

こんにちは🐱
技術課の山本です。
様々な AWS サービスで作成を推奨している CloudWatch アラームを、簡単に作れるようになったようです。
例えば、 EC2 (AWSサービス)でインスタンス (仮想サーバ) の CPU 使用率のメトリクスが 80% 以上になった場合に通知する CloudWatch Alarm を作成することは、 AWS のベストプラクティスとして推奨されています。こういった CloudWatch アラーム を作る簡単な方法が提供されたようです。
2023/10/16 の以下アップデートです。
これまで
これまでは CloudWatch アラーム の作成画面から、メトリクスを探し選択して、自分でしきい値を決めていました。
この方法は少し手間でした。
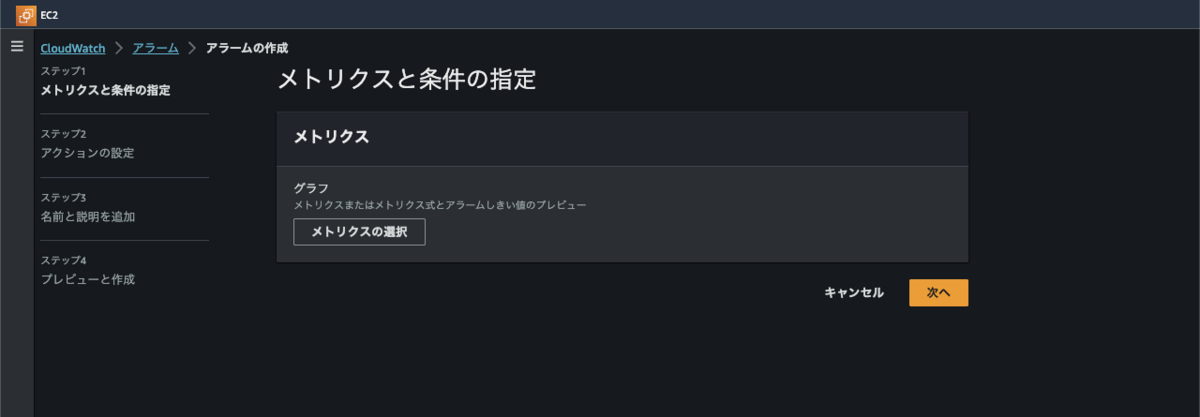
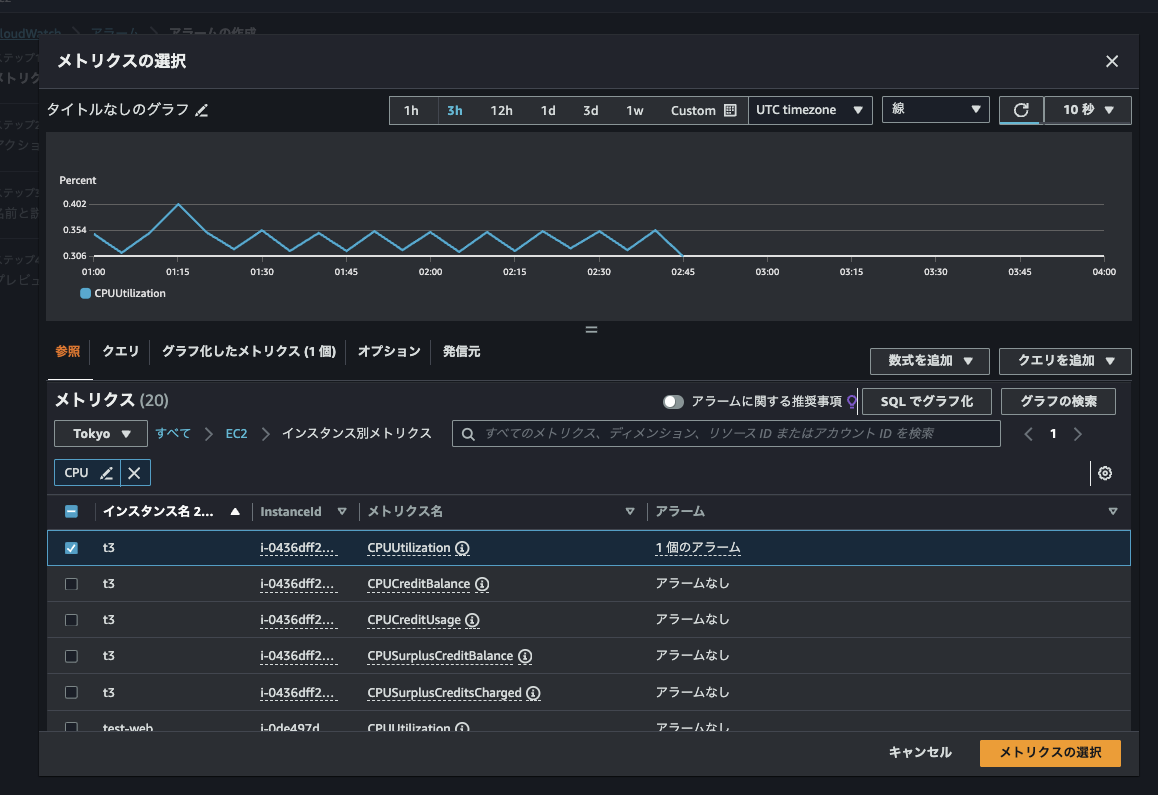
メトリクスの画面から、選択したメトリクスでアラームを作成できたりもします。
対象のメトリクスにチェックを入れ、「グラフ化したメトリクス」画面から CloudWatch アラームを作成する必要がありました。
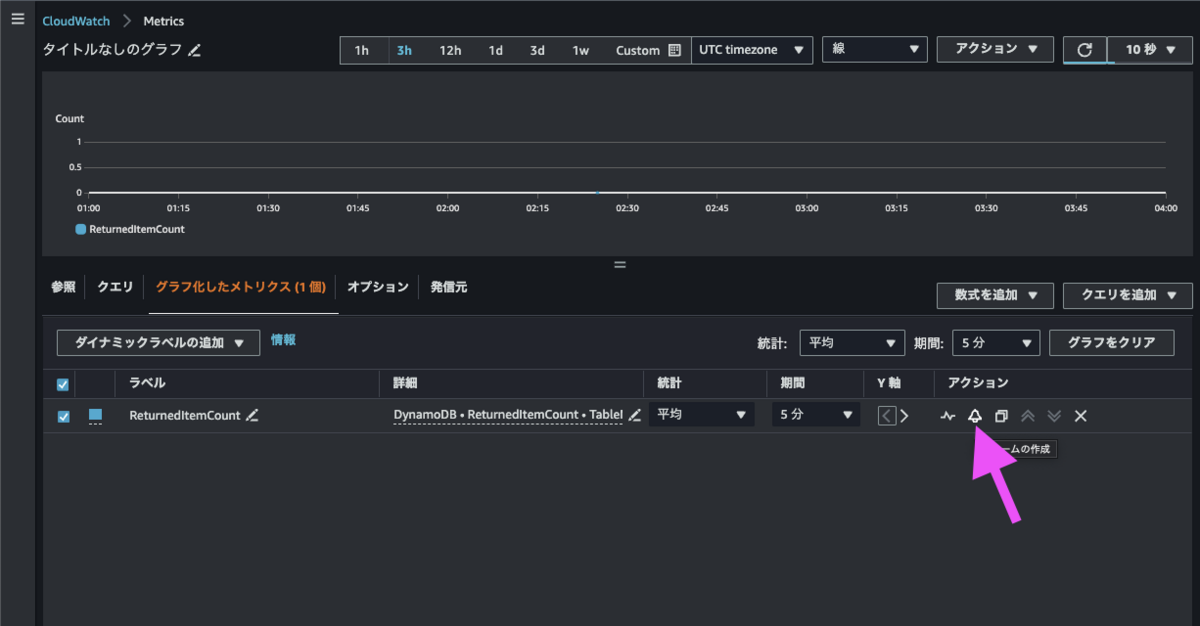
試してみた
ドキュメントの該当ページは以下になるようです。
CloudWatch は、すぐに使えるアラームの推奨事項を提供します。これらは、他の AWS サービスによって公開されるメトリクス用に作成することをお勧めする CloudWatch アラームです。これらの推奨事項は、監視のベスト プラクティスに従うためにアラームを設定する必要があるメトリックを特定するのに役立ちます。推奨事項では、設定するアラームしきい値も提案されます。これらの推奨事項に従うと、AWS インフラストラクチャの重要な監視を見逃すことがなくなります。
アラームの推奨事項を見つけるには、CloudWatch コンソールのメトリクス セクションを使用し、アラームの推奨事項フィルターの切り替えを選択します。コンソールで推奨アラームに移動して推奨アラームを作成すると、CloudWatch はアラーム設定の一部を事前に入力できます。一部の推奨アラームでは、アラームのしきい値も事前に入力されています。コンソールを使用して、推奨されるアラームのコードとしてのインフラストラクチャのアラーム定義をダウンロードし、このコードを使用して AWS CloudFormation、AWS CLI、または Terraform でアラームを作成することもできます。
作成したアラームには、CloudWatch で作成した他のアラームと同じ料金が発生します。推奨事項を使用しても追加料金はかかりません。詳細については、「Amazon CloudWatch の料金」を参照してください。
以下の作成方法があるようですね。
- 推奨となるアラームを AWS マネジメントコンソールでポチポチ作る方法
- 推奨となるアラームの 定義をダウンロードして CloudFormation / AWS CLI / Terraform を使用して作成する方法
ドキュメントの記載を参考にしながら試してみます。
推奨となるアラームを AWS マネジメントコンソールでポチポチ作る方法
CloudWatch コンソール の「すべてのメトリクス」画面から、「アラームに関する推奨事項」を ON にします。
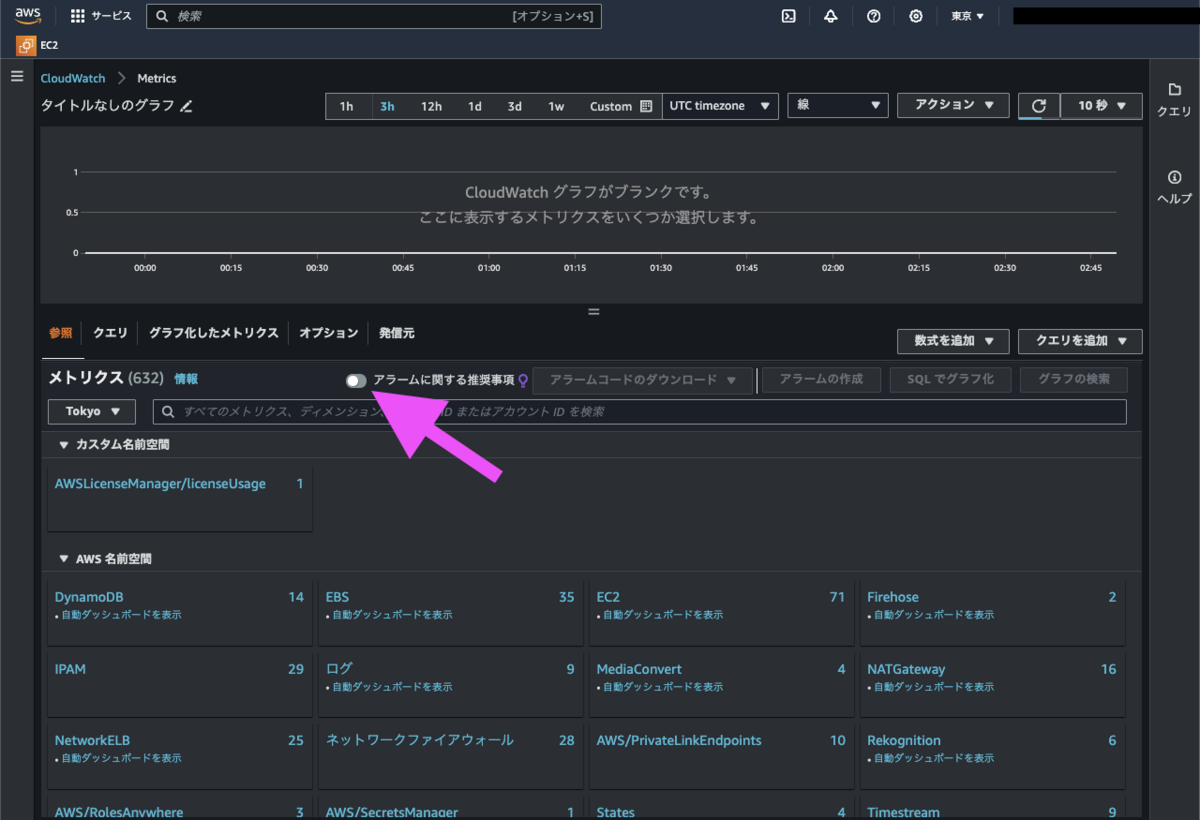
すると、推奨事項があるメトリクスのみが表示されました。

EC2 の 「インスタンス別メトリクス」 をクリックして見てみましょう。
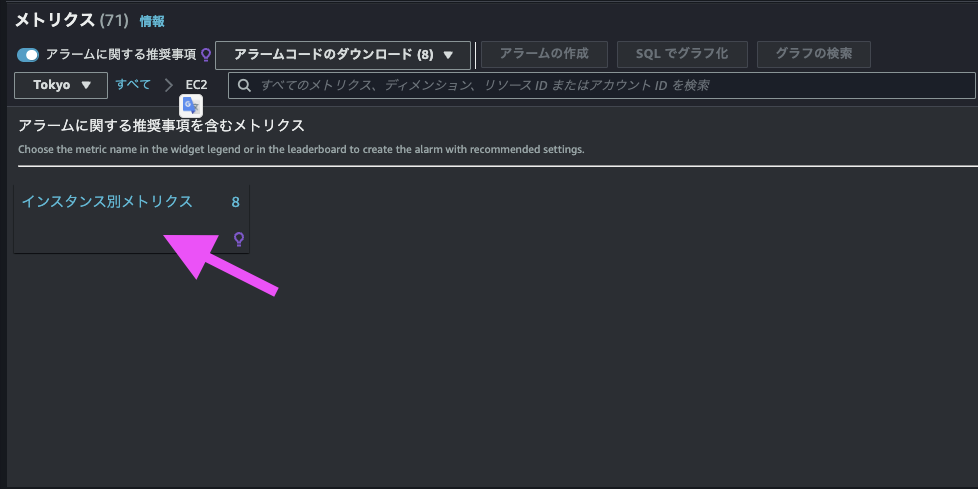
一番上のインスタンスの CPU使用率 (CPUUtilization) メトリクスの横にある「アラームに関する推奨事項」列の「詳細を表示」をクリックしましょう。
すると「アラームの作成」「アラームソースを表示 」ボタンが出てきました。「アラームの作成」ボタンを押してみます。
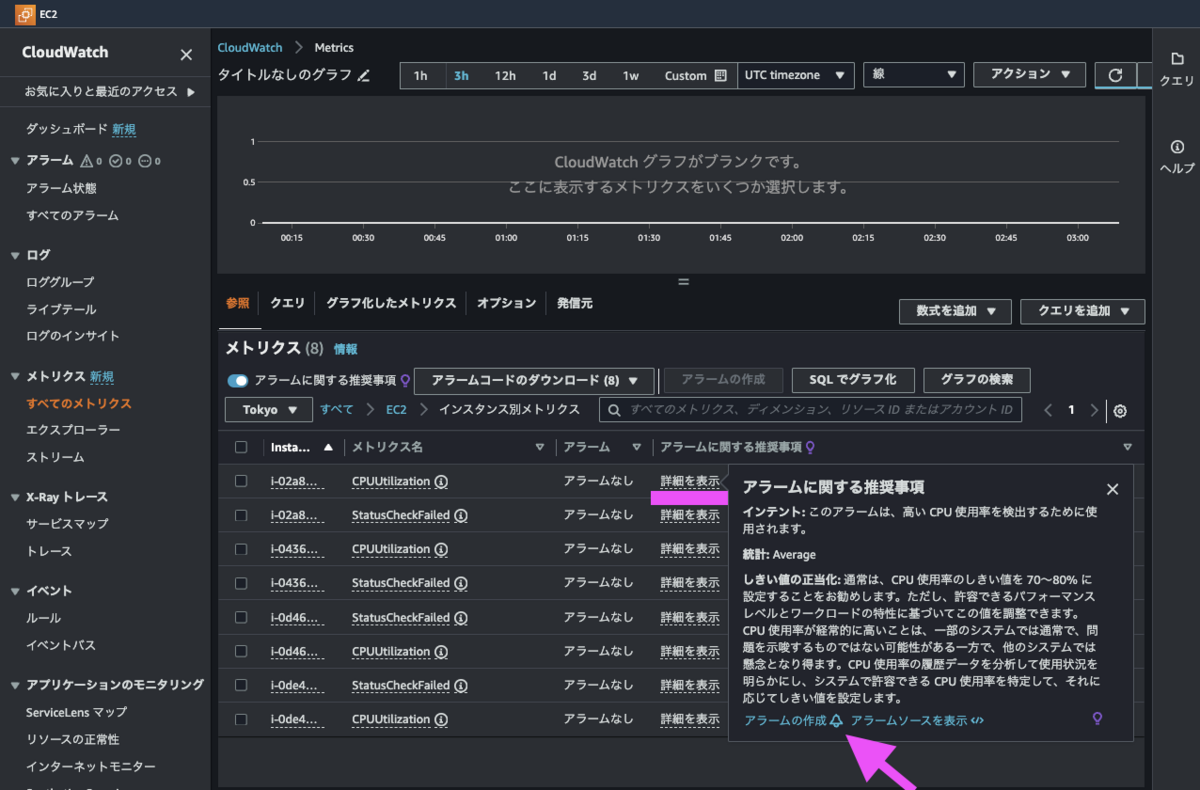
アラームの作成画面に飛びました。
メトリクスの画面で選択した EC2 インスタンスの CPU使用率 (CPUUtilization) の平均が 80 % より大きくなった場合に検知するアラームになるように自動入力してくれています。
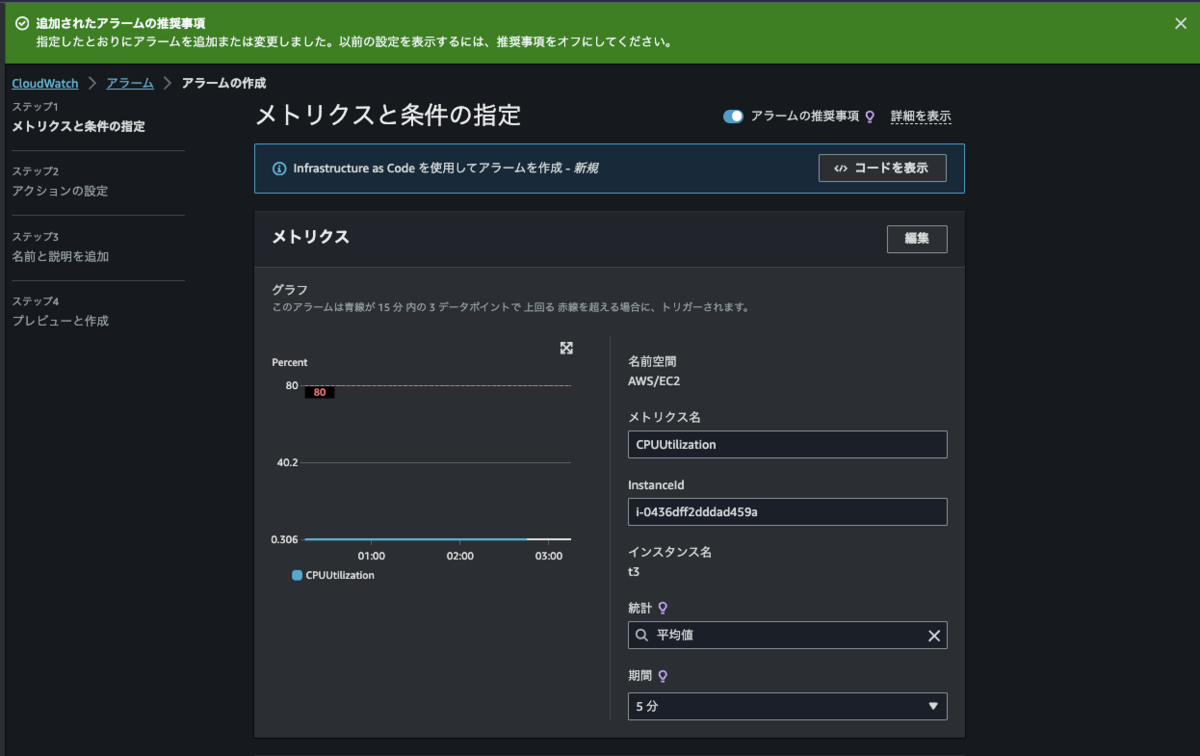
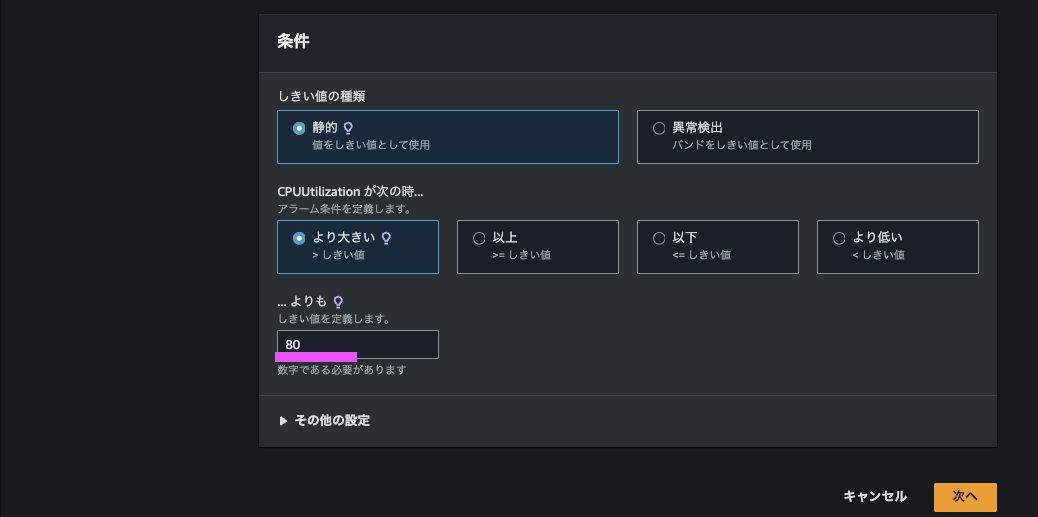
通知先を自分で設定します。
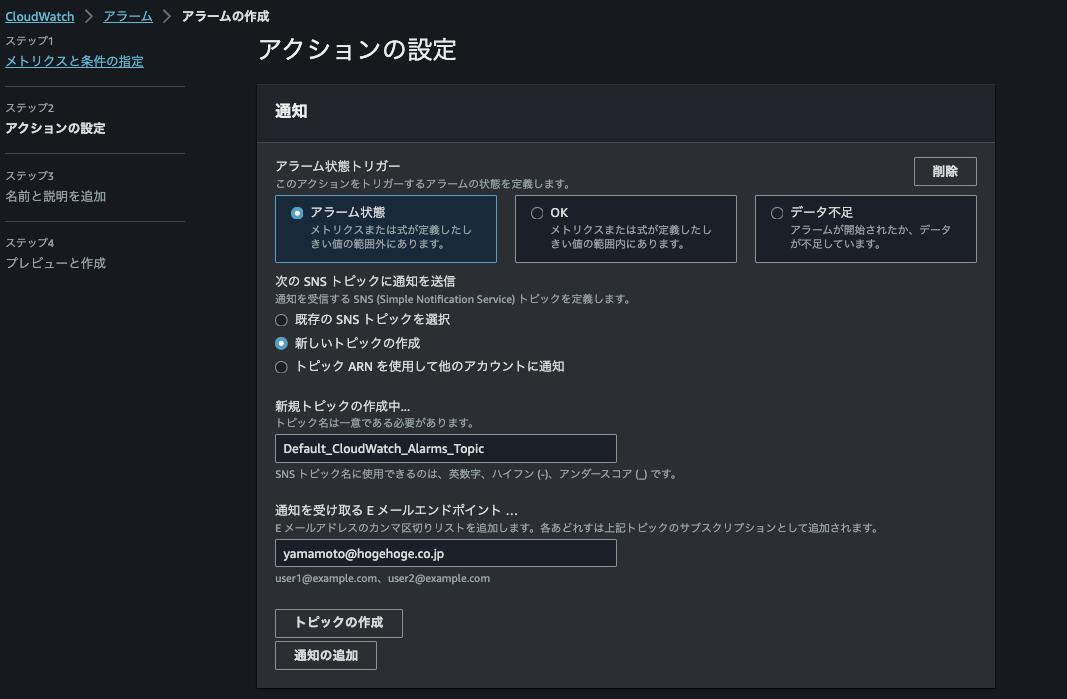
アラーム名を自分で設定します。
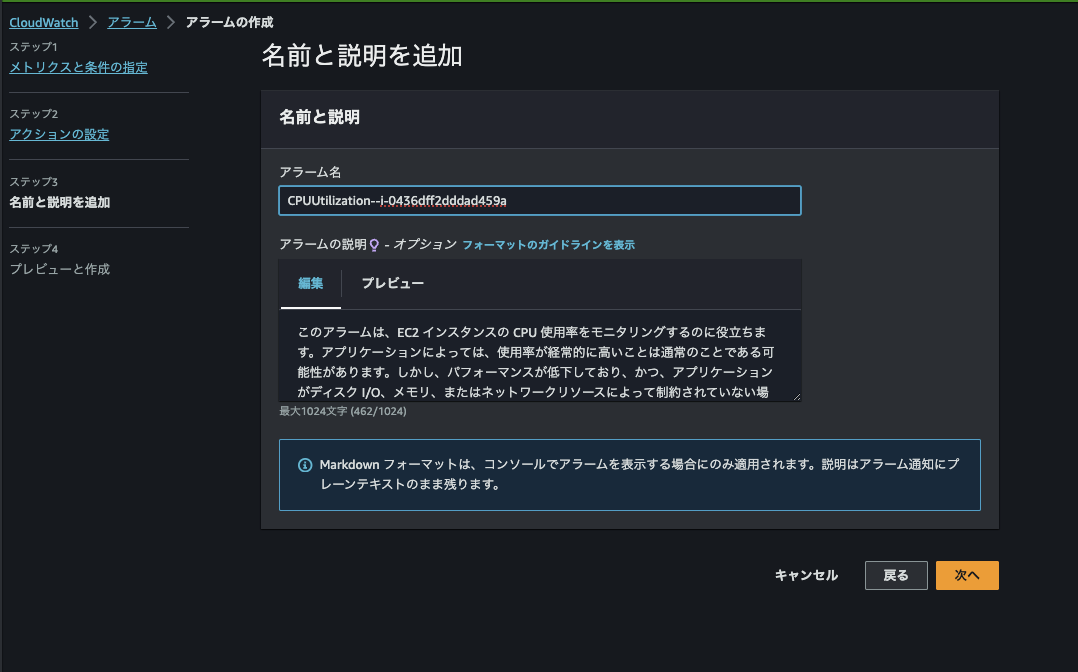
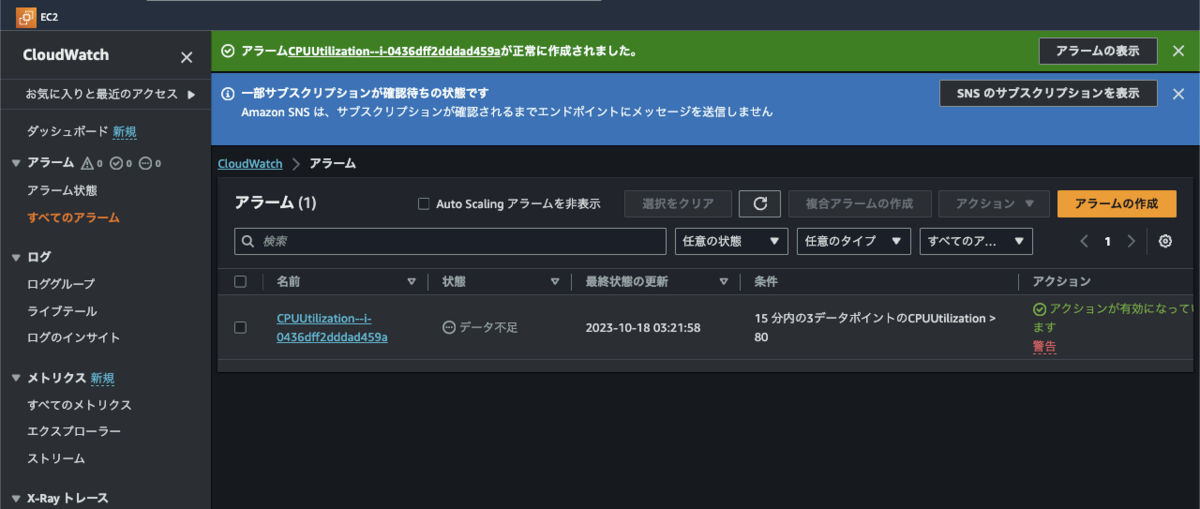
アラームを作成できました!簡単ですね。
推奨となるアラームの 定義をダウンロードして CloudFormation / AWS CLI / Terraform を使用して作成する方法
上で紹介した手順の途中にあった、「アラームソースを表示 」ボタンを押すと、CloudFormation (Json/Yaml) 、AWS CLI 、Terraform のソースコードをコピーしたりダウンロードできました。Terraform もあるんですね!
コードで作成する場合は、アラーム名 (AlarmName) も作ってくれました。
通知 (AlarmActions) は自分でコードを書く必要があります。


以下に AWS マネジメントコンソールからコピーしてきた CPU使用率 (CPUUtilization) を検知するアラームのコードを参考に載せておきます。
CloudFormation (Json)
{ "Type": "AWS::CloudWatch::Alarm", "Metadata": { "Intent": "このアラームは、高い CPU 使用率を検出するために使用されます。", "ThresholdJustification": "通常は、CPU 使用率のしきい値を 70~80% に設定することをお勧めします。ただし、許容できるパフォーマンスレベルとワークロードの特性に基づいてこの値を調整できます。CPU 使用率が経常的に高いことは、一部のシステムでは通常で、問題を示唆するものではない可能性がある一方で、他のシステムでは懸念となり得ます。CPU 使用率の履歴データを分析して使用状況を明らかにし、システムで許容できる CPU 使用率を特定して、それに応じてしきい値を設定します。" }, "Properties": { "AlarmName": "AWS/EC2 CPUUtilization InstanceId=i-hogehoge", "AlarmDescription": "このアラームは、EC2 インスタンスの CPU 使用率をモニタリングするのに役立ちます。アプリケーションによっては、使用率が経常的に高いことは通常のことである可能性があります。しかし、パフォーマンスが低下しており、かつ、アプリケーションがディスク I/O、メモリ、またはネットワークリソースによって制約されていない場合、CPU が上限に達しているということは、リソースのボトルネックやアプリケーションのパフォーマンス上の問題を示している可能性があります。CPU 使用率が高いことは、CPU を多用するインスタンスへのアップグレードが必要であることを示している可能性があります。詳細モニタリングが有効化されている場合は、この期間を 300 秒ではなく 60 秒に変更できます。詳細については、[インスタンスの詳細モニタリングを有効または無効にする](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-cloudwatch-new.html)を参照してください。", "MetricName": "CPUUtilization", "Namespace": "AWS/EC2", "Statistic": "Average", "Dimensions": [ { "Name": "InstanceId", "Value": "i-hogehoge" } ], "Period": 300, "EvaluationPeriods": 3, "DatapointsToAlarm": 3, "Threshold": 80, "ComparisonOperator": "GreaterThanThreshold", "TreatMissingData": "missing", "ActionsEnabled": false, "OKActions": [], "AlarmActions": [], "InsufficientDataActions": [] } }
CloudFormation (Yaml)
Type: AWS::CloudWatch::Alarm Metadata: Intent: このアラームは、高い CPU 使用率を検出するために使用されます。 ThresholdJustification: 通常は、CPU 使用率のしきい値を 70~80% に設定することをお勧めします。ただし、許容できるパフォーマンスレベルとワークロードの特性に基づいてこの値を調整できます。CPU 使用率が経常的に高いことは、一部のシステムでは通常で、問題を示唆するものではない可能性がある一方で、他のシステムでは懸念となり得ます。CPU 使用率の履歴データを分析して使用状況を明らかにし、システムで許容できる CPU 使用率を特定して、それに応じてしきい値を設定します。 Properties: AlarmName: AWS/EC2 CPUUtilization InstanceId=i-hogehoge AlarmDescription: このアラームは、EC2 インスタンスの CPU 使用率をモニタリングするのに役立ちます。アプリケーションによっては、使用率が経常的に高いことは通常のことである可能性があります。しかし、パフォーマンスが低下しており、かつ、アプリケーションがディスク I/O、メモリ、またはネットワークリソースによって制約されていない場合、CPU が上限に達しているということは、リソースのボトルネックやアプリケーションのパフォーマンス上の問題を示している可能性があります。CPU 使用率が高いことは、CPU を多用するインスタンスへのアップグレードが必要であることを示している可能性があります。詳細モニタリングが有効化されている場合は、この期間を 300 秒ではなく 60 秒に変更できます。詳細については、[インスタンスの詳細モニタリングを有効または無効にする](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-cloudwatch-new.html)を参照してください。 MetricName: CPUUtilization Namespace: AWS/EC2 Statistic: Average Dimensions: - Name: InstanceId Value: i-hogehoge Period: 300 EvaluationPeriods: 3 DatapointsToAlarm: 3 Threshold: 80 ComparisonOperator: GreaterThanThreshold TreatMissingData: missing ActionsEnabled: false OKActions: [] AlarmActions: [] InsufficientDataActions: []
AWS CLI
aws cloudwatch put-metric-alarm \ --alarm-name 'AWS/EC2 CPUUtilization InstanceId=i-hogehoge' \ --alarm-description 'このアラームは、EC2 インスタンスの CPU 使用率をモニタリングするのに役立ちます。アプリケーションによっては、使用率が経常的に高いことは通常のことである可能性があります。しかし、パフォーマンスが低下しており、かつ、アプリケーションがディスク I/O、メモリ、またはネットワークリソースによって制約されていない場合、CPU が上限に達しているということは、リソースのボトルネックやアプリケーションのパフォーマンス上の問題を示している可能性があります。CPU 使用率が高いことは、CPU を多用するインスタンスへのアップグレードが必要であることを示している可能性があります。詳細モニタリングが有効化されている場合は、この期間を 300 秒ではなく 60 秒に変更できます。詳細については、[インスタンスの詳細モニタリングを有効または無効にする](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-cloudwatch-new.html)を参照してください。' \ --no-actions-enabled \ --metric-name 'CPUUtilization' \ --namespace 'AWS/EC2' \ --statistic 'Average' \ --dimensions '[{"Name":"InstanceId","Value":"i-hogehoge"}]' \ --period 300 \ --evaluation-periods 3 \ --datapoints-to-alarm 3 \ --threshold 80 \ --comparison-operator 'GreaterThanThreshold' \ --treat-missing-data 'missing'
Terraform
resource "aws_cloudwatch_metric_alarm" "cloudwatch_alarm" { # Intent : "このアラームは、高い CPU 使用率を検出するために使用されます。" # Threshold Justification : "通常は、CPU 使用率のしきい値を 70~80% に設定することをお勧めします。ただし、許容できるパフォーマンスレベルとワークロードの特性に基づいてこの値を調整できます。CPU 使用率が経常的に高いことは、一部のシステムでは通常で、問題を示唆するものではない可能性がある一方で、他のシステムでは懸念となり得ます。CPU 使用率の履歴データを分析して使用状況を明らかにし、システムで許容できる CPU 使用率を特定して、それに応じてしきい値を設定します。" alarm_name = "AWS/EC2 CPUUtilization InstanceId=i-hogehoge" alarm_description = "このアラームは、EC2 インスタンスの CPU 使用率をモニタリングするのに役立ちます。アプリケーションによっては、使用率が経常的に高いことは通常のことである可能性があります。しかし、パフォーマンスが低下しており、かつ、アプリケーションがディスク I/O、メモリ、またはネットワークリソースによって制約されていない場合、CPU が上限に達しているということは、リソースのボトルネックやアプリケーションのパフォーマンス上の問題を示している可能性があります。CPU 使用率が高いことは、CPU を多用するインスタンスへのアップグレードが必要であることを示している可能性があります。詳細モニタリングが有効化されている場合は、この期間を 300 秒ではなく 60 秒に変更できます。詳細については、[インスタンスの詳細モニタリングを有効または無効にする](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-cloudwatch-new.html)を参照してください。" actions_enabled = false ok_actions = [] alarm_actions = [] insufficient_data_actions = [] metric_name = "CPUUtilization" namespace = "AWS/EC2" statistic = "Average" period = 300 dimensions = { InstanceId = "i-hogehoge" } evaluation_periods = 3 datapoints_to_alarm = 3 threshold = 80 comparison_operator = "GreaterThanThreshold" treat_missing_data = "missing" }
まとめ
様々な AWS サービスで作成が推奨になっている CloudWatch アラームを簡単に作れるようになりそうですね。
アラームを作成するためにメトリクスを探したり、メトリクスを選択して「グラフ化したメトリクス」画面を参照しなくても、AWS 推奨のアラームを作成できますね。
しきい値も推奨を出してくれて便利ですし、IaC にも対応しています!
余談
北アルプスに行きたいです。
