

はじめに
2015年入社の白鳥です。
私は今、一人暮らしをしているのですが、自分で家計を管理するというのはなかなか大変です。家計管理の第一歩は、お金の出入りを記録すること、次の一歩は、自分のお金の使い方の特徴を把握することかと思っています。記録は Money Forward を使ってつけていますので、そろそろお金の使い方を把握したくなってきました。例えば「毎月○○日前後に××にてお金を使いすぎる傾向にある」ということが分かれば、先回りして対策を打つことができます。
というわけで、AWSのサービス、Amazon Machine Learning を使って、自分の家計データを分析してみました。今回の記事では、データ分析の結果やそこから得られる結論には触れず、「Amazon Machine Learning を使う上でつまずいたこと」について書いておきます。(データ分析の結果や結論については、もう少し工夫を重ねて予測の精度を上げることができたら書こうと思います)
やったこと
Money Forward に記録された自分の家計記録をcsvで出力し、Amazon Machine Learning に入力しました。入力データから、私の今後の支出を予測するモデルを作成し、予測させてみました。おおまかな手順を以下に示します。
- Amazon S3 にcsvをアップロード
- Amazon S3 に bucket を作成し、Money Forward から出力したcsvをアップロード
- データソースを作成
- csvを Amazon Machine Learning に読み込ませ、データソースとして保存
- モデルの作成および評価
- 上記のデータソース内の家計データのうち、7割を使ってモデルを作成
- 作成したモデルを使って、残りの3割のデータより支出金額を算出し、実際の支出額と比較
- 今後の予測
- 今後の支出についてモデルを使って予測
今回の分析に使用したcsvの一部を以下の図に示します(ブログにさらしても問題ない無難な記録をピックアップして示しています)。2015年6月18日にドン・キホーテで、2015年6月19日にはまいばすけっと、セブンイレブン、大戸屋にて買い物をしたことを示しています。
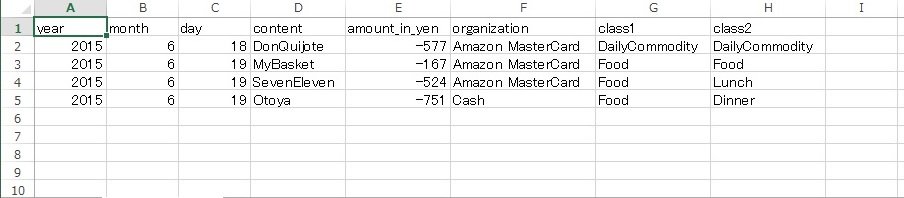
csvの各列には、以下のようなデータが格納されています。
- year, month, day: 買い物をした日の年月日
- content: 買い物の内容 主に買い物をした店の名前
- amount_in_yen: 買い物の金額(円)
- organization: 支払に使用したクレジットカードや引落し金融機関
- class1, class2: 支出の大分類と小分類
これら各列に格納された情報は、Amazon ML の公式チュートリアルによると attribute といいます。対して、各列の情報(ここでは1回の買物情報)は field と呼ばれます。Attribute のうち、モデルを使って予測したいものは target attribute といいます。今回は支出金額を予測したいので、 amount_in_yen を target attribute に設定します。
これより、私がつまずいた点を3つ紹介します。
1. 現状、 US East (N. Virginia) と EU (Ireland) でのみ利用可
2015年10月22日現在、Amazon ML は上記2つのリージョンでのみ提供されています。したがって、S3 と Amazon ML の間のデータのやりとりをスムーズにするには、bucket を US Standard または Ireland に作る必要があります。
2. Attribute の取捨選択は、データソース作成前にやるべし
データ分析をするにあたり、分析に不要なattributeは削除したい場合があります。Amazon ML のデータソース作成コンソールでは、 attribute の削除はできないので、csvをアップロードする前に削除しておく必要があります。
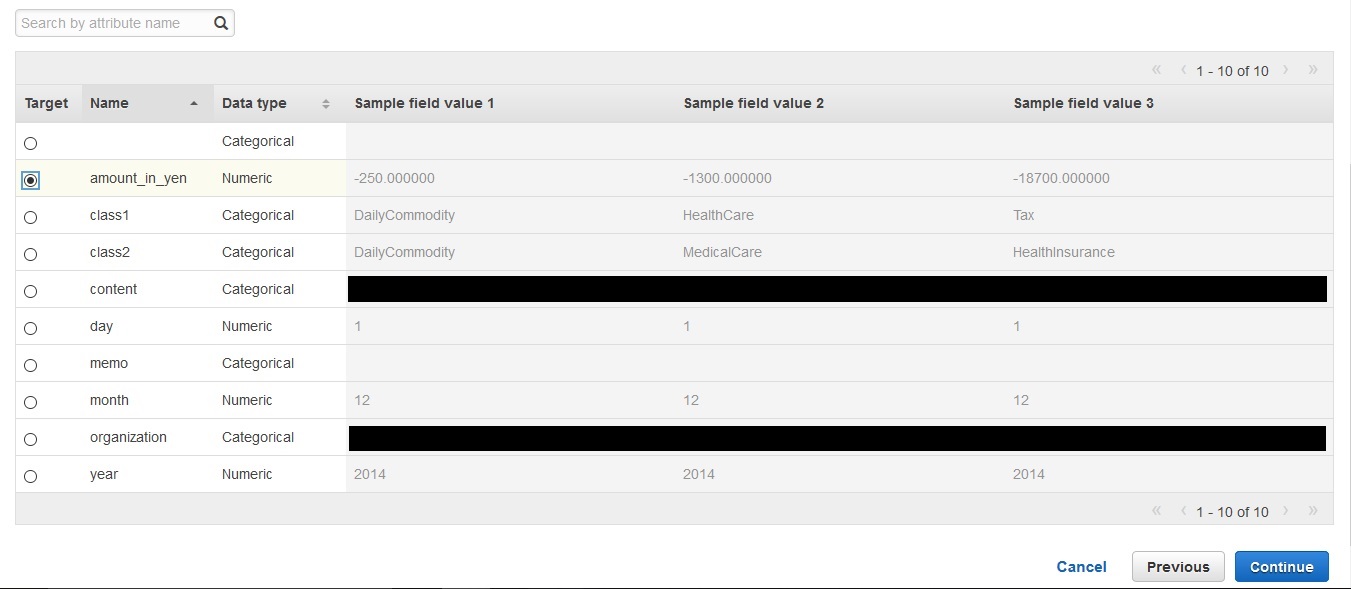
ちなみにすべての attribute は、データソースの作成時にデータの中身に応じて以下4種類のData typeに分けられます。
| 説明 | 今回該当するattribute | |
| Numeric | 数値データ | year, month, day, amount_in_yen |
| Categorical | 各行のデータを分類するための文字や数字 | content, organization, class1, class2 |
| Binary | Yes/No などの2つに分類する値 | なし |
| Text | スペースで区切られた文字列 | なし |
このData typeの設定画面にて、各attributeの名前の編集や、3つのサンプル field の確認を行うことができます。
3. 予測時の入力データは、 target attribute を列ごと消しておく
モデルを使って予測をするとき、 target attribute 以外のデータを入力データとして Amazon ML に渡す必要があります。このとき、 target attribute は列自体がない状態にしておきます。今回は、予測時の入力データは以下のような構造になります。下図の例では、2015年11月1日にドン・キホーテ、まいばすけっと、セブンイレブン、大戸屋で昼食をとった場合に、いくら支出するかを予測しようとしています。

Target attribute を空欄にするだけだと、モデルと入力データの構造が一致せず、エラーになります。
おわりに
今回は「とりあえず Amazon ML を動作させるための注意点」を挙げました。次の段階として、より精度のよい予測をするための注意点を挙げる必要があるかと考えています。予測結果に関する考察と合わせて、今後記事にできればと思います。