

こんにちは。
DevOpsが好きなアプリケーションサービス部の兼安です。
今回からしばらく「Amazon Neptuneで始める初めてのグラフDB」というテーマで連載記事を書いていこうと思います。
本記事はその1回目です。
- Amazon Neptuneで始める初めてのグラフDB① NeptuneクラスターとNotebookの作成
- Amazon Neptuneで始める初めてのグラフDB② Gremlinを用いたグラフデータの基本操作
- Amazon Neptuneで始める初めてのグラフDB③ Amazon NeptuneとTom Sawyer Graph Database Browserとの接続
- Amazon Neptuneで始める初めてのグラフDB④ G.V()を用いてローカル端末からAmazon Neptuneに接続する
- Amazon Neptuneで始める初めてのグラフDB⑤ Amazon OpenSearch Serviceと連携した全文検索
- 本連載記事の目標
- 第1回目の目標
- グラフDBとは
- グラフDBのモデルとクエリ言語
- 今回作成する環境
- Amazon Neptuneの設定
- Jupyter Notebookの設定
- IaC
- NotebookからNeptuneクラスターにアクセスする
- 次回に向けて
- 参考
本連載記事の目標
- Amazon Neptuneに対する基本的な操作・認証・運用方法を習得する
- Amazon Neptuneの全文検索を実装する
第1回目の目標
- Amazon Neptuneクラスターを起動する
- PythonでAmazon Neptuneクラスターに対してクエリ実行可能な環境を用意する
- 上記をできる限りIaCで構築する
グラフDBとは
作業に入る前に、グラフDBとは何かについて簡単に記載しておきます。
グラフDBは、データ同士の繋がりとその関係性を表現するのに適したデータベースです。
繋がりと関係性は、リレーショナルデータベース(RDB)でも表現できますが、グラフDBはこの用途に特化しており、新たな繋がりとその関係性を追加するのにテーブル構造を変更する必要はありません。
グラフDBのモデルとクエリ言語
グラフDBには複数のモデルとクエリ言語があります。
最もメジャーなものはプロパティグラフモデルで、アクセスにはGremlinというクエリ言語を使用します。
本連載記事では、プロパティグラフとGremlinをベースに進めていきます。
| モデル | 構造 | クエリ言語 |
|---|---|---|
| プロパティグラフ | - ノード(頂点)とエッジ(辺)で構成 - ノードとエッジに任意のプロパティを持つ - ノード: エンティティやオブジェクト - エッジ: ノード間の関係 |
- Gremlin (Apache TinkerPop) - Cypher (Neo4j) |
| RDF | - トリプル形式(主語、述語、目的語) - 主語: リソースやエンティティ - 述語: 関係やプロパティ - 目的語: 関係の相手やプロパティの値 |
- SPARQL |
今回作成する環境
Amazon Neptuneクラスターとそれに接続するプログラムの実行環境として、Jupyter Notebookを用意します。
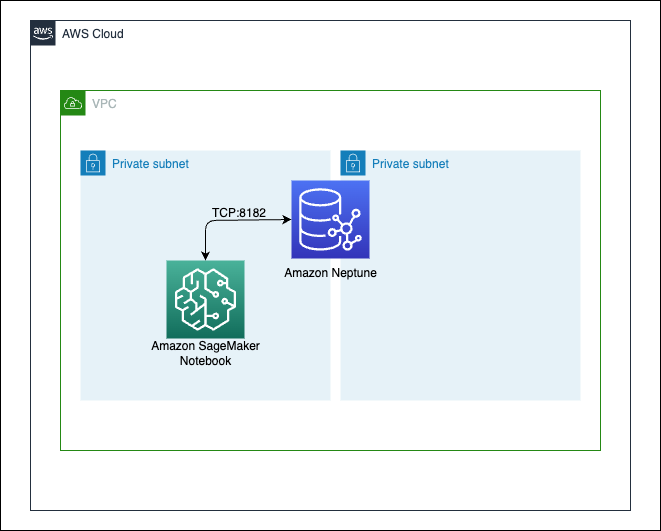
Amazon Neptuneの設定
NeptuneはServerlessにはせず、インスタンスを一つ作ってクラスターとします。
NeptuneのIAM認証は本記事では無効化して構築します。
IAM認証の有効化別の記事で説明します。
Jupyter Notebookの設定
NotebookはNeptuneの画面から作成できますが、今回はSageMaker側の汎用ノートブックを使用します。
個人的にインストール作業を通じて理解を深めたかったためです。
ご了承ください。
以下のページのPython を使用して汎用 SageMaker ノートブックを Neptune に接続するを参考に進めます。
IaC
AWS CloudFormationテンプレートを使用します。
以下のページを参考にしています。
graphdb_1_vpc.yml、graphdb_2_neptune.yaml、graphdb_3_notebook.yamlが、それぞれVPC、Neptuneクラスター、Notebookを作成するCloudFormationテンプレートです。
graphdb_1_vpc.ymlには、BastionSecurityGroupとTomSawyerSecurityGroupがありますが、これらは次回以降で作成する踏み台サーバーと可視化ツールのためのセキュリティグループです。
今回は使用しません。
Neptuneクラスターは、Notebook・可視化ツール・踏み台サーバーを経由していないアクセスは許可しません。
以下の記述が該当部分です。
NeptuneSecurityGroup: Type: "AWS::EC2::SecurityGroup" Properties: GroupName: !Sub "${ServiceName}-${StageName}-neptune-cluster-sg" GroupDescription: "Enable access to Neptune" VpcId: !Ref VPC SecurityGroupIngress: - IpProtocol: tcp FromPort: 8182 ToPort: 8182 SourceSecurityGroupId: !Ref NotebookSecurityGroup - IpProtocol: tcp FromPort: 8182 ToPort: 8182 SourceSecurityGroupId: !Ref BastionSecurityGroup - IpProtocol: tcp FromPort: 8182 ToPort: 8182 SourceSecurityGroupId: !Ref TomSawyerSecurityGroup Tags: - Key: "Name" Value: !Sub "${ServiceName}-${StageName}-neptune-cluster-sg" - Key: "ServiceName" Value: !Ref ServiceName - Key: "StageName" Value: !Ref StageName
8182はNeptuneクラスターのデフォルトポート番号です。
NotebookからNeptuneクラスターにアクセスする
IaCを実行するとNotebookが作成されます。
SageMakerの画面からNotebookインスタンスを開きます。
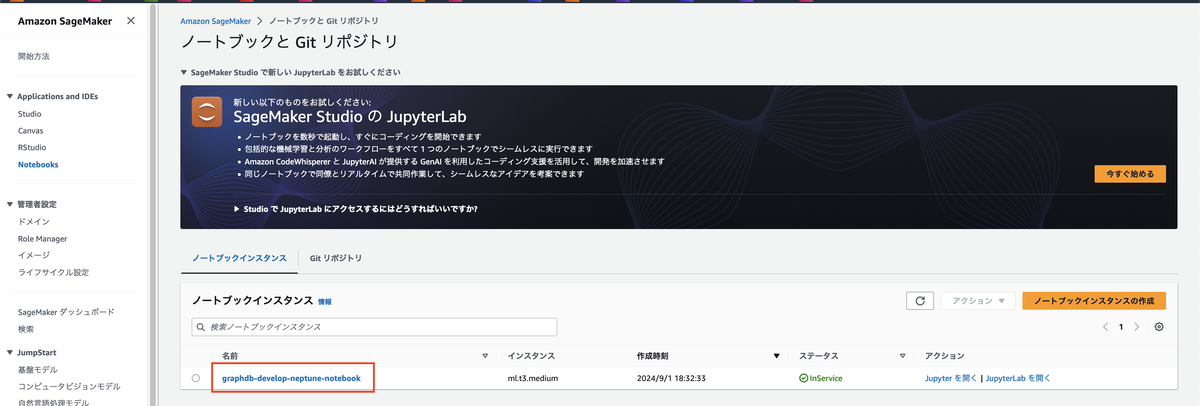
Notebookインスタンスの画面でJupyterを開くをクリックします。

Newで、conda_python3をクリックします。
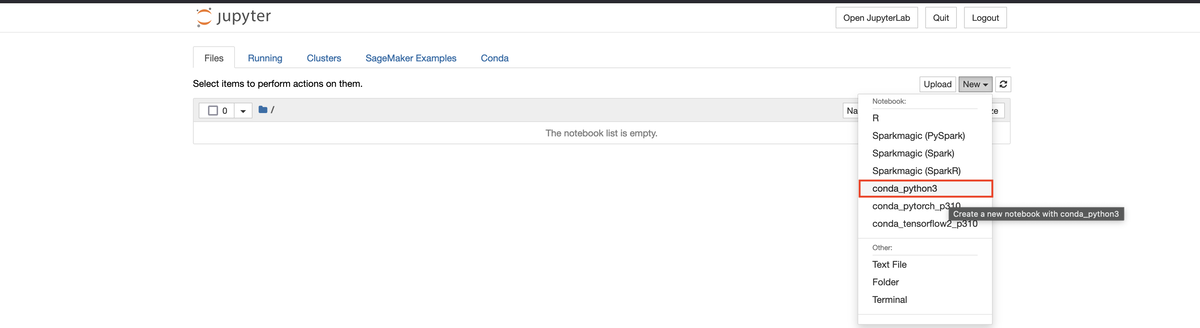
Notebookの編集画面に遷移したら、以下のページのプログラムを参考に実行します。
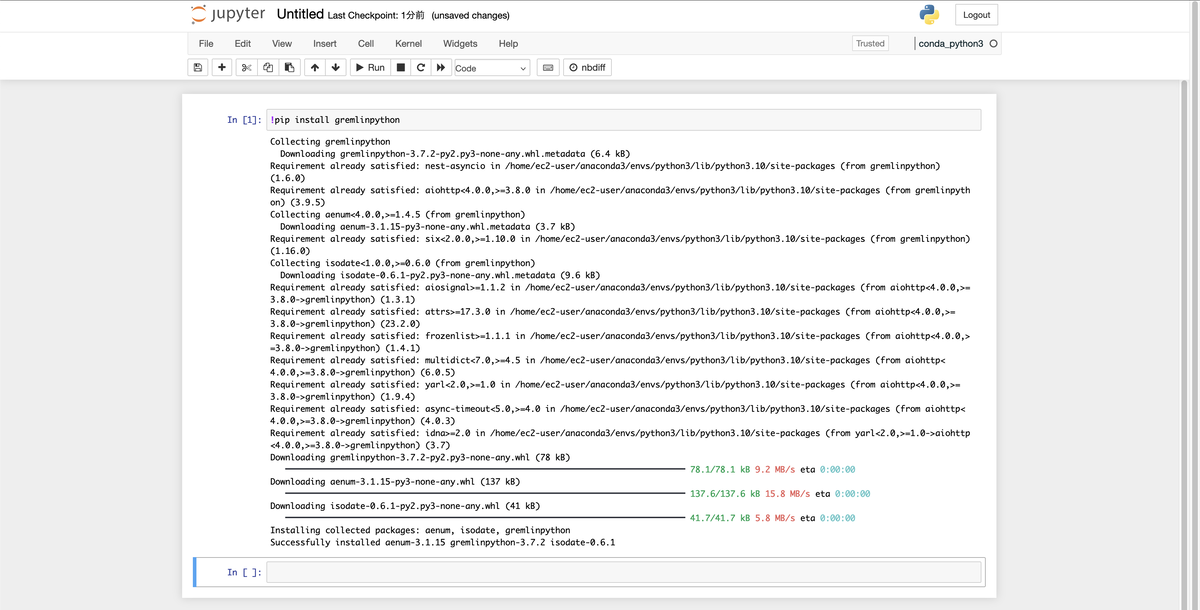
今回はNeptuneに対してGremlinでクエリを実行するため、gremlinpythonをインストールします。
!pip install gremlinpython
次にプログラムを実行してNeptuneクラスターにアクセスします。
from gremlin_python import statics from gremlin_python.structure.graph import Graph from gremlin_python.process.graph_traversal import __ from gremlin_python.process.strategies import * from gremlin_python.driver.driver_remote_connection import DriverRemoteConnection from gremlin_python.driver.aiohttp.transport import AiohttpTransport from gremlin_python.process.traversal import * import os port = 8182 server = '{Neptuneクラスターのエンドポイント}' endpoint = f'wss://{server}:{port}/gremlin' print(endpoint) graph=Graph() connection = None try: connection = DriverRemoteConnection(endpoint, 'g', transport_factory=lambda: AiohttpTransport(call_from_event_loop=True)) g = graph.traversal().withRemote(connection) results = (g.V().hasLabel('airport') .sample(10) .order() .by('code') .local(__.values('code', 'city').fold()) .toList()) for i, c in enumerate(results, 1): print("%3d %4s %s" % (i, c[0], c[1])) finally: if connection is not None: connection.close()
基本的に上記参考ページと同じプログラムですが、失敗時にコネクションが残る可能性があるため、finallyでコネクションの切断処理を入れました。
{Neptuneクラスターのエンドポイント}の部分には、Neptuneクラスターのエンドポイントを入力します。
このプログラムはReadのみ行うため、書き込み・読み込みいずれのエンドポイントでも使用できます。
エンドポイントを入力後、プログラムを実行して結果がPrintされるか、エラーが発生しなければ成功です。
接続不可の場合、403エラーなどが発生します。
次回に向けて
今回はここまでです。
次回は 用意した環境を使ってデータの書き込みや検索を行ってみます。
参考
AWS公式には、Amazon Neptuneを一気に起動するテンプレートが存在します。
本記事では段階的に進めるため、自前でCloudFormationテンプレートを作成しましたが、Amazon NeptuneとJupyter Notebookを一度に作成することも可能です。
すぐに試したい方は、以下のページを参考にしてください。
兼安 聡(執筆記事の一覧)
アプリケーションサービス本部 DS3課
2025 Japan AWS Top Engineers (AI/ML Data Engineer)
2025 Japan AWS All Certifications Engineers
2026 AWS Community Builders(2年目)
Certified ScrumMaster
PMP
広島在住です。今日も明日も修行中です。
X(旧Twitter)