

できるだけ作らないSI・ファストSI
こんにちは技術2課・大阪メンバーの柏尾です。
最近更新が滞り気味(?)の大石代表による「CEOのブログ」ですが、僕が入社前に読んでそのビジョンにすごく共感した記事が下記の2本です。
「ファストSIとアーティスティックSI」
「作らないSIerの代表がDevLOVE代表と対談した話」
その中に、"作るモノは「作ることによって競争優位が実現できるまで」作り込むし、作らないモノは徹底的にありものを使う" という一文があります。
サーバーワークスの場合だと、
・作ることによって競争優位が実現出来るもの = Cloud Automator
・作らないモノは徹底的にありものを使う = AWSをはじめとする各種クラウドサービス
という感じでしょうか。
とにかく、できるだけ既存のサービス・機能を使ってお客様や自分達のビジネス課題をクリアしていこうというのがサーバーワークスの基本スタンスなわけです。
データ統合・ETL処理
ただし、クラウドサービス上の各種データソースをつなぎ合わせたり、データ分析のためにETL系(Extract/Transform/Load)処理を行う場合、どうしても「プログラム的なもの」が必要になってきます。
これらの処理は、パターン化された定形処理が多いので、ゼロからプログラムをゴリゴリ書くのはとても非効率ですし、それに比例してバグも増えます。
世の中にはこういった定形処理をプログラムをほとんど書かずに実装できるデータ統合・ETLツールがたくさんありますのでそれを利用しない手はありません。うまく活用すれば何倍もの生産性で高い品質のプログラムを開発することができます。
Talend Open Studio
僕はどちらかというと開発系出身のエンジニアなので、これまでそういった処理をプログラムで書いたり、商用のツールを使ったりしてきましたが、つい最近、無償のオープンソースツールである「Talend Open Studio」(以下TOS)を使ってみて個人的に使いやすかった&無償でここまでできるのか!と衝撃を受けたので、その紹介をしたいと思います。
こういった開発系ツールは「いかに自分の手に馴染むか」「ドキュメントやサンプルが充実しているか」といった所が生産性に影響してくると思うのですが、TOSはEclipseベースのIDEなので、これまでEclipseで開発をされてきた開発者の方にとっては馴染みのあるインターフェースになっています。
AWSなどクラウド上のデータソースにも対応
TOSはAWSを始めとする各種クラウド上のデータソースに対応したプラグインも豊富に提供されているので、クラウドとのデータ連携もやりやすくなっています。AWSの場合、RDS・Redshift・S3・EMR・Auroraなどがデータソースとして利用可能になっています。
各種の処理コンポーネントの使い方に関してはTalend Help Centerで参照することができ、また日本にもtalend japan communityというコミュニティサイトがあるので、使い方に関する情報もここで得ることができます。
開発環境・稼働環境
TOSの動作環境ですが、Javaがインストールされていれば WindowsやMacOS上でTOSを使ったデータ処理の開発ができます。
作成したジョブから生成されるプログラムはJavaコードそのものなので、プログラムを稼働させる環境にはJavaさえ入っていればOKです(TOSのインストールは不要)。
ジョブのエクスポート機能を使えば、それらJavaプログラムと一緒に.bat/.shファイルが生成されるので、JavaがインストールされたWindows ServerやLinuxなどの環境で、タスクスケジューラやcronからそれらを呼び出すようにしておけば処理の定期実行も可能ということになります。
Talend Open Studio のインストール
Javaのインストール
Talendのインストールですが、事前にJavaのインストールが必要です。
自分のMacにはJava7をインストールしました。(JavaのバージョンによってはTOSが動かないことがあるので注意が必要です。)
Talend Open Studio のインストール
無償版のTOSにも幾つかバージョンがありますが、オーソドックスなデータ統合処理であれば「Talend Open Studio for Data Integration」でOKです。Hadoopなどの環境と連携ができるビッグデータ系のコンポーネントを使いたい場合は「Talend Open Studio for Big Data」を使うことになります。

2015年8月12日時点ではVer6.0.0が利用できるようになっていますので、それをインストールしたいと思います。Mac版のインストールはダウンロードしたzipを適当な場所に解凍するだけです。
起動は解凍したディレクトリ内にある「TOS_DI-macosx-cocoa.app」から行います。(Windows版も同じくインストールフォルダにあるexeファイルから起動することができると思います)
Mac版でTOSが起動時に警告が出る場合はシステム環境設定の「セキュリティとプライバシー」で「ダウンロードしたアプリケーションの実行許可」でTOSを追加しておきましょう。
起動時にライセンスへの同意画面が出ますのでOKします。プロジェクト名には「My_Project」と記入して進みます。

起動後に再度各コンポーネントの利用についてライセンスへの同意画面がでますので「すべて同意」ボタンを押します。
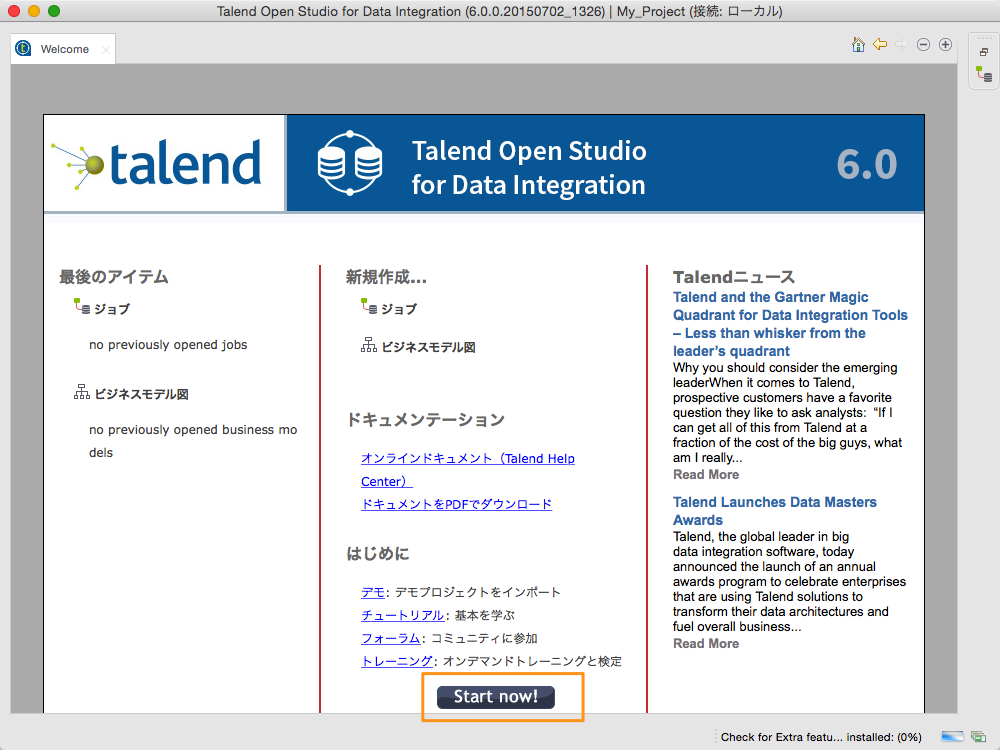
下記のようにワークスペースが表示されるので「Start Now!」ボタンを押します。
途中何度かモジュールのダウンロード画面などが表示されますが、全部OKしておいて大丈夫です。
※有償版もありますが、こちらはチーム開発系の機能や、運用管理・監視系の機能が付加されていますので、大規模なチーム開発や運用・有償サポートが必要になった段階で検討すれば良いと思います。
S3からデータを取得してみる
準備が整ったところで、早速何かジョブを実装してみたいと思います。せっかくなのでAWS系のサービスと連携したジョブを作成したいと思います。
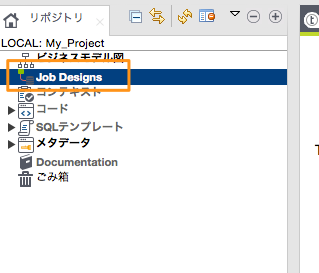
左メニューの「Job Designs」を右クリックし、「ジョブの作成」を選択します。
ジョブ名・説明などを入力してFinishを押します。
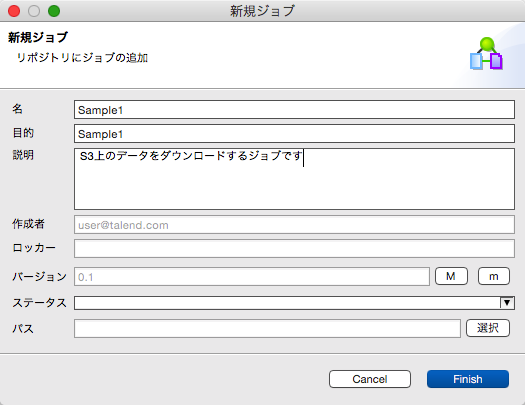
真ん中にデザイナー領域、右側にコンポーネントの検索ウィンドウがありますので、検索ウィンドウに「S3」と入力します。S3に関連するコンポーネントが表示されます。良く使うコンポーネントは右クリックでお気に入りに追加しておくこともできます。
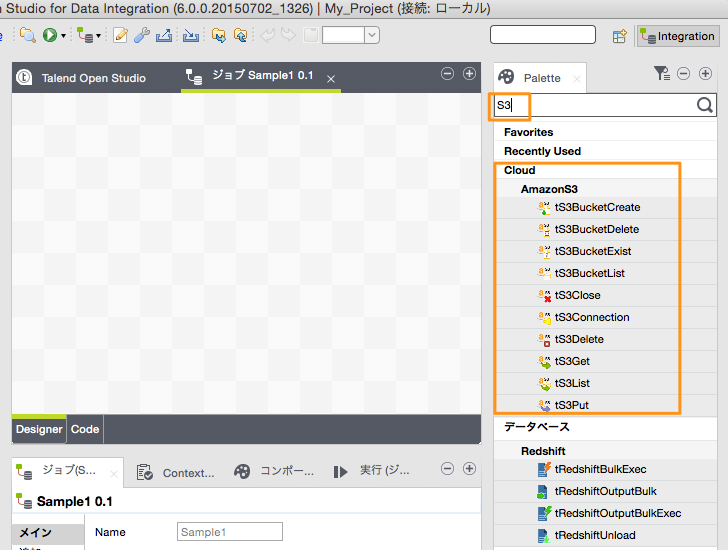
「tS3Get」というコンポーネントをデザイナー領域にドラッグ&ドロップします。

tS3系のコンポーネントを使う場合、AWS SDK for Javaのライブラリが必要なため、下記のように警告がでます。
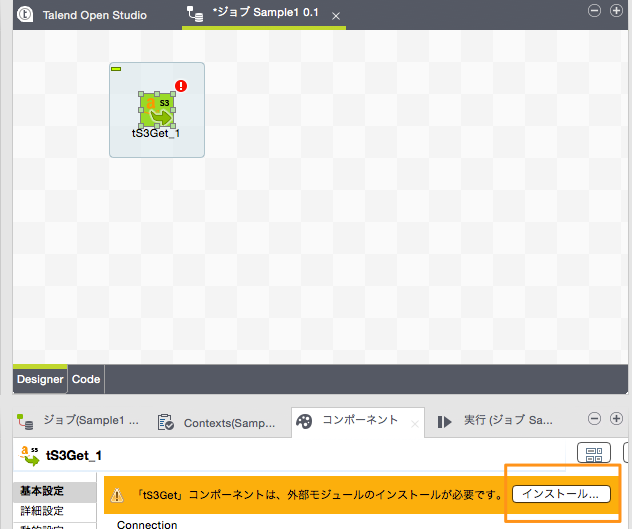
「ダウンロードとインストール」ボタンを押すとAWS SDKのライブラリがTOSにインストールされます。
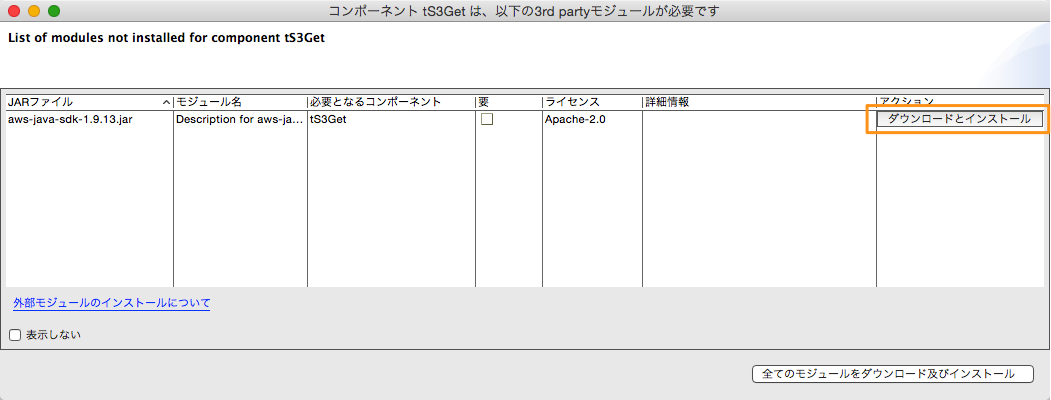
今回はAWS入門ガイドで提供されているS3上のサンプルデータを取り込んでみたいと思います。
対象のバケットは全ユーザから読み取りが可能になっていますので、AccessKeyやSecretKeyは自分のアカウントのもので大丈夫です。
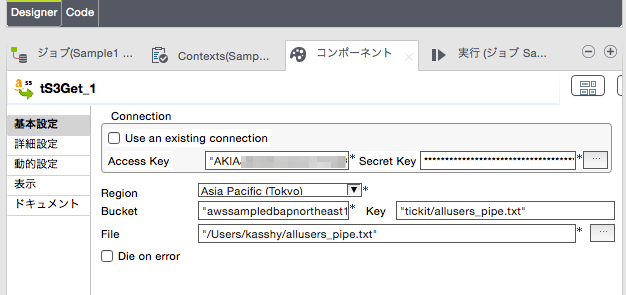
tS3Getコンポーネントの「基本設定」に下記の情報を記入します。
| 設定名 | 設定値 | 補足 |
|---|---|---|
| Access Key | AWSアカウントのAccessKey | 自分のアカウントのものでOK |
| Secret Key | AWSアカウントのSecretKey | 自分のアカウントのものでOK |
| Region | Asia Pacific (Tokyo)を選択 | S3バケットがあるリージョンを指定 |
| Bucket | "awssampledbapnortheast1" | バケット名を指定(今回はサンプルデータが置かれているバケット名) |
| Key | "tickit/allusers_pipe.txt" | バケット上のオブジェクトKeyを指定(今回はサンプルデータのオブジェクトKey) |
| File | "/Users/kasshy/allusers_pipe.txt" | 保存時のファイルパスを指定 |
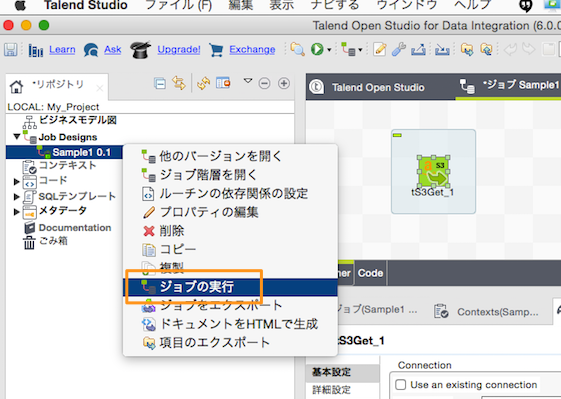
実行してみてファイルがS3からGETできるか試してみます。 ジョブを右クリックして「ジョブの実行」を選択します。
下部ウインドウにジョブの実行結果が表示されます。 [終了コード=0]となっていればジョブは成功です。
![]()
指定したファイルパスにファイルがダウンロードされていますね。開いてみると5万レコードぐらいあるデータでした。

今度はこのファイルを読み込んでフィルタしたりRedshiftに登録したりする処理をやりたいと思いますが、もう力尽きたので エントリが長くなるので一旦おわり!
まとめ
・データ統合、ELT処理はツールを活用すると便利!
・AWSをはじめとするクラウドのデータソース連携も可能
・CEOブログ更新はよ