

AWS Glue とはAWSマネージドなETLサービスですが、AWS Glue Databrewというのもあります。このAWS Glue DatabrewはAWS Glueの派生のようなサービスで、少々使い勝手が違います。今回はこのAWS Glue DataBrewを実際に使って解説したいと思います。
はじめに
以前に下記のようなブログを記載し、AWS Glue データカタログと AWS Glue Studioを利用したETLジョブ作成について紹介しました。AWS Glue StudioはビジュアルでかなりわかりやすくETLジョブが作成できる機能です。GUIでのジョブの作成だけでなくコードやSQLクエリで独自の処理を追加することもできます。実はAWS Glueにはもう1つGUIでデータ処理を作成できる機能があります。それがAWS Glue DataBrewです。
AWS Glue DataBrewとは?
AWS Glue DataBrewはコードを書かなくてもデータ処理が行えます。250を超える処理が用意されており、それらを組み合わせることでジョブを作成します。ドキュメントでは「a visual data preparation tool(視覚的なデータ準備ツール)」と評されているので、分析や可視化のための前処理用途を想定されいるのかもしれません。
AWS Glue DataBrewとAWS Glue Studioの違いは?
それぞれS3やDB、AWS Glue データカタログなど様々なソースのデータを処理できます。大まかな違いをまとめると以下な点が挙げられます。
| 項目 | AWS Glue DataBrew | AWS Glue Studio |
|---|---|---|
| あらかじめ用意された処理の数 | 250くらい | 12くらい |
| コードで処理の追加 | × | 〇 |
| ジョブの扱い | AWS Glue ジョブとは別物もの | AWS Glue ジョブ |
| ビジュアルの特徴 | データの中身がわかりやすい | データのソース・ターゲットがわかりやすい |
| 対象ユーザー | 非エンジニアな分析担当・アナリスト? | エンジニア? |
前述した通りAWS Glue DataBrewはあらかじめ用意された処理は豊富ですが、コードで独自の処理は追加できません。またジョブの扱いもAWS Glueジョブとは別ものになります。そのためAWS Glue DataBrewのジョブはAWS Glue ワークフローには組み込めません。AWS Glue DataBrewもAWS Glue Studioもビジュアルでデータ処理のジョブを作成しますが、AWS Glue DataBrewはデータのプレビュー機能やサマリーが表示されたりとデータの中身がわかりやすいです。一方でAWS Glue StudioはETLジョブ作成ツールというだけあってデータソースやターゲットがビジュアルでわかりやすい作りになっています。対象ユーザーを考えるとAWS Glue DataBrewは非エンジニアでも使いやすいツールだと言えます。
実際につかってみた
今回は冒頭に貼り付けたリンク先のブログ記事『【AWS Glue】AWS Glue Data Catalog と AWS Glue Studio を活用して簡単ETLジョブ作成!』と同じ処理をAWS Glue DataBrewでも作成したいと思います。
データ
今回は青空文庫の形態素データ解析データを使用します。「解析対象データ一覧」と「新字新仮名全データ」を使用ます。「解析対象データ一覧」は対象となる作品一覧で、「新字新仮名全データ」は形態素解析データになります。あらかじめAurora MySQLに「解析対象データ一覧」を、S3バケットに「新字新仮名全データ」を格納しています。
氏名 「河原 翔」 作品タイトル 「青空文庫 形態素解析データ集」 URL 「http://aozora-word.hahasoha.net/」
データセット作成
まずはデータソースとなるMySQLとS3のデータセットを作成します。DataBrewコンソールのデータセットにて「新しいデータセットの接続」をクリック。
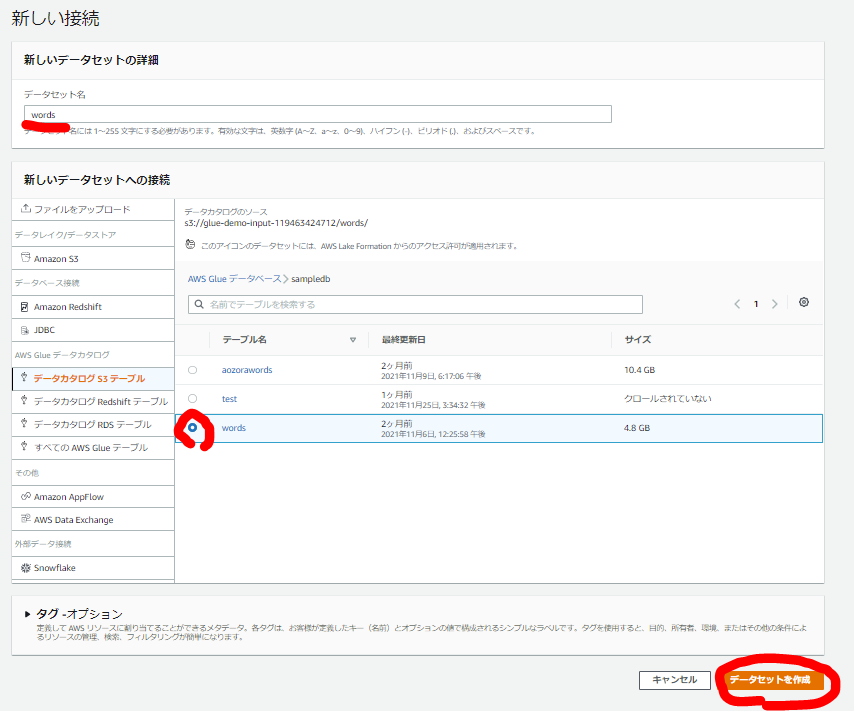
今回はデータカタログから作成します。対象のデータカタログテーブルを選択すると同じ名前でデータセット名が設定されます、適宜変更しましょう。テーブルを選択したら「データセットを作成」。
それぞれ作成したら一覧に表示されます。
プロジェクト作成
ではプロジェクトを作成します。DataBrewでは、プロジェクトにてデータをプレビューしながらジョブを作成していきます。
プロジェクト名を入力すると自動的にレシピ名も入力されます。レシピとはデータ処理の内容です。プロジェクトで作成する処理の中身はレシピとして保存されます。
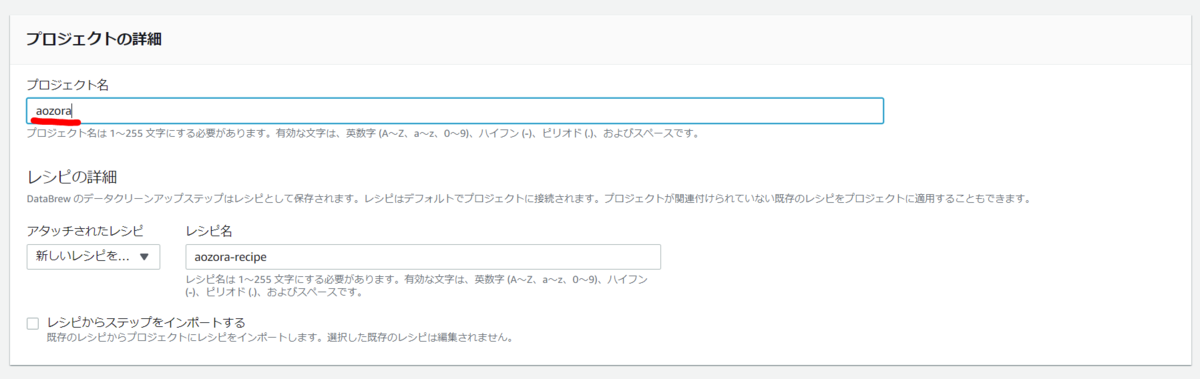
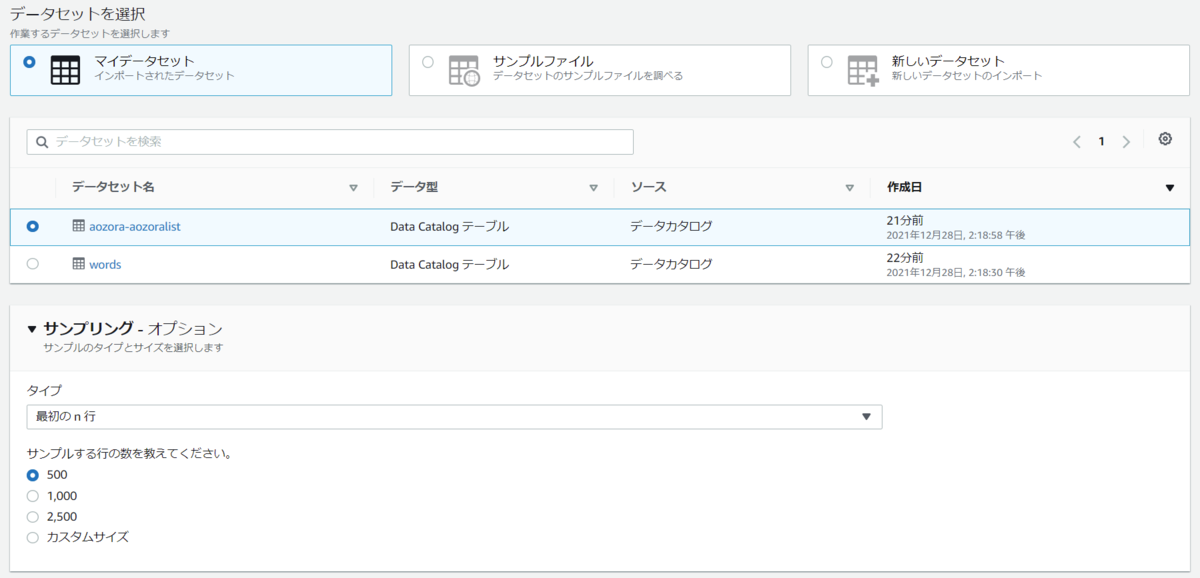
プロジェクトで使用するデータセットを指定します。今回はMySQLのデータからプロジェクトを作成します。後ほど触れますが複数のソースがある場合でもプロジェクトは1つのデータセットから作成します。Joinなどで別のデータセットを指定する場合はプロジェクト内で指定します。プレビューされるデータのサンプリングの仕方も指定できます。今回はランダムな500行とします。
IAMロールを指定して「プロジェクトを作成」。
作成するとプロジェクトが立ち上がります。裏側でリソースが起動しセッションが開始されるので少々待ちます。
レシピ作成
プロジェクトが立ち上がったらデータのプレビューを見ながら処理を追加してレシピを作成していきます。データのプレビューには各列内でのデータの分布も表示されますが今回使用したデータはそれぞれユニークなデータが多いのであまり参考にはなりません。処理は上部バーに並ぶ処理から選んだり、各列の ・・・ から追加したりなど様々用意されています。これらをクリックして処理の詳細を指定してレシピを作成します。↓の画像は一例で処理によって指定すべき値は異なります。レシピに追加した処理は編集・削除も可能です。
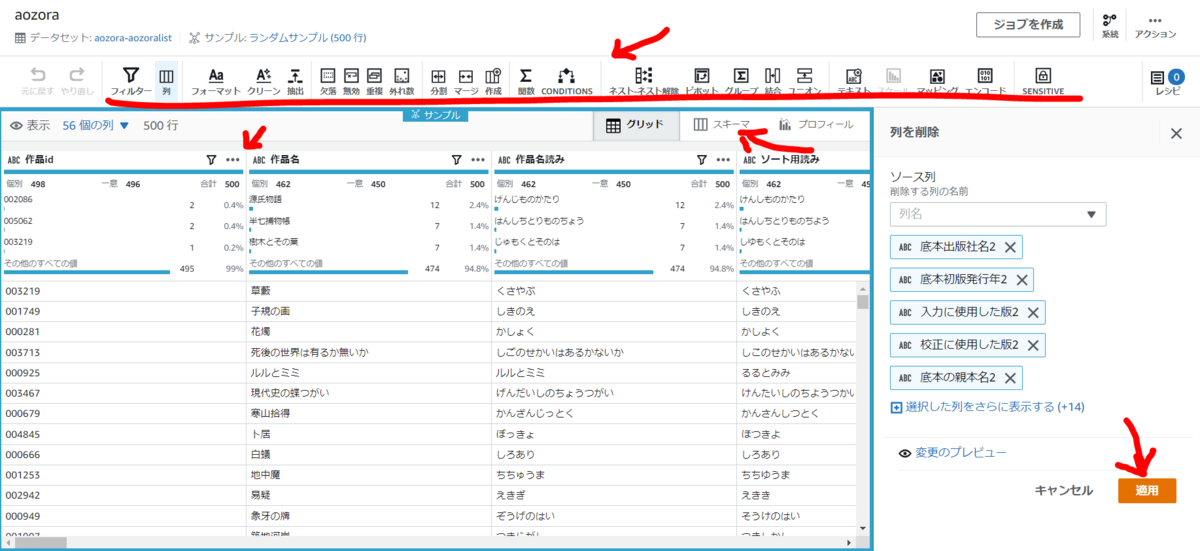
他のデータセットを利用する処理も追加できます。今回はS3にあるデータとJoinさせます。結合というのがJoinにあたります。
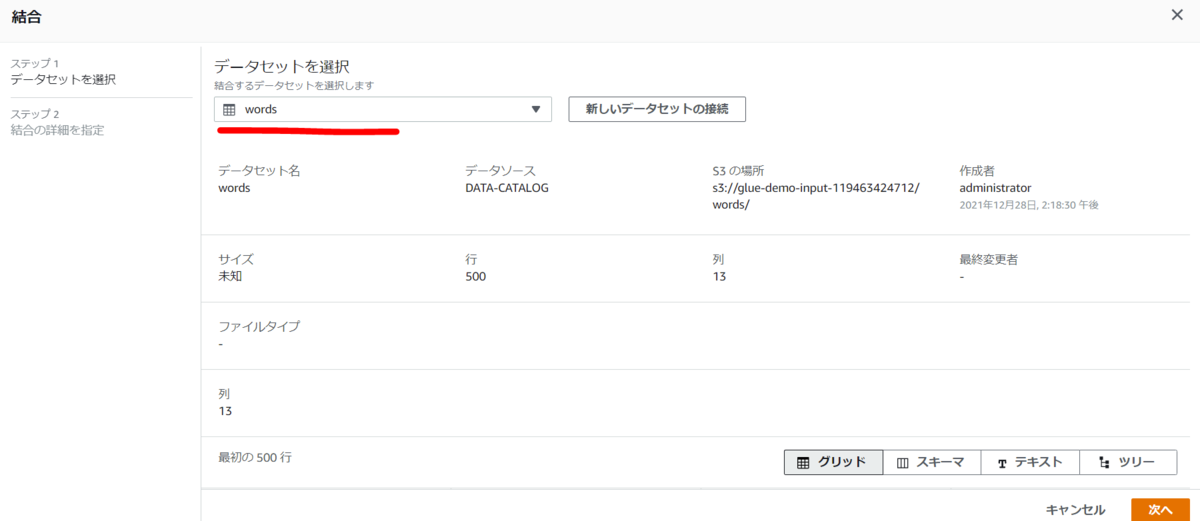
先ほど作成したS3のデータセットを選択し「次へ」。ここではJoinさせるデータセットのプレビューも可能です。
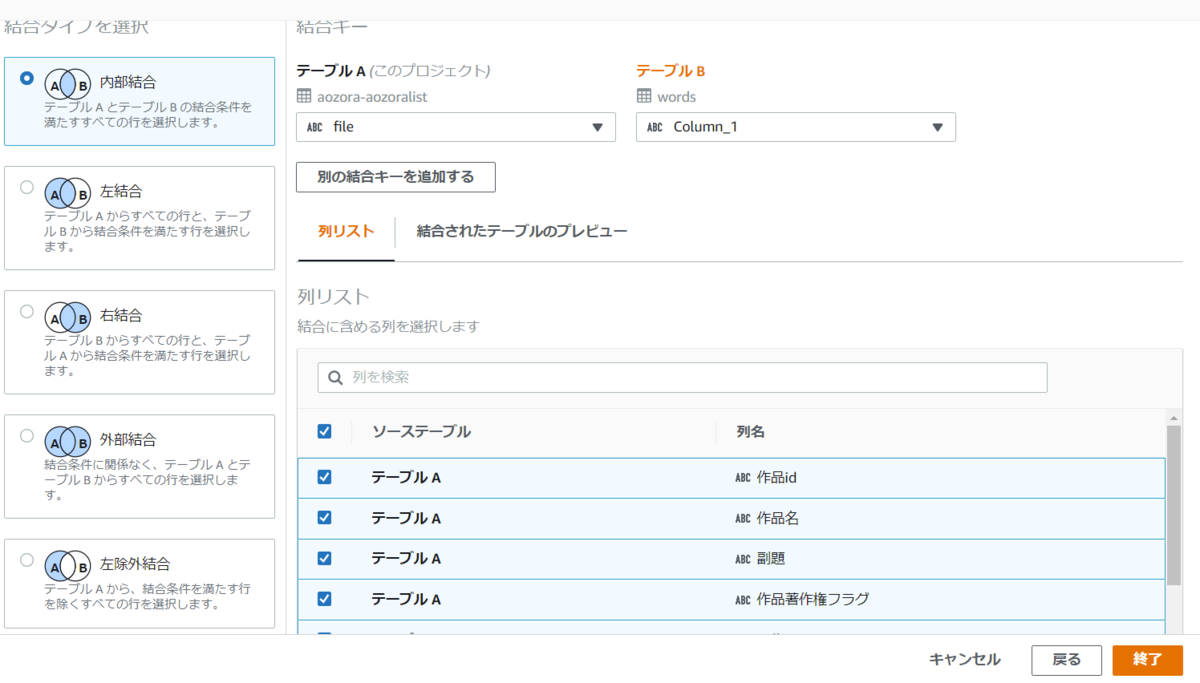
今回はInner Join(内部結合)です。なぜかS3の方が列名をちゃんと取得できてませんが、MySQL側file列と対応する列を指定し「終了」。
なぜかこちらのプレビューも効かなくなりましたが気にせず続けます。
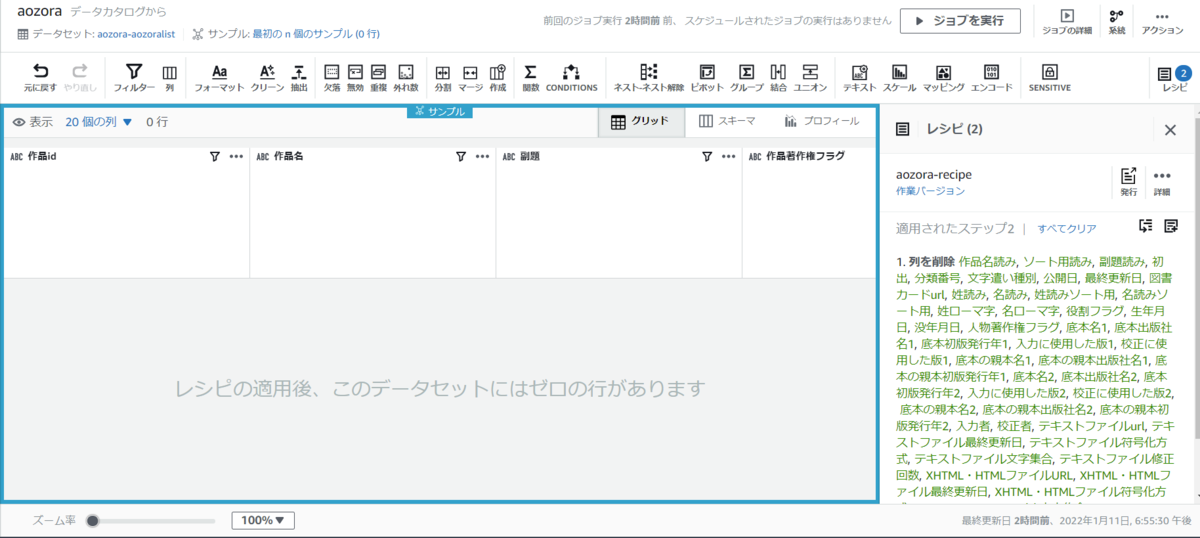
レシピ発行
プロジェクト内で作成したレシピは発行することができます。発行したレシピはレシピ一覧で確認でき、YAML/JSONでダウンロードやそのレシピからジョブを作成することも可能です。
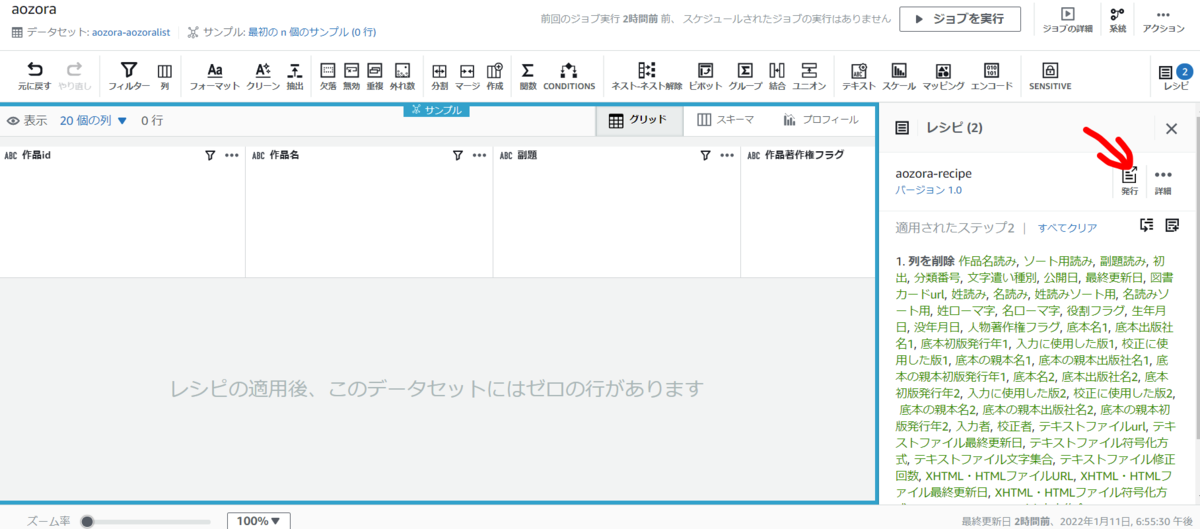
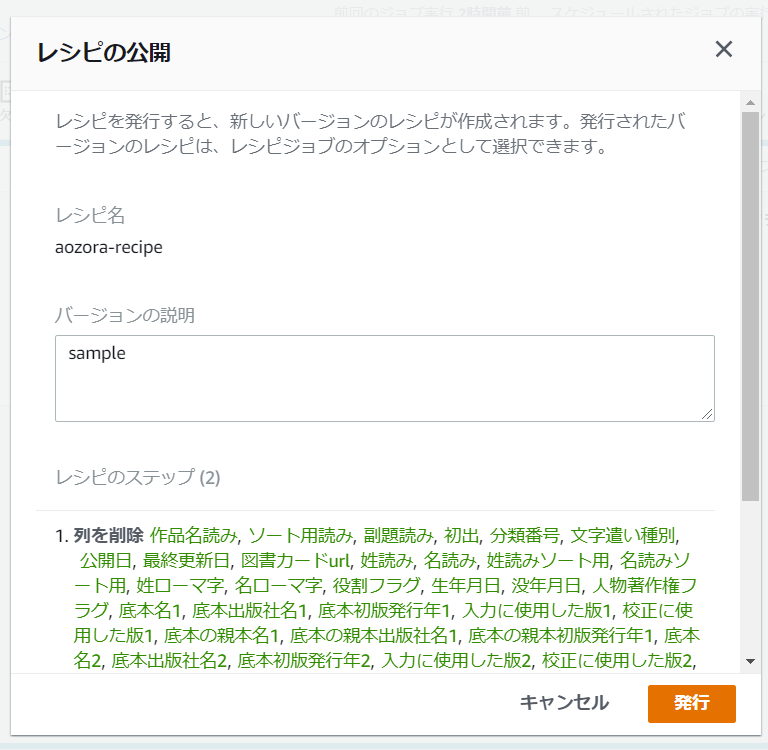
レシピのインポート
レシピはプロジェクト内で1から作るだけでなく、インポートして編集することも可能です。レシピの ・・・ から「レシピをインポート」します。
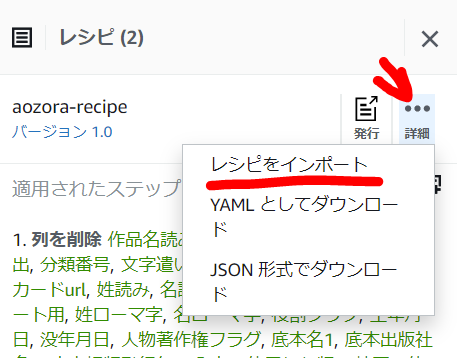
インポートするレシピを選択し。
アベンドか上書きを選択し「次へ」。
ステップの検証がされると「インポート」。
ジョブ作成
プロジェクト内でレシピが完成したらジョブを作成します。「ジョブを作成」をクリック。
ジョブ名と出力先・出力形式を指定します。今回はS3を指定していますがRedshiftやAuroraも可能です。
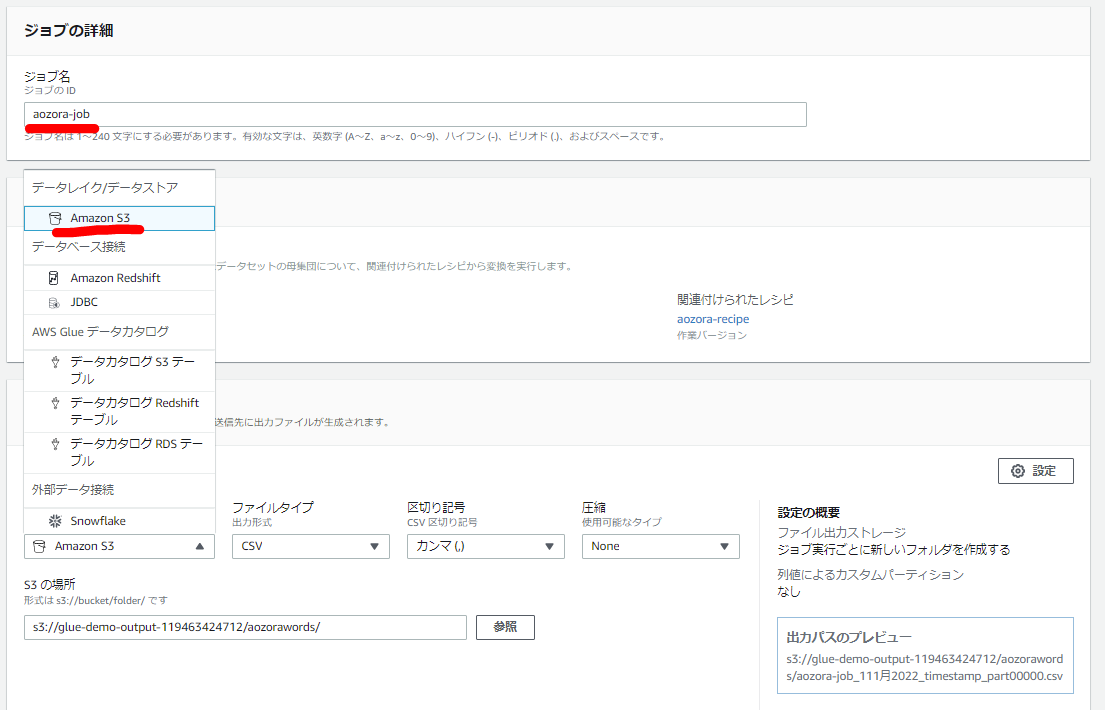
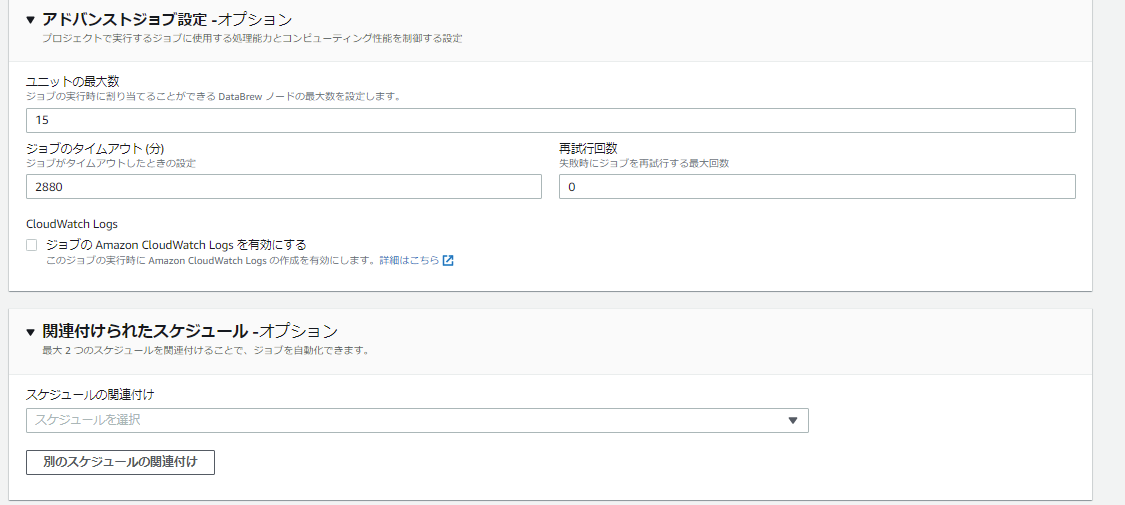
ジョブを実行するノード数やジョブのタイムアウト・再試行回数も指定できます。今回はノード数を15としそのほかはデフォルトとします。スケジュールを設定し定期実行も可能です。
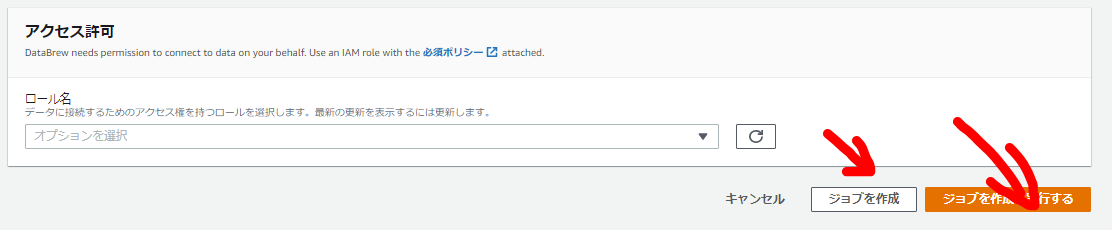
最後にIAMロールを指定し「ジョブを作成」もしくは「ジョブを作成し実行する」。
ジョブ実行
前の手順で「ジョブを作成し実行する」すればジョブ作成とともに実行されます。「ジョブを作成」した場合はジョブ一覧から作成したジョブを選択し「ジョブを実行」。
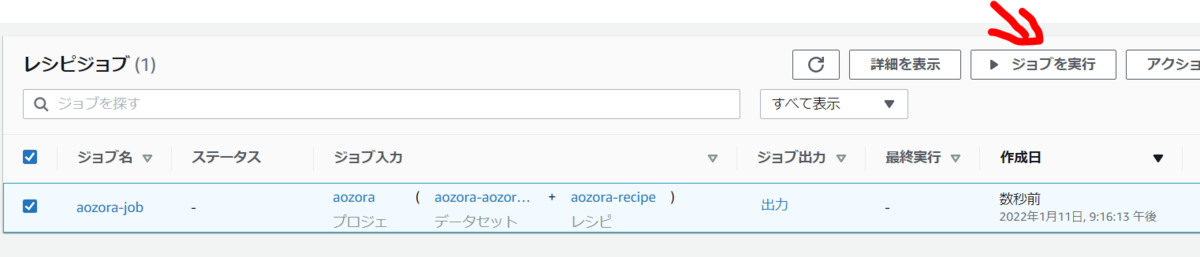
ジョブ一覧からジョブ名をクリックすると実行履歴が確認でき、ジョブのステータスや実行時間が確認できます。
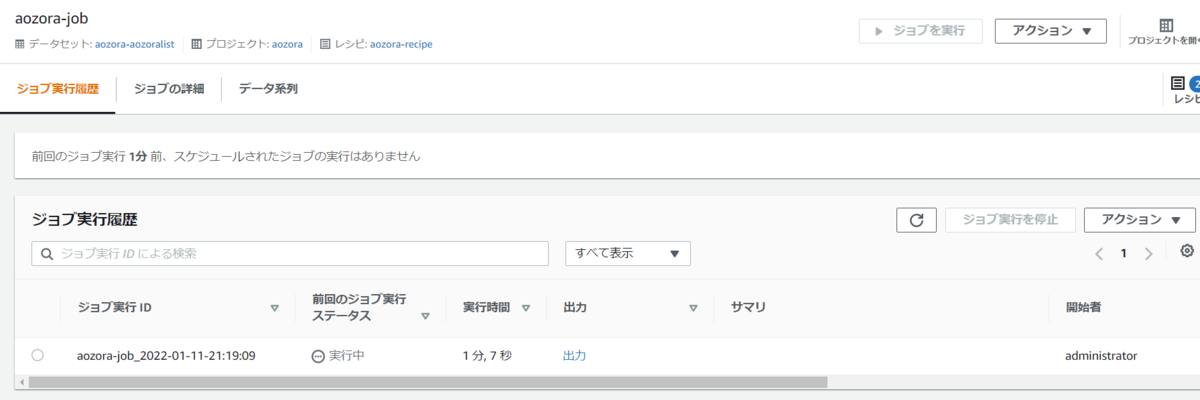
ジョブのステータスが「成功」となれば完了です。
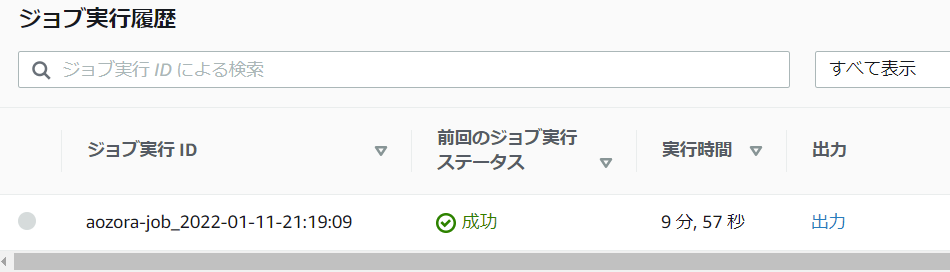
結果を確認してみる
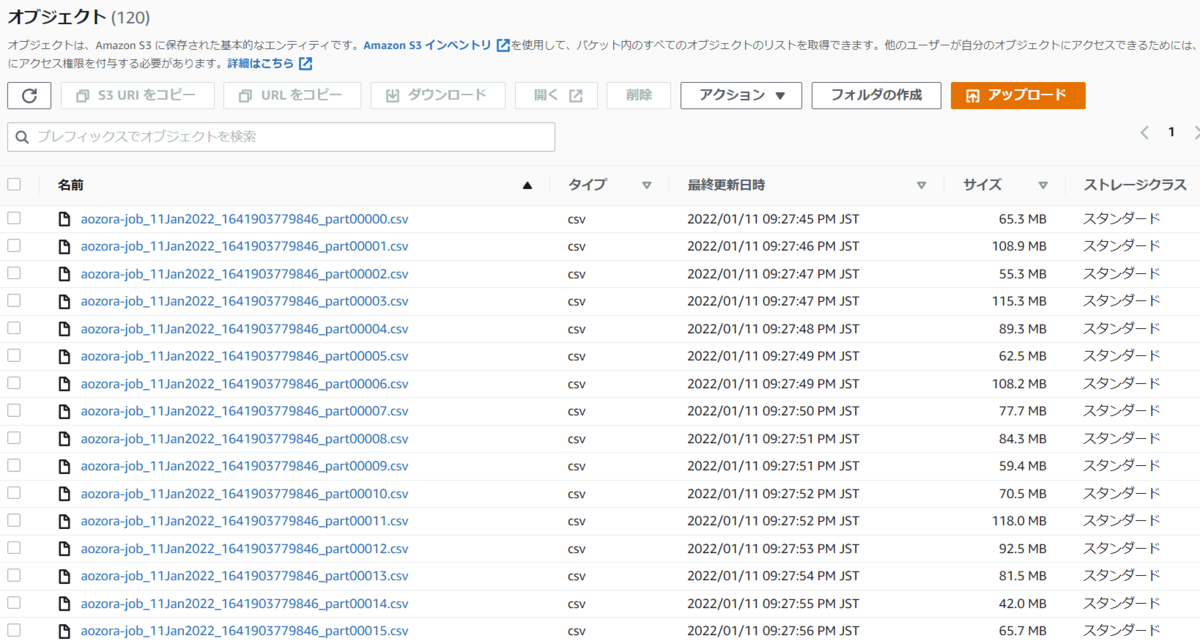
今回は出力先はS3としましたが、出力先のフォルダを見てみると以下のように複数のcsvが出力されます。AWS Glue DataBrewは裏であれが使用されているためです。あれは分散処理のフレームワークであるため、S3を出力先とした場合はこのように出力ファイルが分かれてしまいます。出力に対してAthenaでクエリをかけたりする場合には問題ないかもしれませんが、1つのファイルで出力が必要といった場合は合わないかもしれません。
まとめ
いかがでしたでしょうか。AWS Glue DataBrewはビジュアルで比較的簡単にデータ処理のジョブが実装できます。あらかじめ用意されてる処理が豊富なのでたいていの要件はカバーできそうで、非エンジニアでも簡単に扱えそうです。一方でDBへの接続やIAM権限などの設定もあり、この辺りは素人では理解が難しいのでAWSに詳しいエンジニアのサポートが必要になるでしょう。
Yusuke Mine(書いた記事を見る)
I get drunk but it's not enough 'Cause the morning comes and you're not my baby.