

クラウドインテグレーション部 柿﨑です。
最近はダイエット目的で始めたバドミントンが楽しくて仕方ありません!!
一緒にやってくれる方を絶賛募集中です。
今回は初めてSIEM on Amazon OpenSearch Serviceを触りましたので、備忘録として残します。
概要
SIEM on Amazon OpenSearch Serviceではどういうことができるのか、導入に関する情報、実際に触ってみた感想などを書いていきます。
詳細につきましてはSIEM on Amazon OpenSearch Serviceをご確認ください。
前提
- 本リソースの作成時期は
2021年10月です - OpenSearchのバージョンは
OpenSearch 1.1 (最新)です
できること
主に私が触った機能のみを記載しています。
ログの取り込み
最初からAWSの主要サービスのログに対応しています。
対応しているログはこちらに記載されています。
今回は以下のログを取り込みました。
| AWSサービス | 備考 |
|---|---|
| VPCフローログ | - |
| SecurityHub | - |
| GuardDuty | - |
| CloudTrail | 組織の証跡 |
| RDS | PostgreSQL, MySQL |
ログの可視化
OpenSearch Dashboardsには予めAWSサービス毎のダッシュボードが準備されています。
RDSの場合はAWSアカウント、接続元IPアドレス毎にどのようなエラーが発生しているか、などが分かります。
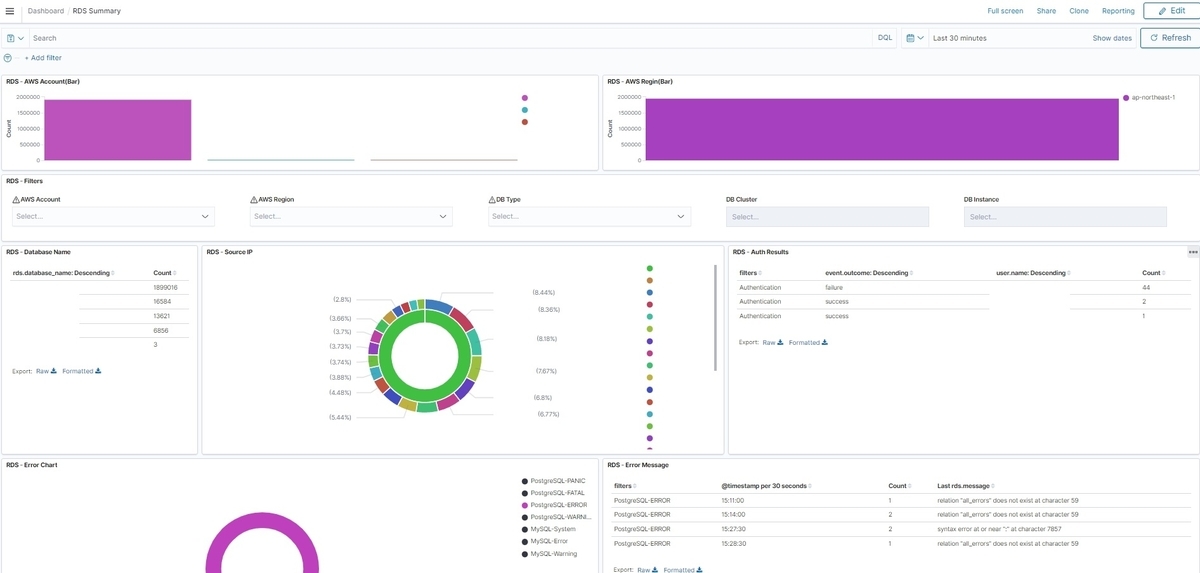
※AWSアカウント、IPアドレス、ユーザー名をマスクしています。
また、ただログを眺めるだけではなくダッシュボード上からログのフィルタリングを行い、特定のログを可視化することも可能です。
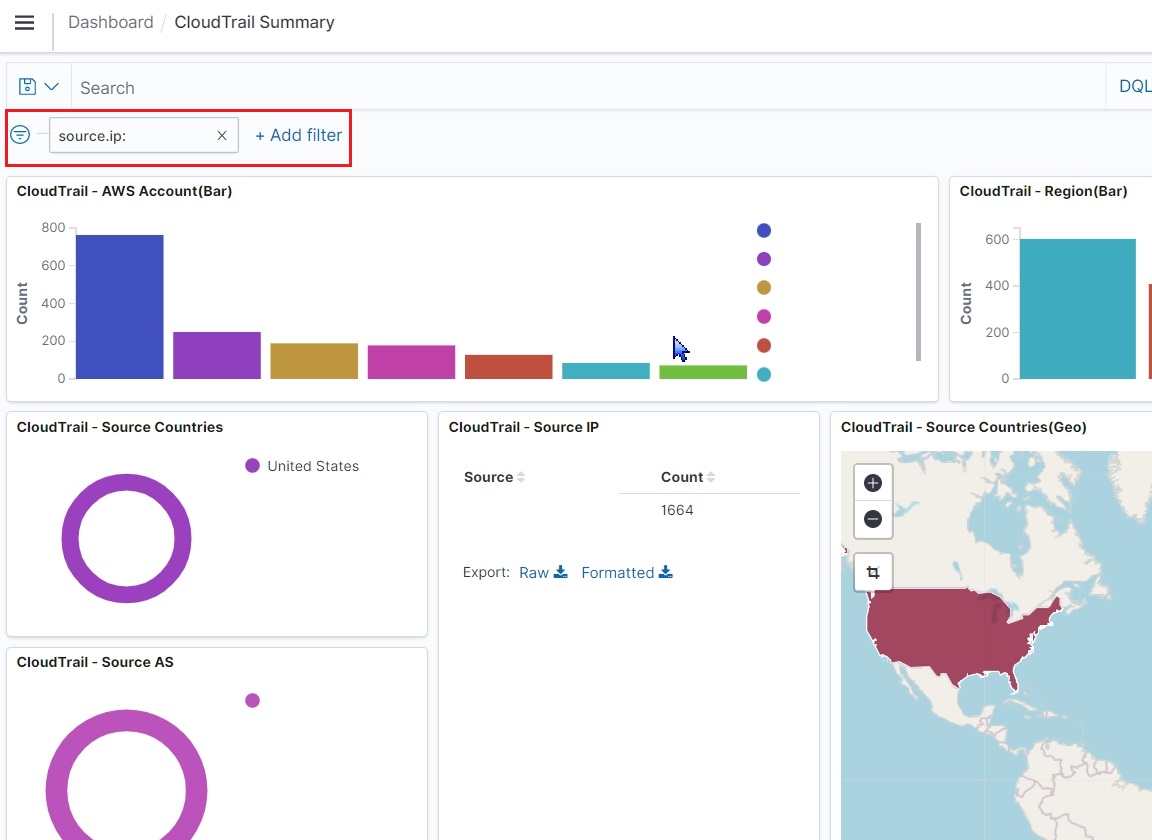
以下ではCloudTrailのダッシュボードを使ってフィルタリングを行っています。
まずはCloudTrailのダッシュボードを開きます。

特定の接続元IPアドレスにカーソルを合わせ、虫眼鏡をクリックします。
+の虫眼鏡はフィルタリングの追加、-の虫眼鏡はフィルタリングの除外設定となります。

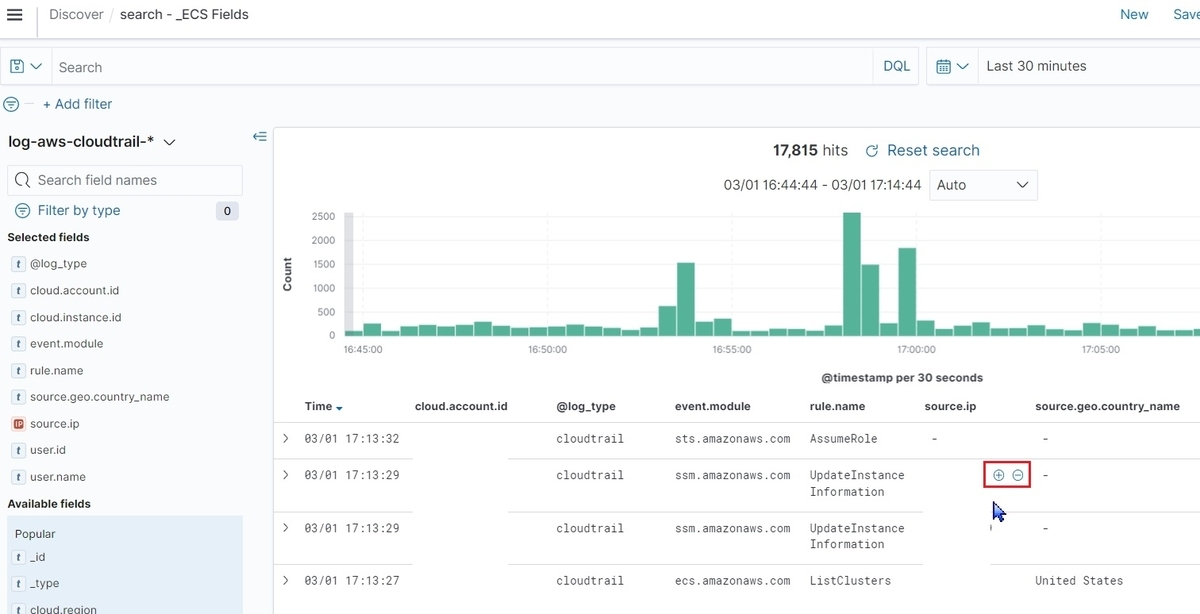
以下では特定のIPアドレスでフィルタリングの追加を行い、関連するログ情報を表示させています。
ログの調査
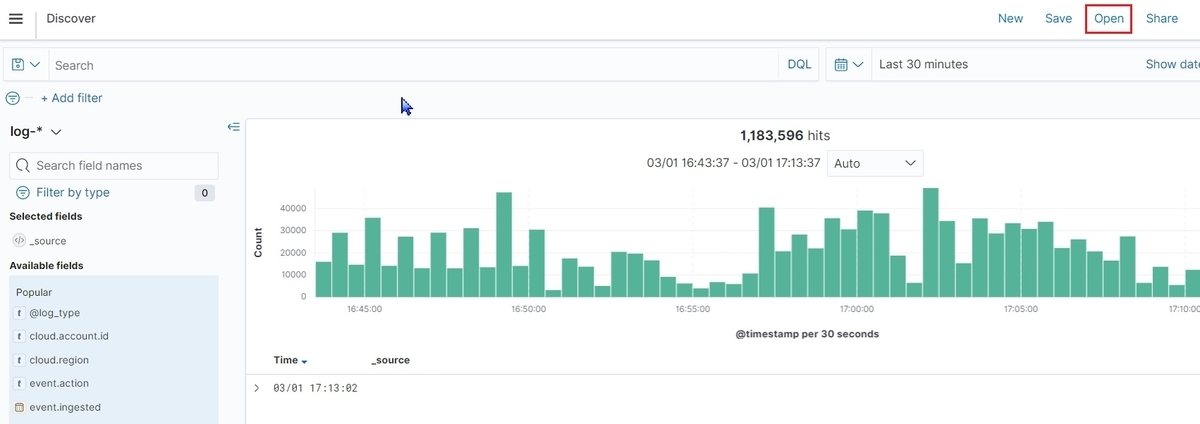
OpenSearch DashboardsのDiscoverでもログを調査してみます。
以下の画像ではマスクされているので分かりづらいですが、初期状態ではログが_sourceの中に詰まった状態で表示されて見づらいです。
これを改善するためにDiscoverで表示する列(以下、Field)を選択します。
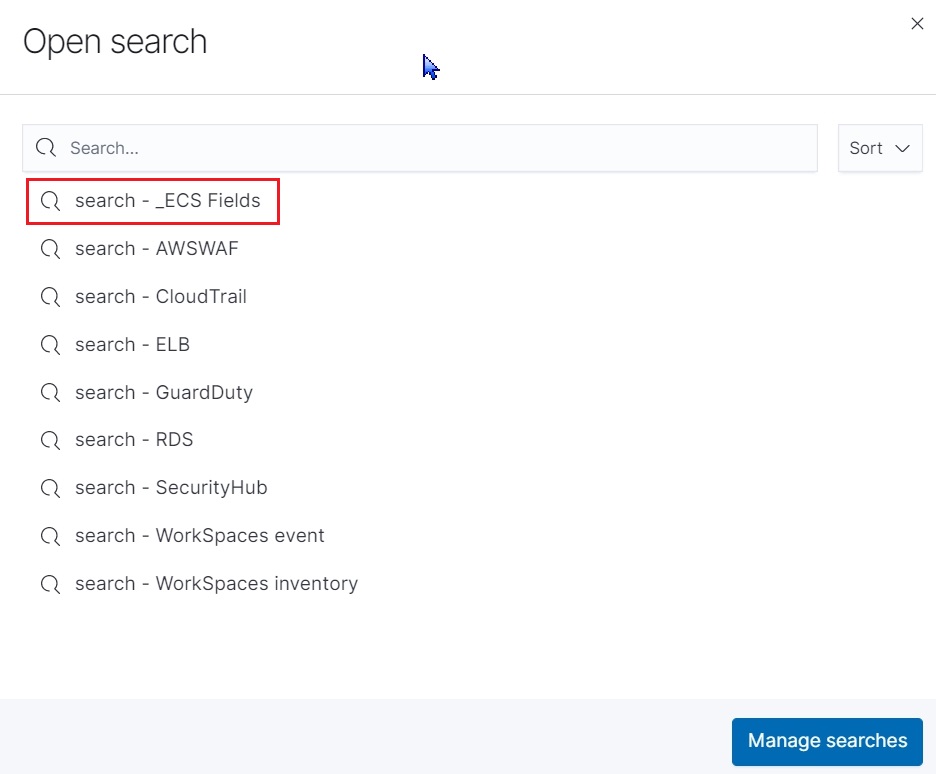
画像内のOpenをクリックすると、
Fieldのセットアップが準備されています。
このうち_ECS FieldsはAWSサービスのログであれば汎用的なセットアップとなっているため、こちらを選択します。
さらに特定のサービスのログを表示させたいため、インデックスを変更します。

ここではCloudTrailのインデックスとします。

すると、CloudTrailのログをFieldでよい感じに分割してくれます。
可視化のときと同様に特定のデータでフィルタリングして調査することも可能です。
開始方法
基本的にはSIEM on Amazon OpenSearch Serviceに従ってデプロイすれば問題ありません。
また、IPアドレスに地理的情報を付与するためにはMaxMindへの登録が必要となります。
登録手順につきましてはこちらをご確認ください。
注意点
設定値の更新
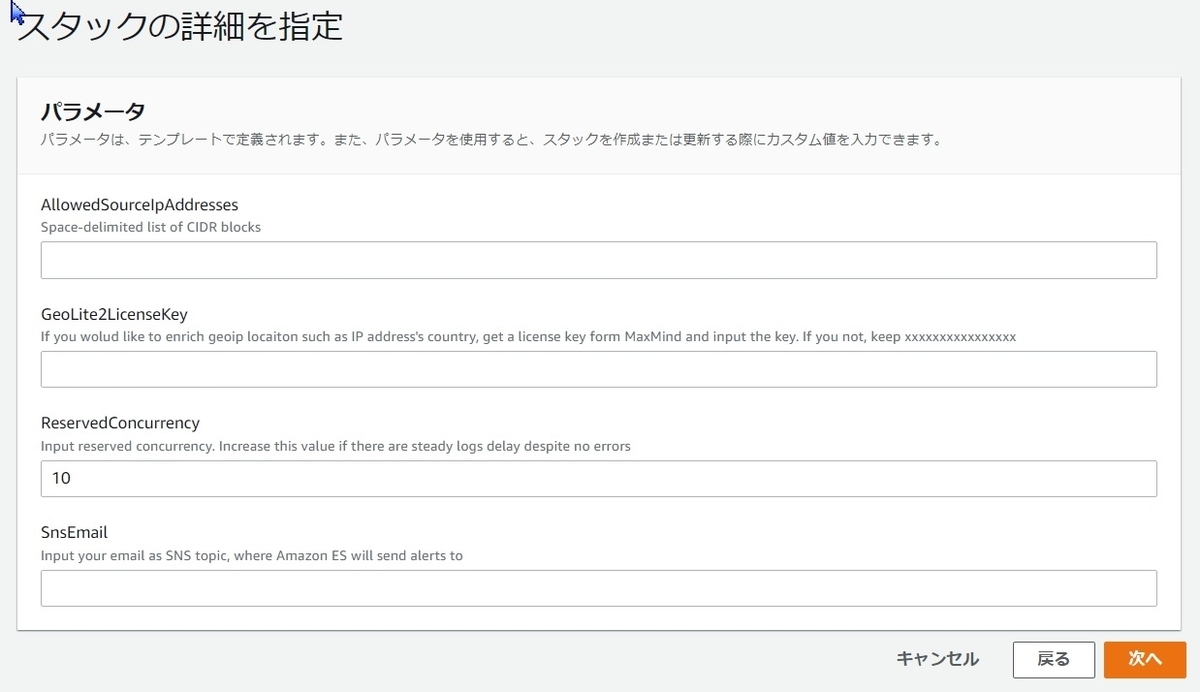
GitHub上のCloudFormation(以下、CFn)から構築する場合ですが、構築後の更新は基本的に手動です。
例として、以下のAllowedSourceIpAddressesではOpenSearchへのアクセスを許可するIPアドレスを指定するのですが、構築後にCFnでパラメータ値を変更しても反映されません。
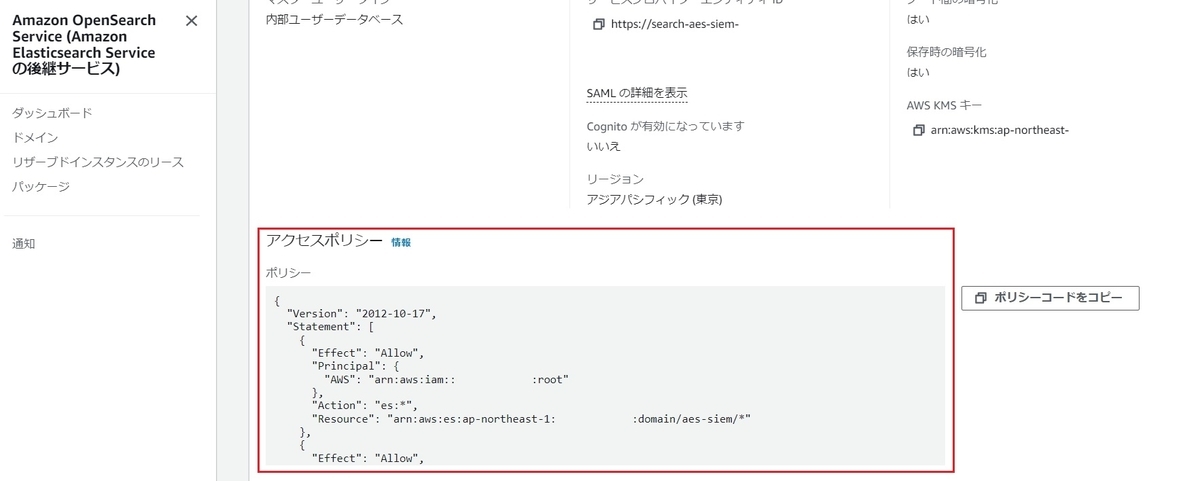
もし変更したい場合は、以下のアクセスポリシーを更新してあげる必要があります。
インデックスの閲覧権限
少なくとも私の環境下では初期デプロイ後、OpenSearch Serviceコンソールのインデックスを表示しようとすると以下のエラーが出ていました。
{"error":{"root_cause":[{"type":"security_exception","reason":"no permissions for [indices:monitor/stats] and User [name=arn:aws:iam::AWSAccount:role/IamRole, backend_roles=[arn:aws:iam::AWSAccount:role/IamRole], requestedTenant=null]"}],"type":"security_exception","reason":"no permissions for [indices:monitor/stats] and User [name=arn:aws:iam::AWSAccount:role/IamRole, backend_roles=[arn:aws:iam::AWSAccount:role/IamRole], requestedTenant=null]"},"status":403}
これはIAMの権限だけの問題ではなく、OpenSearch Dashboards側で権限を付与してあげる必要があります。
OpenSearch DashboardsでSecurity => Rolesと進み、任意の権限に対してMapped usersのBackend roleに自身が使用するIAMのARNを設定します。
※以下の画像ではall_access権限を付与しています。

ちゃんと権限が付与されると以下のようにインデックスを閲覧することができます。

やったこと
やったことだけ記載します。
AWS SSOとの連携
今回はOpenSearch Serviceをパブリックで作成しています。
そこでアクセス制限をIPアドレスと多要素認証(以下、MFA)で行うこととし、AWS SSO側でMFA認証、OpenSearchのアクセスポリシーでIPアドレス認証を行っています。
AWS SSOではID管理も実施することとし、個人毎に作成したユーザーを所属会社毎にグルーピングしています。
各グループにはグループIDが付与されますので、
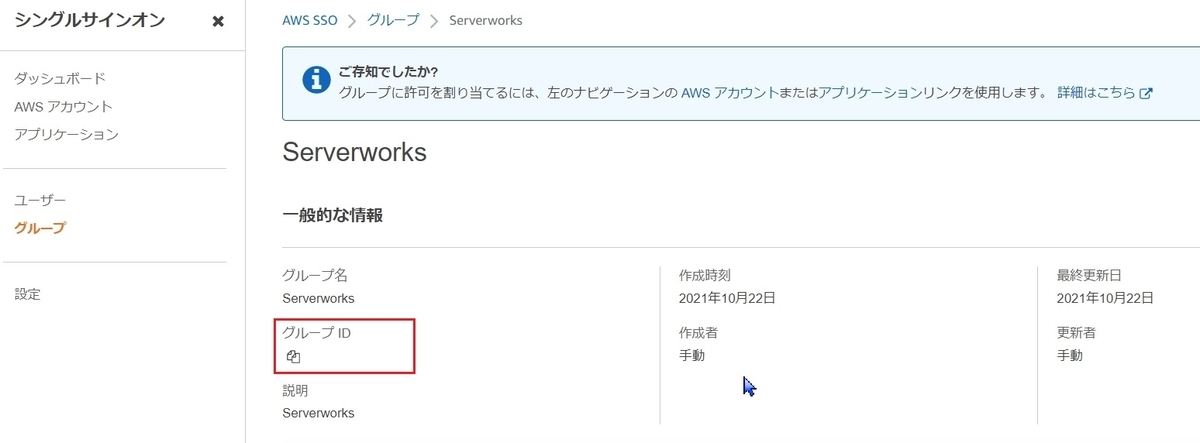
こちらをOpenSearch Dashboards上で渡したい権限のBackend roleに登録してあげます。

そして、AWS SSOからOpenSearch Dashboardsへアクセスするためにアプリケーションを登録します。
アプリケーションメタデータ、

属性マッピング、

割り当て済みユーザーはAWS SSOのグループを登録しています。

いくつか手順を割愛していますが、あとはAWS SSOにてMFA認証を必須に設定すればIPアドレスおよびMFAによる認証が実装できます。
インデックスのサイズ
まずは各インデックスに対するシャードのサイズを調整する必要があります。
シャードのサイズですが、以下の推奨値があります。(理由も引用元に記載されています)
シャードのサイズは 10~50 GiB にすると良いようです。 https://docs.aws.amazon.com/ja_jp/opensearch-service/latest/developerguide/sizing-domains.html#bp-sharding
そのうえでインデックス毎のシャード数を確認すると以下のようになっています。
※シャード数はもちろん変更することも可能です。
| ログ種別 | シャード数 | 備考 |
|---|---|---|
| CloudTrail | 3 | SIEM on Amazon OpenSearch Serviceのデフォルト値。 ※執筆次点での設定値です。 |
| VPCフローログ | 3 | 同上。 |
| GuardDuty | 1 | 同上。 |
| SecurityHub | 3 | 同上。 |
| MySQL | 3 | 同上。 |
| PostgreSQL | 3 | 同上。 |
※シャード数はDev Toolsでコマンドを叩いたり、こちらのnumber_of_shardsなどで確認できます。
ざっくりの目安として、CloudTrailのインデックスであれば30 ~ 150 GBの範囲だと3分割されたときに10 ~ 50 GBの範囲に収まります。
GuardDutyであればそのまま10 ~ 50 GBですね。
インデックスの作成前にシャード数を指定してあげる必要があるため、シャード数の選択を参考にシャード数を調整する必要があります。
別のアプローチとしてはインデックスのローテーション間隔を変更することでも対応可能です。
SIEM on Amazon OpenSearch Serviceのデフォルト値では、インデックスのローテーション間隔は月次となっています。
それではインデックスが肥大化してしまう、という場合は以下のようにuser.iniを記述してLambdaレイヤーとして実装することで、特定のインデックスに対してローテーション間隔を変更できます。
[vpcflowlogs] index_rotation = daily [rds-postgresql] index_rotation = daily
上記の例ではVPCフローログとPostgreSQLのインデックスに対して、ローテーション間隔を日次へ変更しています。
user.iniに記述する内容は上書きさせる設定値のみで問題ありません。
詳細はログ取り込み方法のカスタマイズをご確認ください。
他にもインデックスのRollover機能もございますが、こちらはインデックス名に日付情報を含めることができず、インデックスの検索性が損なわれることから使われないケースが多いようです。
インデックスの管理
OpenSearchのデータ領域はHotノード、Warmノード、Coldノードの3種類があります。
インデックスがOpenSearch上に作成されると、最初にHotノードへ保管されます。
ただし、HotノードはEBS上に存在するため大きな容量を保管するにはコストが高くなります。
そのため、保管する容量が1 TBを超えそうであれば積極的にWarmノード、Coldノードへとインデックスを移していき、コスト効率を高めた方がよいです。
WarmノードとColdノードはオプションになりますので設定変更をして有効化する必要があります。
それぞれの関係を表した図が以下です。

※UltraWarmインスタンスは上図の中でEC2単体に見えますが、データ領域はS3となっておりファイルゲートウェイに近い実装となっています。(なので安い)
インデックスの移動は手動と自動、どちらでも実行することができます。
また、不要となったインデックスの削除もできますので、1年間はColdノードに保管しておき、その後に自動削除することも可能です。
インデックスの管理にはState management policiesを定義する必要があり、こちらをインデックスに関連付けることでインデックスの管理を自動化できます。

ポリシーの例につきましてはAmazon OpenSearch Service (Amazon Elasticsearch Service の後継サービス) でのインデックスステート管理の自動化が参考になります。
私は負荷試験中にログを取り込んだため、ひどい目に遭いました。。。
チューニング
ディスクサイズ
ディスクサイズは前述のインデックス管理と併せて検討する必要があります。
注意点としましては、インデックスの移行時に容量を圧迫するため、ディスクサイズには余裕がないといけないです。
ギリギリのサイズで運用することはおすすめしません。
インスタンスタイプ
専用マスターノードはAmazon OpenSearch Service の専用マスターノードの下部を参考に選定すれば問題ありません。
データノードはインスタンスタイプとテストの選択を参考にしてください。
注意点としては、UltraWarmの有効化(Warmノード)には特定のインスタンスタイプを選択する必要があります。
また、メモリはJVMに確保されるため、見かけ上は最大メモリ使用率が高いのですが問題ありません。
データノードの負荷を見る際は、CPU使用率などを確認していただくとよいかと思われます。

es-loader
OpenSearchへログを取り込むためのLambda関数です。
基本的にはErrorsが以下のように収まっていて、同時実行数の上限に張り付いていなければ問題ないと思われます。
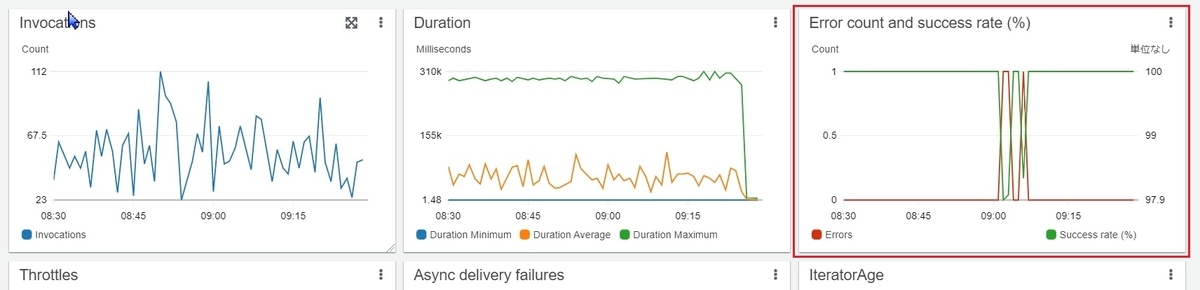
Errorsを完全に0にすることもできるかもしれませんが、監視上は局所的にErrorsが高くならなければ問題ないようです。
Errorsが高い状態だと以下のようになります。

エラーが頻発するとSQSのキューも溜まっていきます。
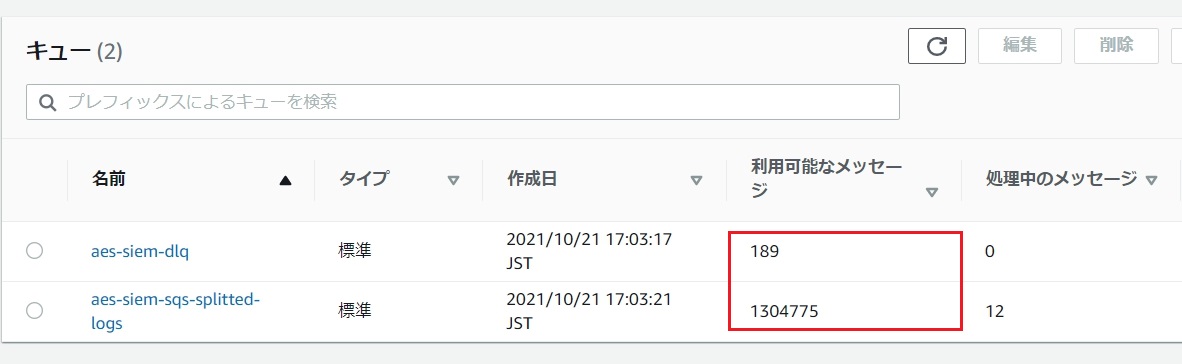
Lambdaの設定ではエラー時に再試行が走ります。

そうなると以下のようにLambdaの同時実行数も上限に張り付いてしまいます。(デフォルト値は10です)
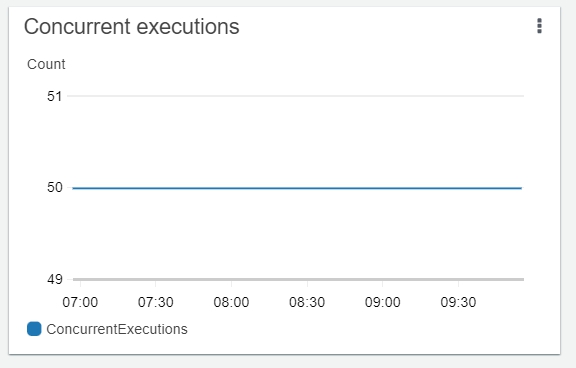
es-loaderの性能は以下のため、デプロイ後はLambdaの同時実行数に注意しないと利用料金が高額となります。
そのため、ログ取り込み時のエラーの解消にはいち早く着手することを推奨します。(取り込みも遅くなりますし)

いくつかのエラーはすぐに対処できましたが、以下のように正規表現のマッチングなど、アプリケーション側の改修が必要なエラーもあります。
※こちらは改修を依頼中のため、そのうち解消するものと思われます。

その他
書きたいことがいっぱいあるのですが、時間の都合もありいくつか割愛しております。
以下にはキャプチャを撮っていたけれど流れで差し込めなかったものを載せます。
Dev Tools
コマンドが叩けます。
ここでしか実行できない操作も多いため、よく使うことになります。
以下のコマンドではインデックスの設定を参照しており、シャード数などが確認できます。

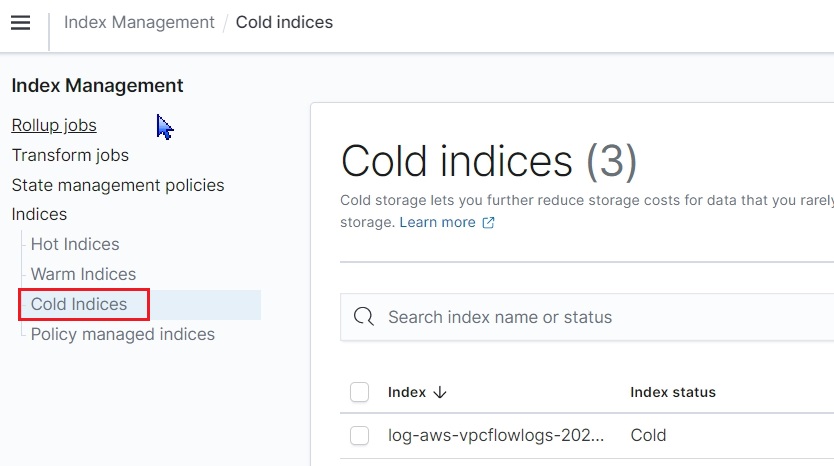
インデックスの保管場所
インデックスがどのように保管されているかが見えます。
Hotノードを使いすぎると高額なので、Warmノードにインデックスを寄せていることが分かるかと思われます。
Hotノード
Warmノード

Coldノード
所感
今回、初めてOpenSearchを触りましたが覚えることが多すぎてなかなか苦労しました。
OpenSearch Dashboardsの権限まわりやAlertの設定も細かくやりたかったのですが、検証時点ではそこまで辿り着けなかったため、どこかでじっくりやりたいなと思っています。
OpenSearchとAmazon Detectiveは一部、似たような機能を提供しているため、導入時にはAmazon Detectiveを無効にするなどの検討はしてよいと考えます。
Amazon Detectiveにつきましては、過去に【入門】Amazon Detectiveを触ってみる【やってみた】という記事を投稿していますので、必要に応じてご参照くださいませ。
以上となります。