

こんにちは😺
カスタマーサクセス部の山本です。
AWS Summit Tokyo 2024に行ってきました。
セッションのスピーカーと直接話せる場所もあり、家で動画を見るよりも発表内容を深く理解できました。同じ興味を持つ人たちとも出会えたので、モチベーションも上がりました。
1日目は張り切って9つのセッションに参加したので、帰り道には頭が熱くなっていて、夜はぐっすり眠れました。
2日目も同じように濃厚な時間でした。
- 参考:2日目の後半のレポートです。
セッション:Amazon Aurora の技術とイノベーションDeep dive(Level 400 : 上級者向け)by アマゾン ウェブ サービス ジャパン合同会社
本記事では、セッション「Amazon Aurora の技術とイノベーションDeep dive」の内容を、スライドの情報と共にお伝えします。
7/5 までオンデマンド配信中の URL です。※登録(無料)とログインが必要です。
japansummit.awslivestream.com
PDF の資料もあります。こちらは閲覧期限はないかもです。
スピーカーは AWS Fault Injection Service で AZ 障害を体験しよう などでおなじみの 塚本 真理さん(ソリューションアーキテクト)です。AWS Fault Injection Service も興味深いサービスです。
アジェンダ

普段あまり触れることのないグローバルデータベースやBlue/Greenデプロイメントについて詳しく知ることができて、とても嬉しいセッションでした。
また、RedshiftとのゼロETLについても初めて知り、とても勉強になりました。
執筆時間の都合上、本記事では、前半のグローバルデータベース部分までを記載します。
後半の記事では以降の部分を記載予定です。
アーキテクチャ
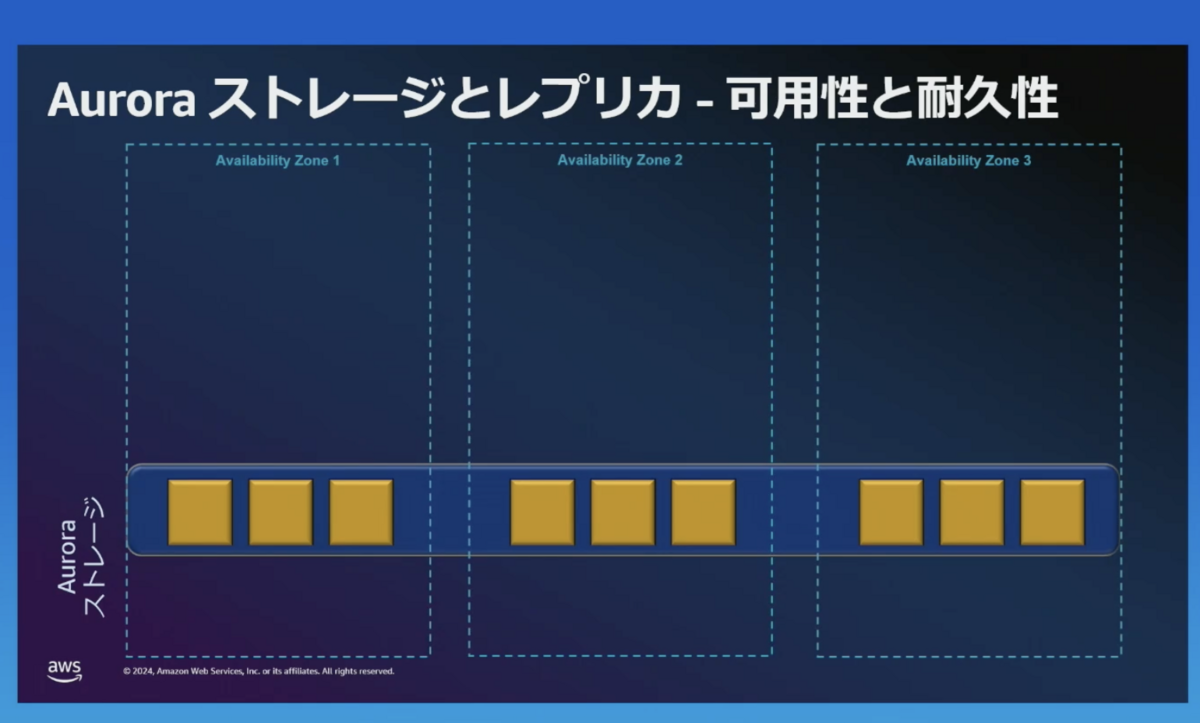
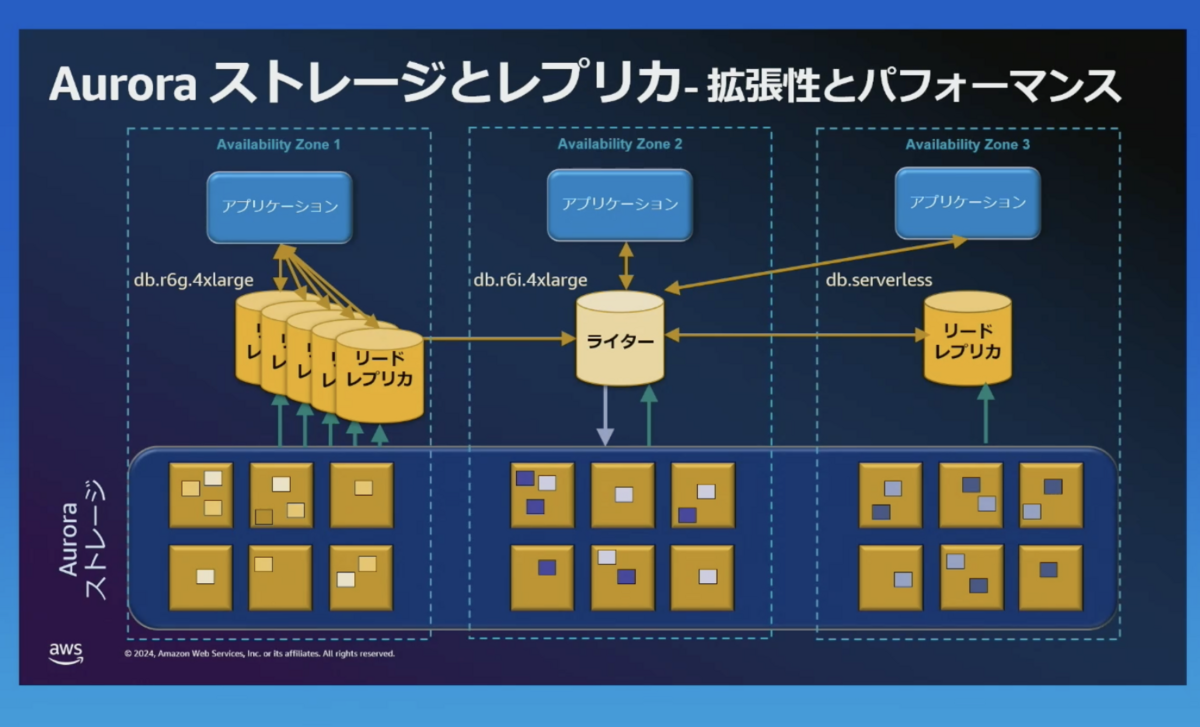
ストレージ
1つのAuroraクラスターのストレージは、3つのアベイラビリティゾーンに分散されています。
例えば、東京リージョン内の3つのデータセンター(群)に分散されています。
これにより、Auroraは耐久性と可用性が高くなっています。
ストレージへの書き込み
書き込み処理では、少なくとも2つのアベイラビリティゾーンにある6つのストレージに書き込みをします。
最低、4つのストレージに書き込み完了になると、書き込みは完了になります。
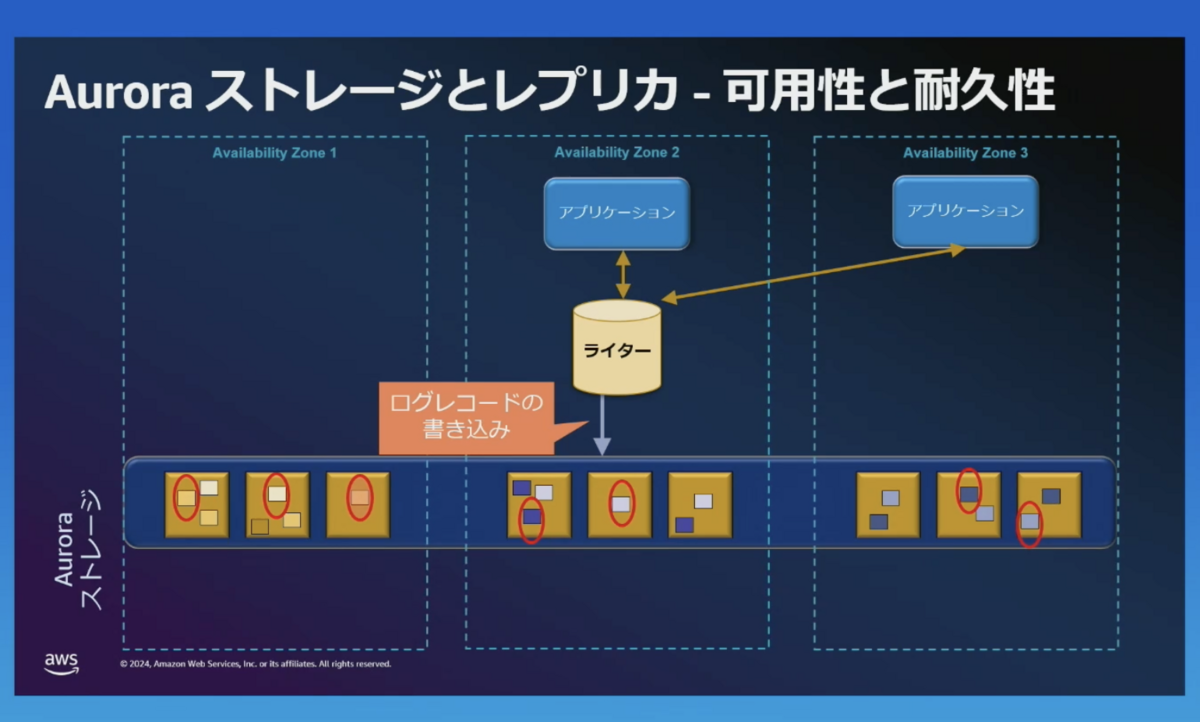
執筆者(山本)の補足:
Auroraの特長は、6つのストレージに書き込むにもかかわらず、書き込み速度が速いことです。
書き込み処理は非同期で行われ、並行して6つのストレージに書き込むため、ディスクの入出力負荷が少なくなります。
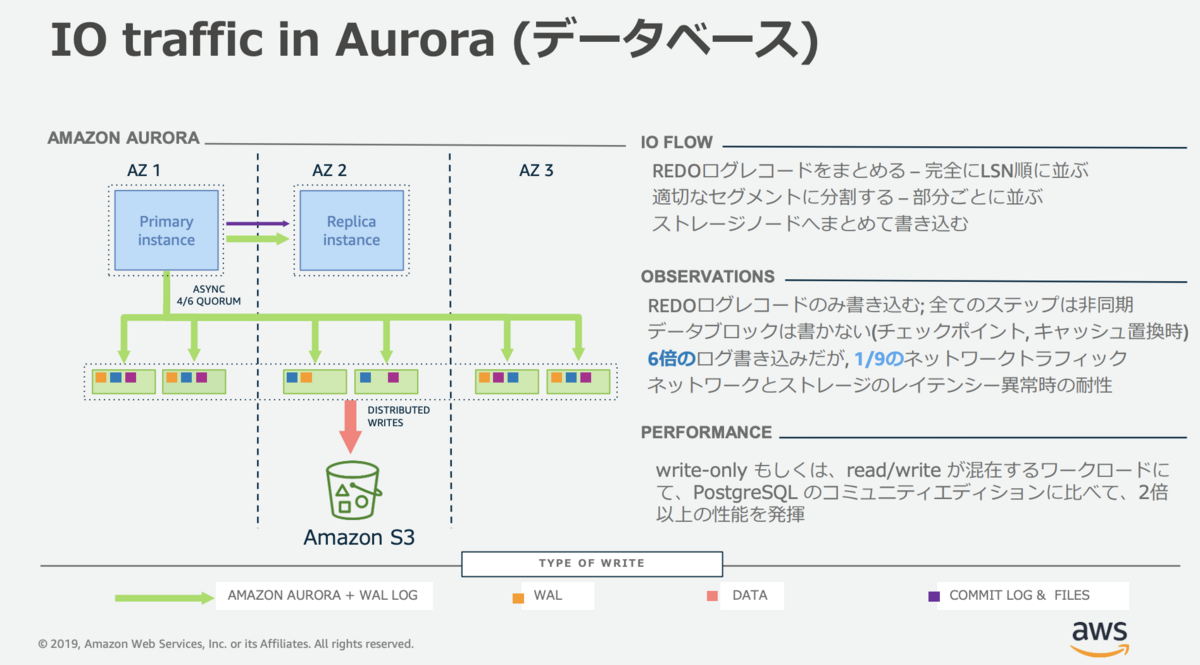
Auroraのストレージシステムは、Aurora専用に作られたログ構造の分散ストレージシステムを使用しています。
このシステムでは、ログレコードに更新差分のみが含まれるため、書き込み時のネットワークトラフィックは通常の約9分の1です。
したがって、Auroraは非常に速い書き込み速度を実現しています。
詳細については、以下の参考資料をご覧ください。
- 参考
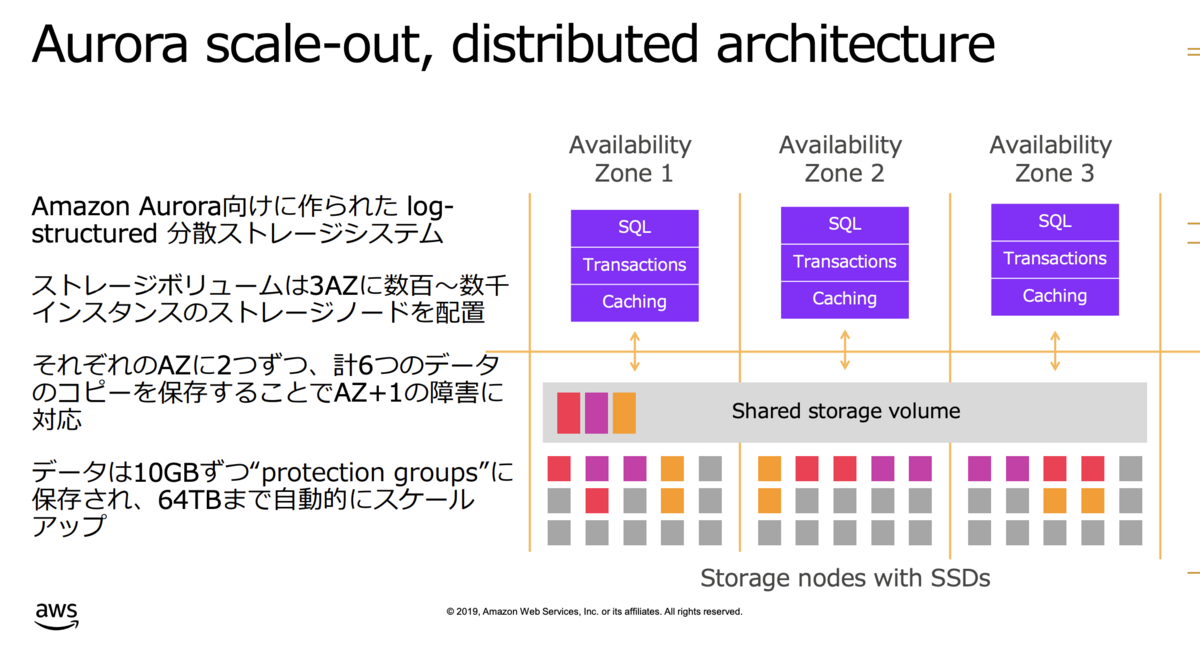
ストレージからの読み取り
Auroraでは、最大 15 個のリーダーインスタンス(読み取り専用インスタンス)を配置できます。これにより、読み取りトラフィックを複数のインスタンスに分散できます。
リーダーインスタンスは複数のアベイラビリティゾーン(AZ)に分散して配置できるため、障害時でも高い可用性を維持しながら読み取り性能を向上させます。
Auroraはデータを複数のストレージノードに分散して保存しています。これにより、読み取りリクエストも分散され、同時に複数のノードからデータを読み取ることが可能です。
また、各インスタンスごとにインスタンスタイプを選択することもできます。
フェイルオーバー
障害発生時は自動的にフェイルオーバーします。
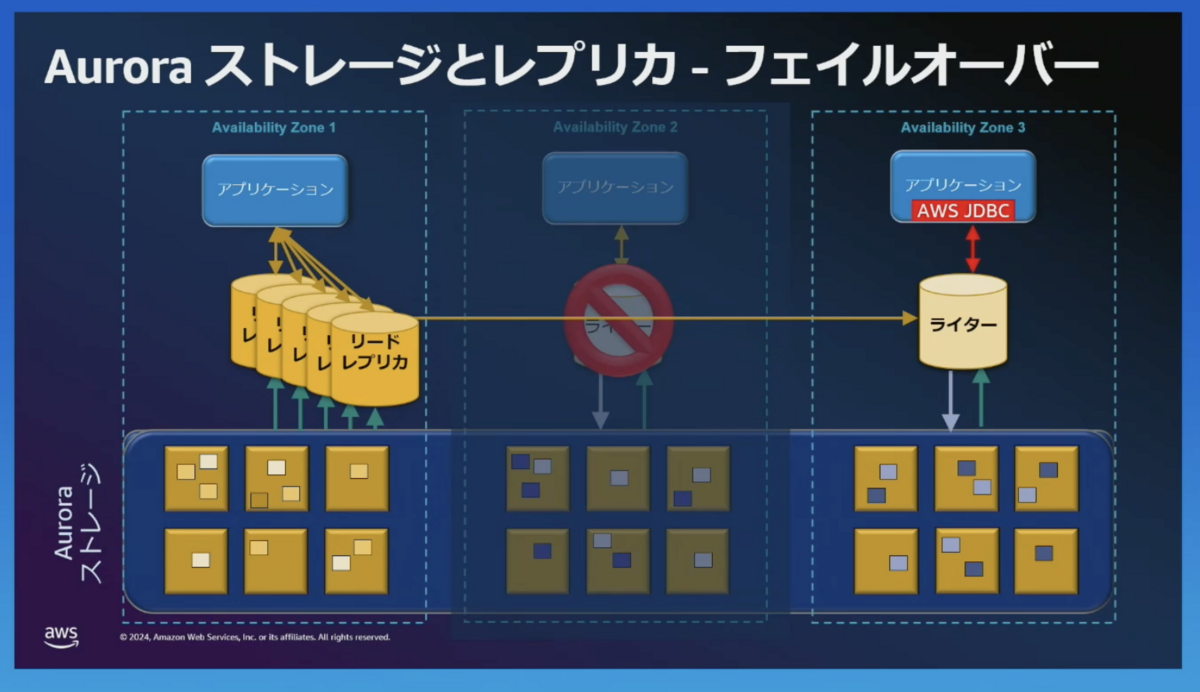
AWS JDBCドライバーは、Auroraクラスタ内のリーダーおよびライターインスタンスを自動的に検出し、最適なインスタンスに接続する機能を持っています。これにより、DNS伝搬の遅延を回避し、迅速に接続を切り替えることができます。
切り替え時間を約 66 % 短縮可能です。
- 参考
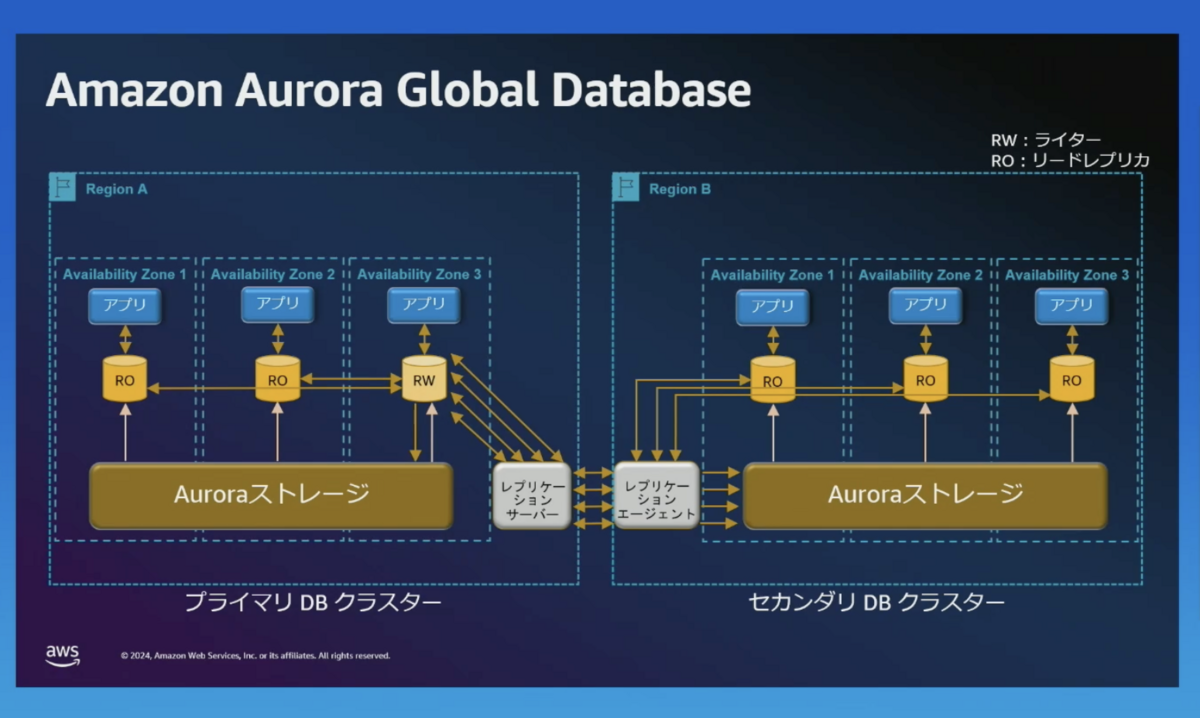
グローバルデータベース
レプリケーションサーバーやエージェントを使って、セカンダリーリージョンのクラスターにデータをレプリケートします。
災害復旧(DR)用に、セカンダリーリージョンにストレージだけを用意することもできます。また、リーダーインスタンスを用意することも可能です。
ストレージ間でデータをレプリケートするため、インスタンスの負荷が少なく、迅速な復旧が可能です。
switchover-global-cluster
- switchover-global-cluster
- 障害が発生していないときに、セカンダリーリージョンへフェイルオーバーするコマンドです。
- 災害対策訓練等で、プライマリリージョンを変更する際に使用します。
- セカンダリーリージョンへのレプリケーションの完了が行われたことを検証できるため、データロスが起きません。
RPO is 0 (no data loss) - 後述の Failover よりも時間がかかります。
- 参考:Amazon Aurora Global Database に対するスイッチオーバーの実行
switchover-global-cluster を行います。
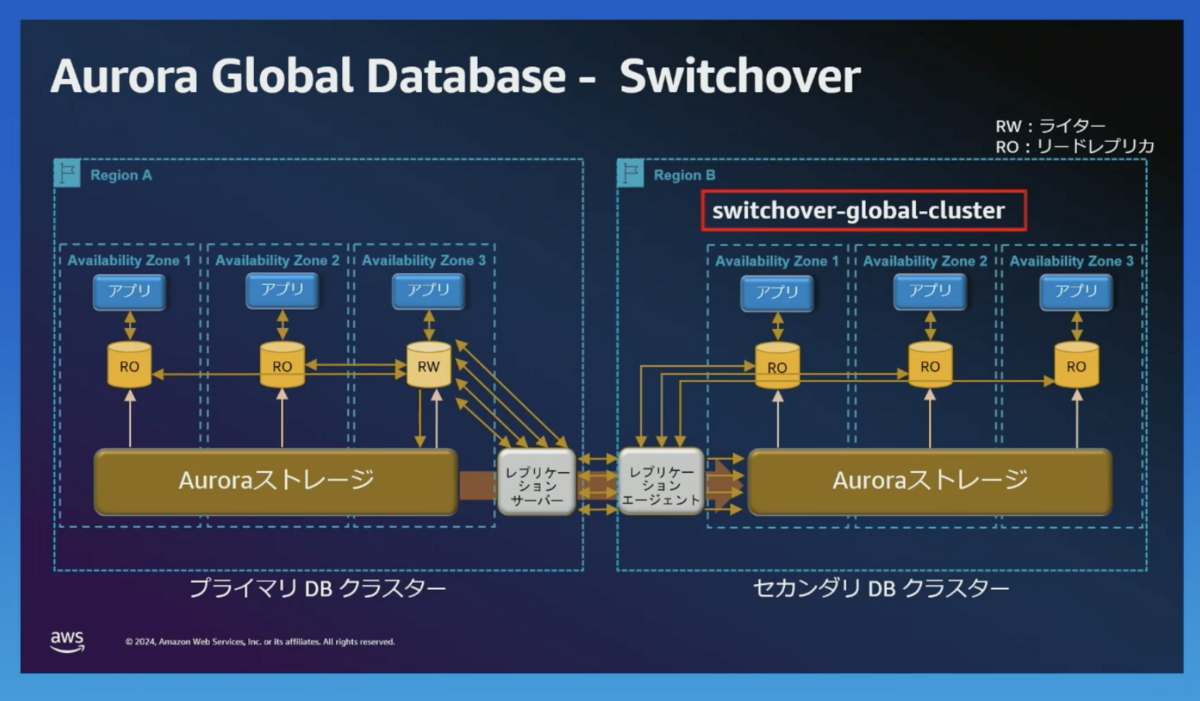
一度、プライマリのライターを読み取り専用(RO)にします。
そのあと、レプリケーション結果の検証を行います。
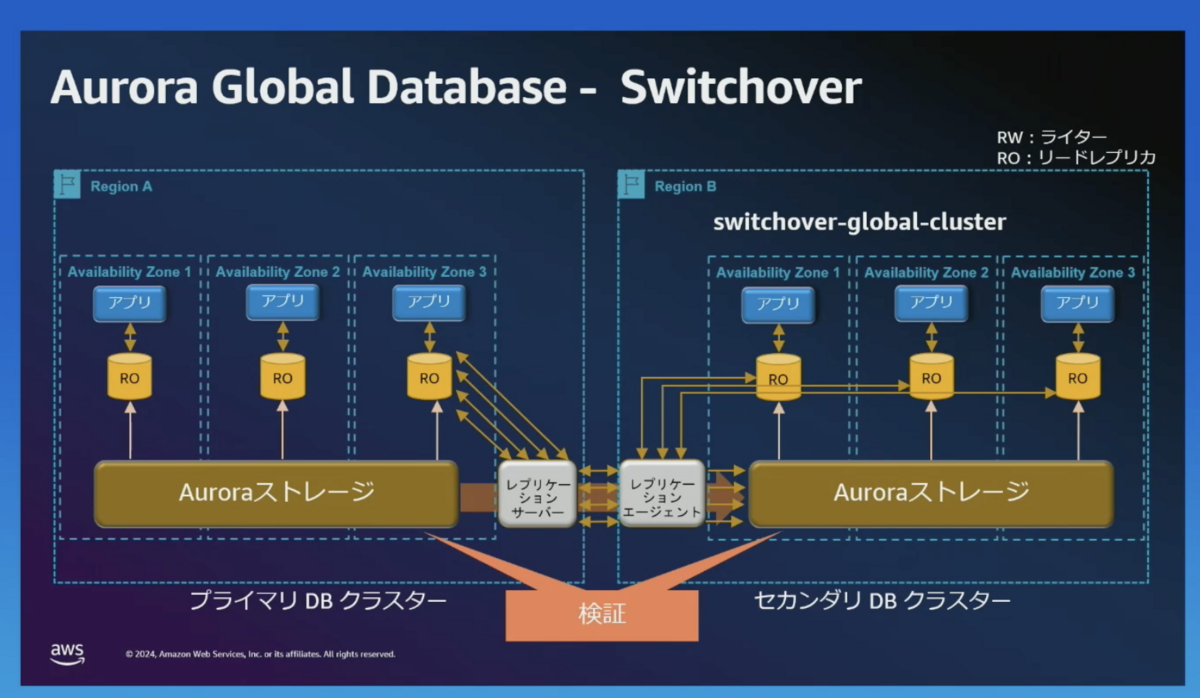
プライマリー(RW) がリージョン B に移動し、レプリケーションの方向が反対になります。
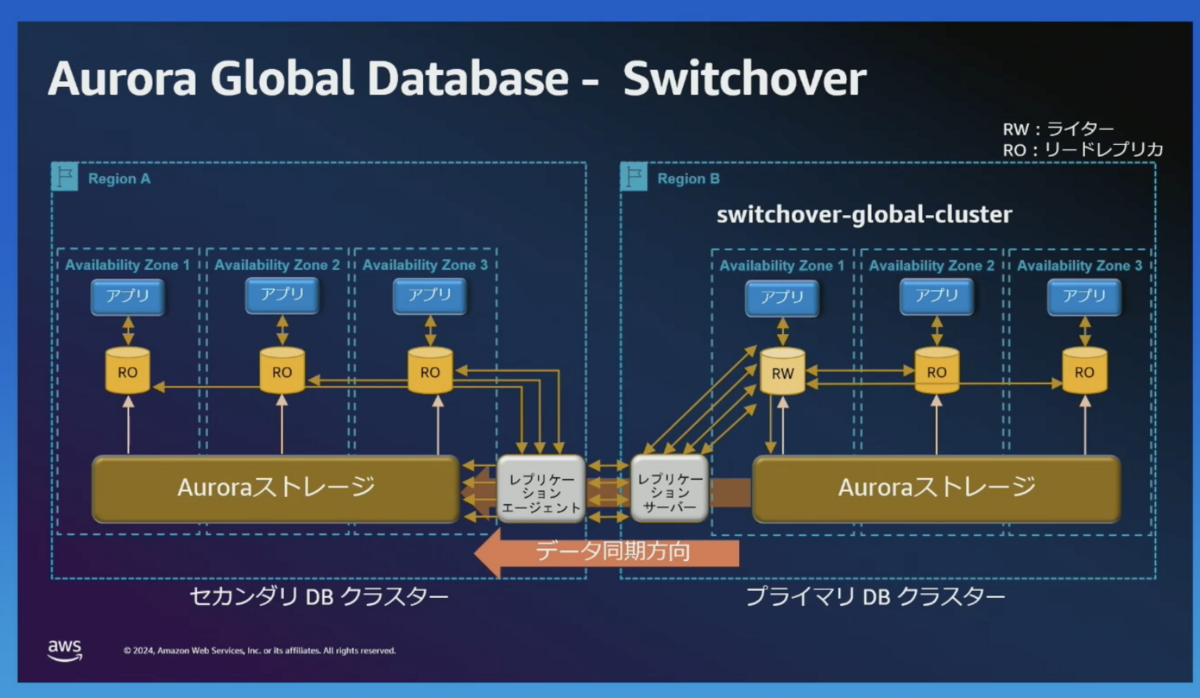
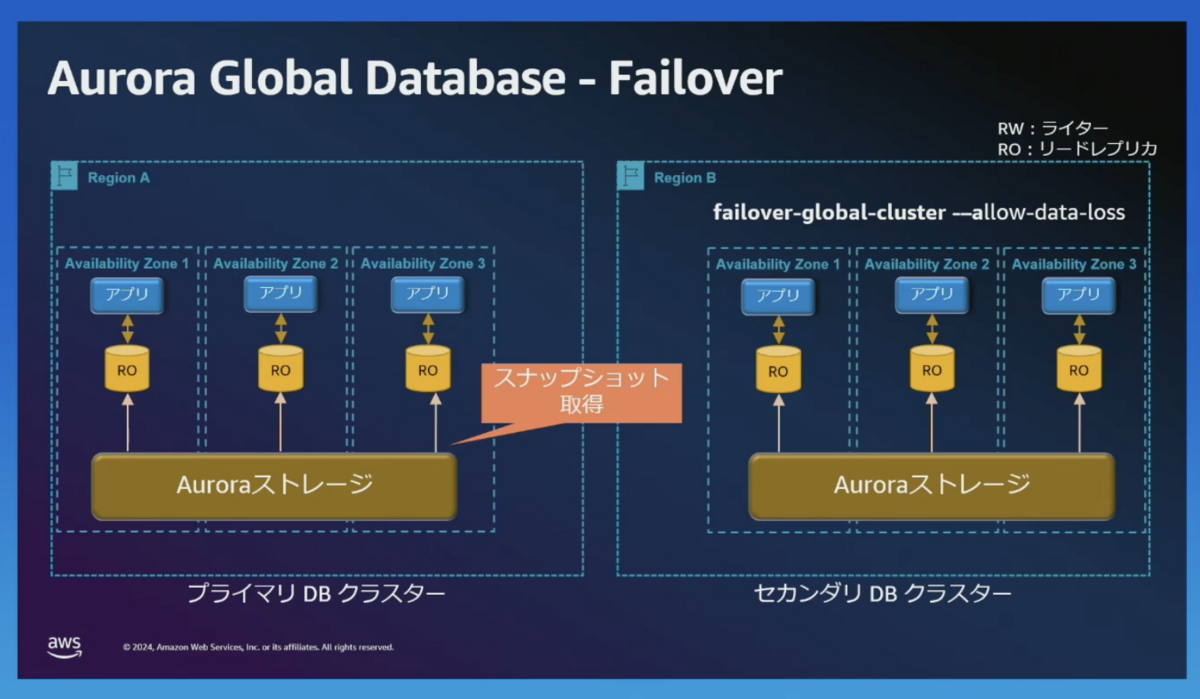
failover-global-cluster -allow-data-loss
- failover-global-cluster -allow-data-loss
- 予期しないプライマリークラスターの障害発生時に、迅速にセカンダリーリージョンへフェイルオーバーするコマンドです。
- セカンダリーリージョンへのレプリケーションを完了できないデータがあるため、データロスが発生する可能性があります。
- 短時間でフェイルオーバーできます。
- 参考:予期しない停止からの Amazon Aurora Global Database の復旧
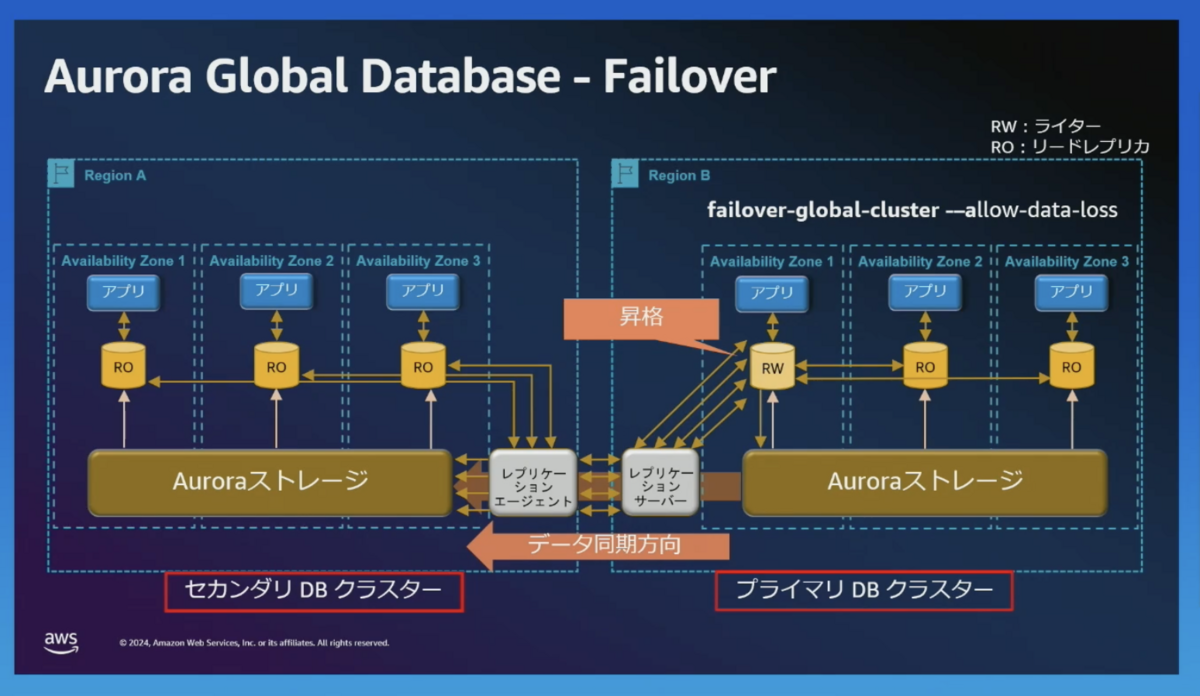
failover-global-cluster -allow-data-loss を実施します。
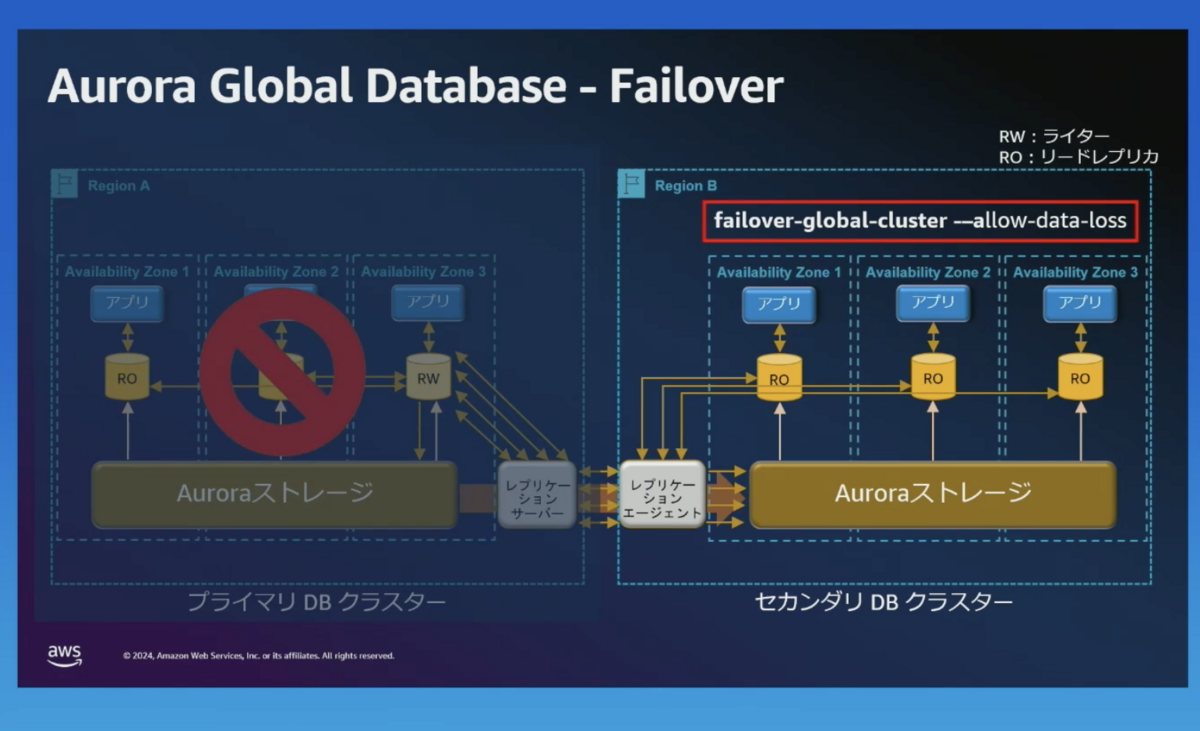
Switchover と同様に一度、プライマリのライターを読み取り専用(RO)にします。
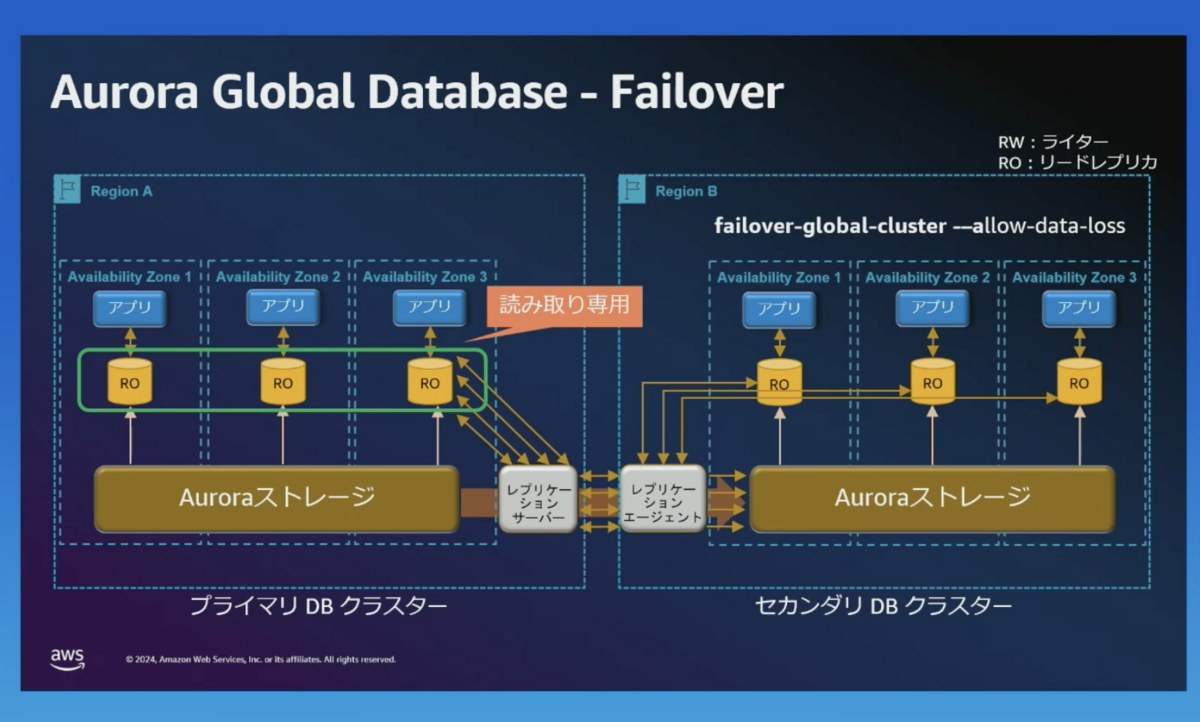
後ほどレプリケーションの差分を取り込めるように、プライマリクラスターのスナップショットを取得します。
プライマリー(RW) がリージョン B に移動し、レプリケーションの方向が反対になります。(障害の状況によっては、障害中のリージョンへのレプリケーションが失敗になったりするのだと思われます。)
Switchover と Failover の共通点
いずれのフェイルオーバーの際にも、事前にデータベースへの書き込みを止める必要があります。
データベースに書き込むアプリケーションはオフラインにする必要があります。
フェイルオーバーの実行中にはAuroraGlobalDBRPOLag や、AuroraGlobalDBReplicationLag といったメトリクスを確認して、レプリケーションの遅延状況を確認します。
Switchover の場合は遅延時間がフェイルオーバー時間となります。Failover の場合は、遅延時間分のデータロスが発生します。
Write Forwarding
セカンダリークラスターへの書き込みリクエストをプライマリークラスターに転送する仕組みです。これにより、セカンダリーリージョンのVPCにあるサーバーからプライマリークラスターに直接書き込む必要がなくなります。この Write Forwarding 機能がない場合、VPNやリージョン間VPCピアリング、Transit Gatewayなどを使ってネットワークを接続する必要があります。 転送した書き込みも、セカンダリーリージョンへレプリケーションします。
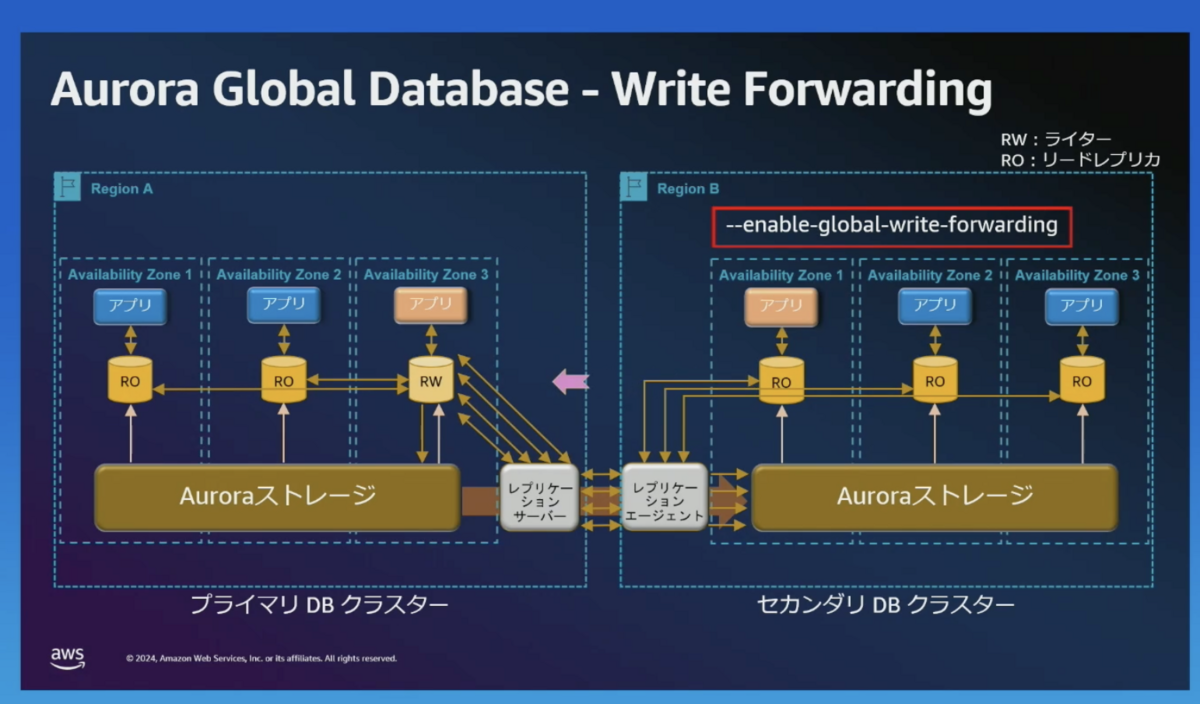
リージョン間の通信になるため、レイテンシーが多少ある点に注意です。Keep Alive のような機能はないようです。
参考:Amazon Aurora MySQL DB クラスターでのローカル書き込み転送の使用 - Amazon Aurora
まとめ
Aurora の基本的なアーキテクチャを復習でき、グローバルデータベースの仕組みを知ることができました。
セッション後の質問にも丁寧に答えていただき、良い学習機会となりました。
本記事では、前半のグローバルデータベース部分までを記載しました。
後半の記事では以降を記載予定です。
- 参考:2日目の後半のレポートです。
余談
Summit では船橋にホテルを取りました。1日目の終わりには、海浜幕張の会場付近からホテルまでランニングしました。 関東平野は空が広くて素敵ですね。夕焼けがとても綺麗でした。




翌朝、大雨の早朝にも、ずぶ濡れでランニングしたのは内緒です。(涼しくて気持ちよかったです。)