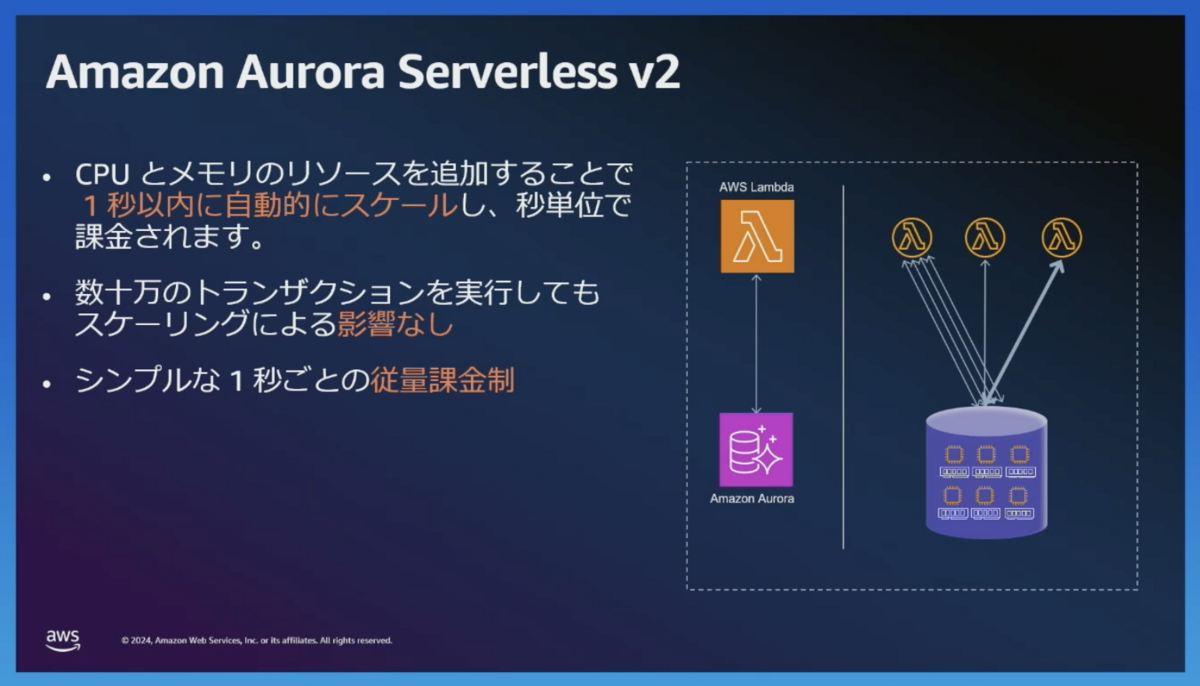
Performance Insightsを見てみましょう。
DBの負荷に応じて、Aurora ServerlessはACUを8%ずつスケールアップします。

試験的にIO待機を発生させてみます。

IO待機によりレイテンシーが上がります。
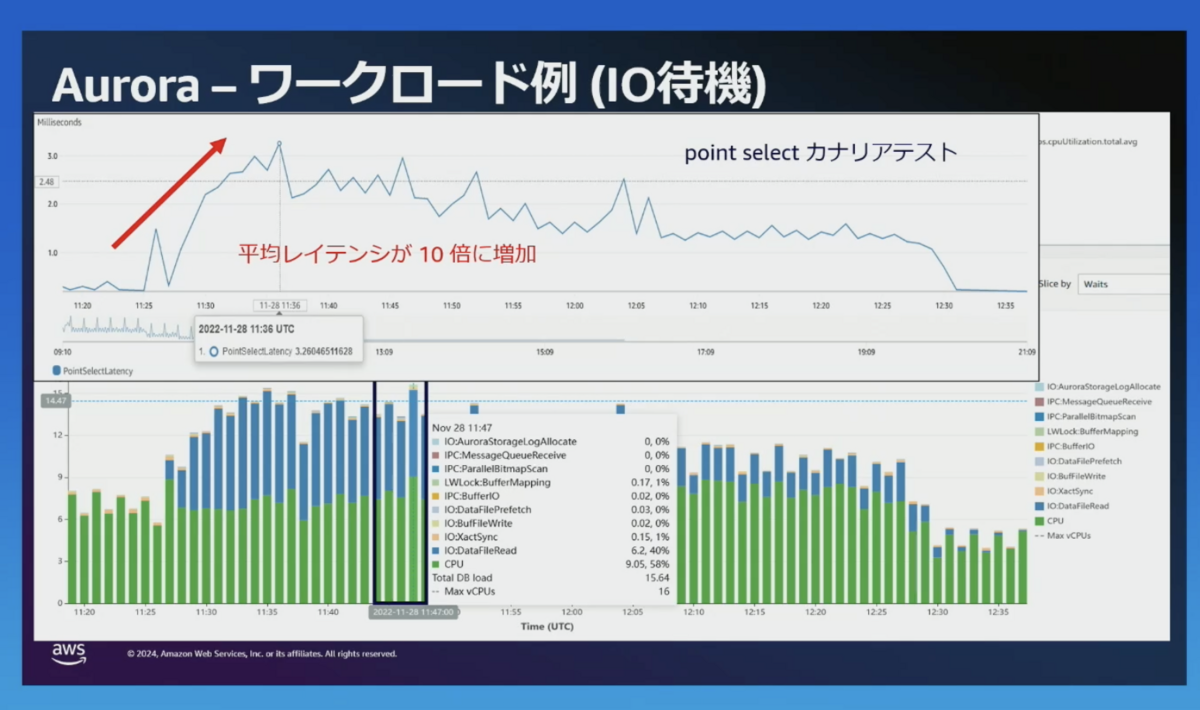
Aurora ServerlessではCPUとメモリが自動的に追加されます。(スケールインのタイミングでCPU使用率が上がっているのも興味深いです。ピンクの矢印部分です。)

Aurora Serverlessではレイテンシーを8分の1に抑えることができました。

Aurora Managed Blue/Green deployment
データベースのバージョンアップをBlue/Greenデプロイメント機能を使って実施してみましょう。

create-blue-green-deployment を実行すると、Green環境が作成されます。
Green側のデータベースのバージョンをアップグレードし、BlueクラスターからGreenクラスターにデータをレプリケートします。

両方のステータスが Available になると、切り替えが可能です。

switchover-blue-green-deployment を実行すると、切り替えが実現します。
まず、Blue環境への書き込みを停止し、レプリケーションを実施します。
この状態は SWITCHOVER_INPROGRESS となります。

レプリケーションが完了し、Green環境に切り替わると、SWITCHOVER_COMPLETED となります。
次に、Blue環境のクラスター識別子をGreen環境の識別子に付け替えます。
これにより、ユーザーアクセスがGreen環境に流れます。

delete-blue-green-deployment を実行すると、Blue 環境を切り離します。
元の環境は新環境が安定稼働するまで保持できます。

Green 環境の正常稼働の確認後、 Blue 環境は手動で削除します。

Amazon Redshift とのゼロETL統合
オンライントランザクションのシステムをデータ分析するための基盤を考えてみましょう。
ETL処理がそれほど複雑でない場合でも、構成が複雑になりがちです。

Auroraには、Amazon RedshiftとのゼロETL統合機能があります。
これにより、単純な構成でペタバイト級のデータもニアリアルタイムに分析可能です。

新しいストレージタイプと Optimised Read
新しいストレージタイプ、Aurora I/O-Optimised
Aurora のコストのうち、25 % 以上が I/O に関するコストの場合に、有効なプランです。


月に1回変更できます。いつでも戻せます。

パフォーマンスが上がるケースもあります。

Optimised Reads
通常では、メモリが溢れた際には EBS を利用します。
EBS はメモリの2倍の領域を確保しています。

Optimised Reads ではローカルの NVMe ストレージにメモリの6倍の領域を確保しています。
大きなオブジェクトを扱える上、レイテンシーも少ないです。

Optimised Reads (I/O-Optimised 利用時)
NVMe ストレージにメモリの2倍の領域を確保しています。

残りの NVMe ストレージは、階層型キャッシュに使用します。
NVMe ストレージにメモリの4倍の領域を確保しています。
shared_buffers に 4.5 % のメタデータ領域を確保します。

shared_buffers内で期限切れになったデータは、階層型キャッシュに送られます。 shared_buffers内のメタデータを参照することで、階層型キャッシュのデータにアクセスできます。 このように、階層構造のキャッシュを構成しています。
参考:Amazon Optimized Reads による Aurora PostgreSQL のクエリパフォーマンスの向上 - Amazon Aurora
生成AIに活用できる機能 pgvector
オープンソースの pgvector 拡張は以下をサポートしています。
- 距離演算子
- <->
- ユークリッド距離(直線距離)
- <=>
- コサイン距離(角度)
- <#>
- 内積距離(相似性)
- <->
- ベクトルデータ型ストレージ
- 近傍探索用のインデックス
- IVFFLAT(Inverted File with Flat Quantization)
- HNSW(Hierarchical Navigable Small World)
- 検索
- 近似最近傍探索(Approximate Nearest Neighbor, ANN)
- K近傍法(K-NN)
- メタデータ

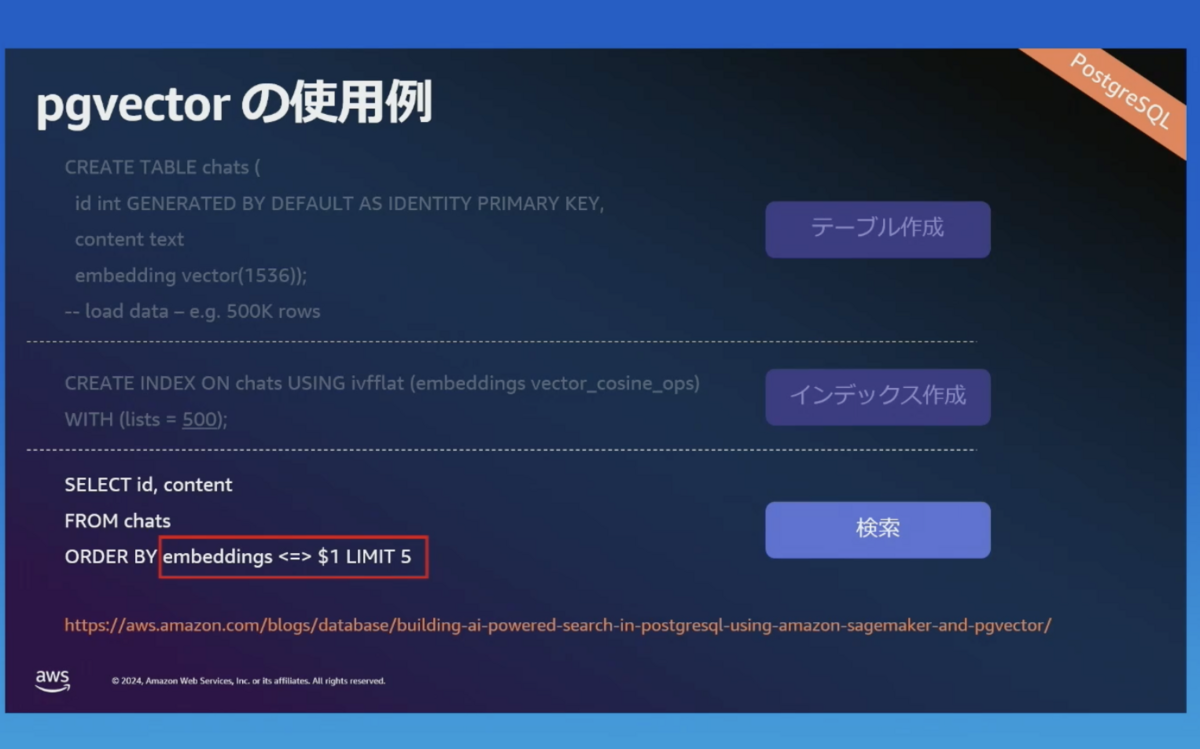
詳細については、以下の参考資料を参照してください。
参考:Building AI-powered search in PostgreSQL using Amazon SageMaker and pgvector | AWS Database Blog
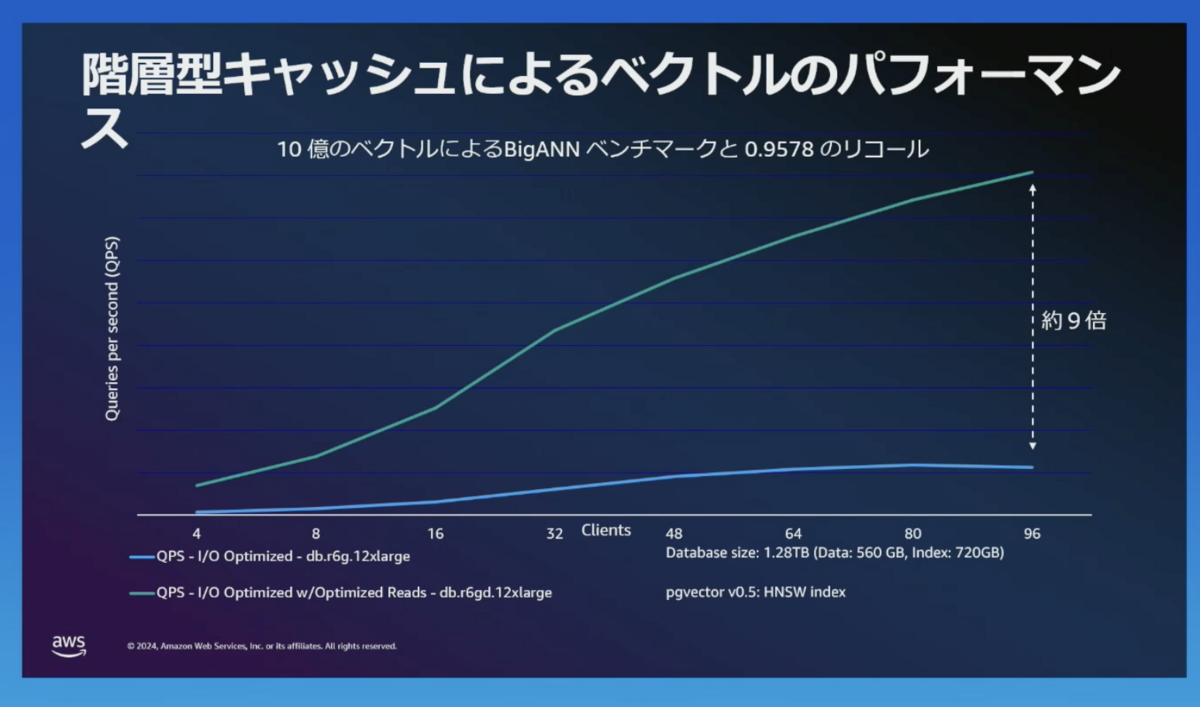
階層型キャッシュを利用して、ベクトルデータベースのパフォーマンスを上げることもできます。
まとめ
Aurora の新しい機能から、生成AI向けの機能を知ることができる素晴らしいセッションでした。
お客様への提案の幅も広がります。
試したことない機能については試してみようと思います。
余談
中央アルプススカイラインというトレイルランニングの大会に出ました。
90 km の部門(豪雨などの関係で実際には 84 km) を無事完走できました。
中央アルプスの山の大きさと景色に圧倒され、人の温かさに触れました。
山は良いですね。
