

Amazon SageMaker Inference Recommenderとは?
aws.amazon.com aws.amazon.com docs.aws.amazon.com
Amazon SageMakerにおいてリアルタイム推論を利用する場合、インスタンスタイプを選択します。MLOpsの中で悩ましいことの1つはこのインスタンスタイプの選択です。Amazon SageMakerはデータサイエンティストや機械学習エンジニアにとって便利な開発・実行環境でありますが、実際のところ各ジョブやエンドポイントではインスタンスが稼働するので、インフラ(特にサーバーのパフォーマンスとコスト)について考慮する必要がありました。Amazon SageMakerのMLインスタンスも安くはないので推論のパフォーマンスを保ちつつコストを最適化したいですが、これまでは実際にデプロイしていくらか試験を実施する必要がありました。
Amazon SageMaker Inference Recommenderは負荷テストを自動で実行し、コストが最小・パフォーマンスが最大となるインスタンスタイプを選択することができます。EC2にはすでにAWS Compute Optimizerという機能がありました。あちらもコスト削減とパフォーマンス向上のためにインスタンスタイプを推奨してくれる機能であります。Amazon SageMaker Inference Recommenderもこれに似ていますが、ちょっと違っています。Amazon SageMaker Inference Recommenderの特徴はエンドポイントへのデプロイ前に負荷試験を実施し最適なインスタンスタイプを確認できるということです。AWS Compute Optimizerは運用中のインスタンスの各種メトリクスから最適なインスタンスタイプを提案してくれますが、こちらはデプロイ前にパフォーマンスを測定できます。デプロイ前と言っていますが、実際にはMLOpsの中でInference Recommenderは使用されるので、具体的に言うと運用中の本番環境へのデプロイ前になります。推奨されるインスタンスタイプが簡単に確認できるようになったことで、データサイエンティストや機械学習エンジニア`は、Amazon SageMakerを利用したMLOpsの中でよりモデルの開発に集中できるというわけです。
試してみた
サンプル
サンプルがすでにAWSから公開されていますのですぐに試すことができます。Amazon SageMaker Inference Recommenderジョブ実行時のパラメータについても解説があります。皆さんもぜひ試してみてください。
今回、Amazon SageMaker Stuidoでサンプルを実行してみました。Amazon SageMaker Studioでは各Amazon SageMaker のリソースを確認することができますが、Amazon SageMaker Inference Recommenderも新たに追加されており、Inference Recommender ジョブのステータスや詳細、結果について簡単に確認することができました。これまでもMLOps向けの機能でAmazon SageMaker Stuidoに統合されているものがありますが、Inference Recommenderについても統合されているというわけです。
ジョブがCompletedとなったら結果を確認できます。推奨されるインスタンスタイプで問題なければ「Create endpoint」ですぐにデプロイできるようです。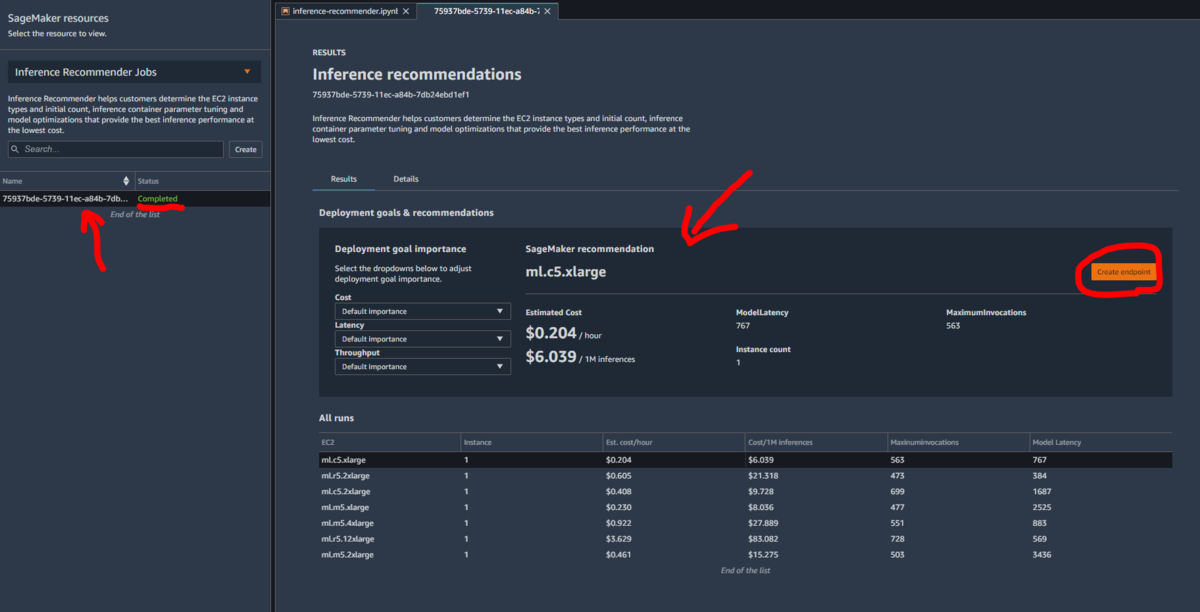
Deployment goal importanceでCost, Latency, Troughputの重要度を選択できますが、今回実施した私の環境では結果はml.c5.xlargeが一番の推奨のまま変わらずでした。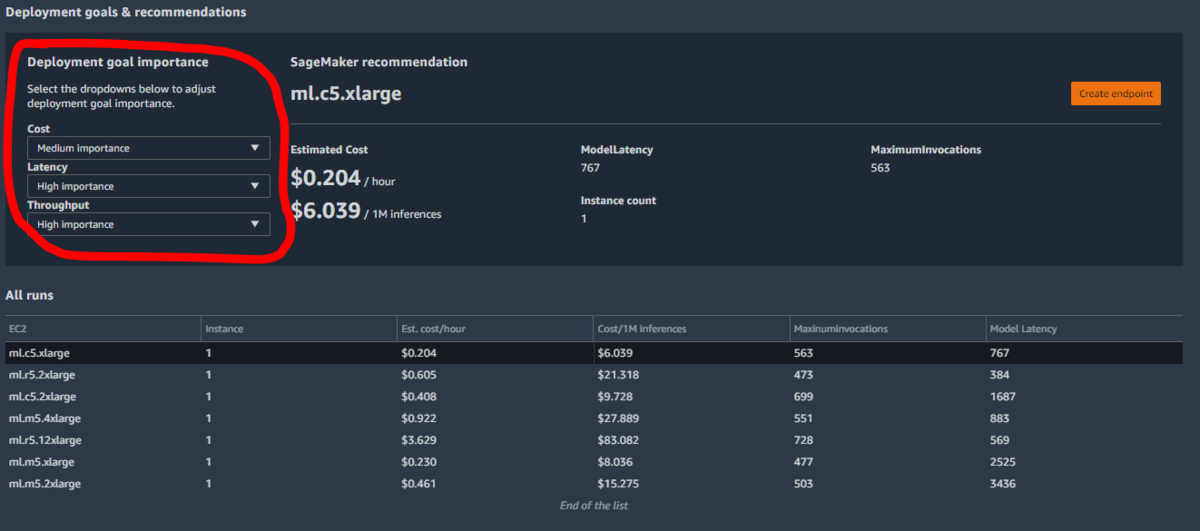
カスタムテスト
"Advanced test"でより本番要件に近い負荷試験を実施することもできます。このサンプルではインスタンスタイプをml.m5.xlarge、EnvironmentParameterRangesで環境変数OMP_NUM_THREADS を["2", "4"]で指定しています。目標のレイテンシーを100msとしています。このサンプルでは環境変数をどちらの値で指定するのがよいかを確認することができます。以下はサンプルからの引用です。
{略}
advanced_response = client.create_inference_recommendations_job(
JobName=str(advanced_job),
JobDescription="JobDescription",
JobType="Advanced",
RoleArn=role,
InputConfig={
"ModelPackageVersionArn": model_package_version_response["ModelPackageArn"],
"JobDurationInSeconds": 7200,
"EndpointConfigurations": [
{
"InstanceType": "ml.m5.xlarge",
"EnvironmentParameterRanges": {
"CategoricalParameterRanges": [{"Name": "OMP_NUM_THREADS", "Value": ["2", "4"]}]
},
}
],
"ResourceLimit": {"MaxNumberOfTests": 2, "MaxParallelOfTests": 1},
"TrafficPattern": {
"TrafficType": "PHASES",
"Phases": [{"InitialNumberOfUsers": 1, "SpawnRate": 1, "DurationInSeconds": 120}],
},
},
StoppingConditions={
"MaxInvocations": 300,
"ModelLatencyThresholds": [{"Percentile": "P95", "ValueInMilliseconds": 100}],
},
)
{略}
感想
Amazon SageMaker Studioと統合されていることで結果がビジュアルでわかりやすく、また環境変数まで指定してテストできるのは大変便利だと感じました。
まとめ
いかがでしたでしょうか。MLOpsの中で利用できるインフラ寄りの機能はこれまでありませんでしたが、Amazon SageMaker Inference Recommenderの登場で機械学習エンジニア・データサイエンティストはこれまで以上にインフラを気にせずモデルの開発に集中できるでしょう。
Yusuke Mine(書いた記事を見る)
I get drunk but it's not enough 'Cause the morning comes and you're not my baby.