

本記事は2022/12/26時点の情報です。
サーバーワークス DS1課の吉岡です。
re:Invent 2022においてAmazon Redshift で Amazon S3 からの自動コピー(プレビュー版)が可能になることが発表されました。
このアップデートに関してまとめたので参考にしていただけたら嬉しいです。
アップデート内容
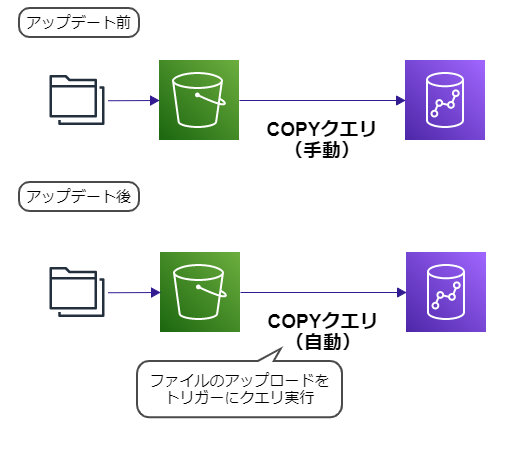
これまでボタンを押しCOPYコマンドを実行することで、Amazon RedshiftのデータベースへS3のファイルのコピーが可能でした。
このアップデートではCOPYコマンドの自動実行が可能になりました。
嬉しいポイント
- ファイルのアップロードで自動的にCOPYコマンドが実行される
プレビュー版環境
このプレビュー版は以下のリージョンで使用できます。
- 米国東部 (バージニア北部)
- 米国東部 (オハイオ)
- 米国西部 (オレゴン)
- アジアパシフィック (東京)
- 欧州 (アイルランド)
- 欧州 (ストックホルム)
Amazon Redshiftに手動でコピーする
まず、これまでのCOPYコマンドの実行方法を説明します。
(自動コピーの方法をいち早く知りたい方はこの章は飛ばしてください)
S3バケットに保存するファイルを作成する
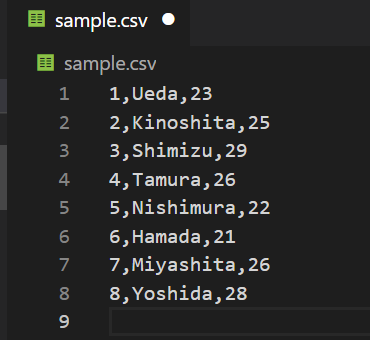
今回は簡易的に以下のCSVファイルを作成しました。
- カラム名はRedshiftで決定するので、CSVファイル上に記載していません。
- ID,NAME,AGEのカラムを想定しています。
S3バケットにファイルをアップロード
作成したCSVファイルをS3バケットにアップロードしました。
IAMロールを作成する
RedShiftがS3バケットのファイルを取り出すためのロールが必要です。
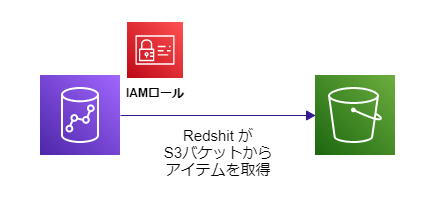 下の記事を参考にIAMロールを作成しました。
下の記事を参考にIAMロールを作成しました。
Amazon Redshiftにクラスターを作成する
RedShiftのクラスターのページから「クラスターを作成」を選択します。
今回は「無料トライアル」を選択します。
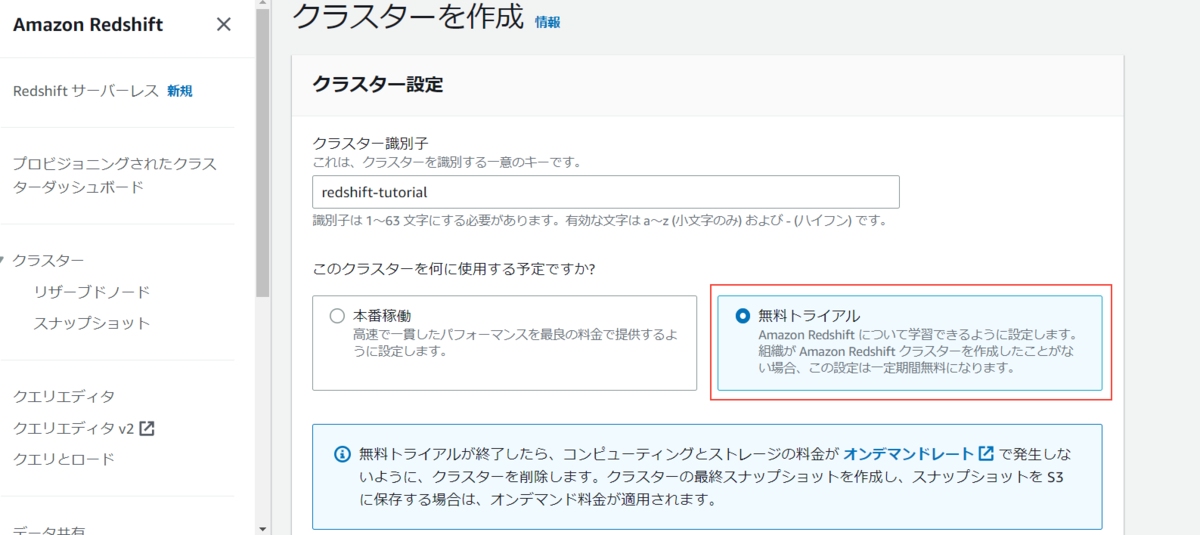
クラスターにIAMロールを付与する
クラスターに作成したIAMロールを付与します。
クラスターのページから「アクション」→「IAMロールの管理」を選択します。
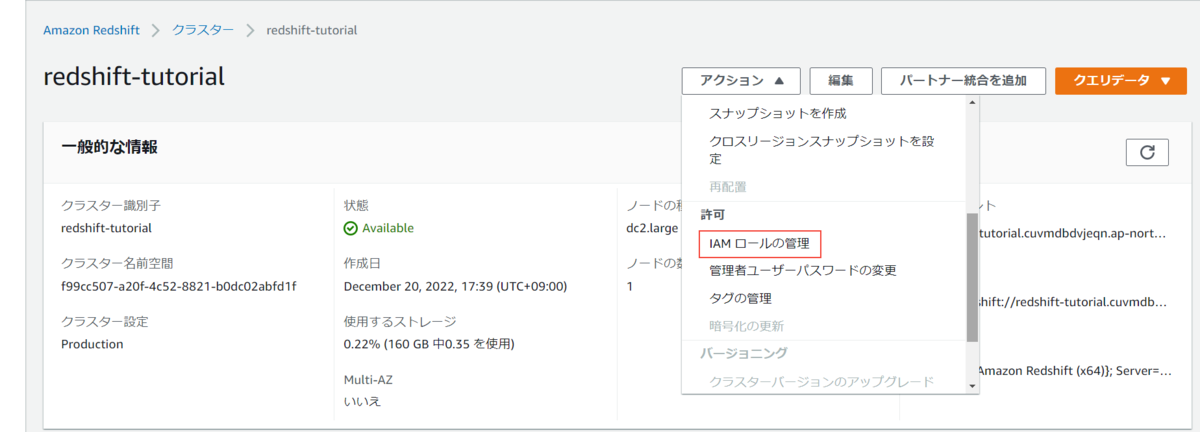
「IAMロールを関連付ける」でIAMロールの付与ができます。
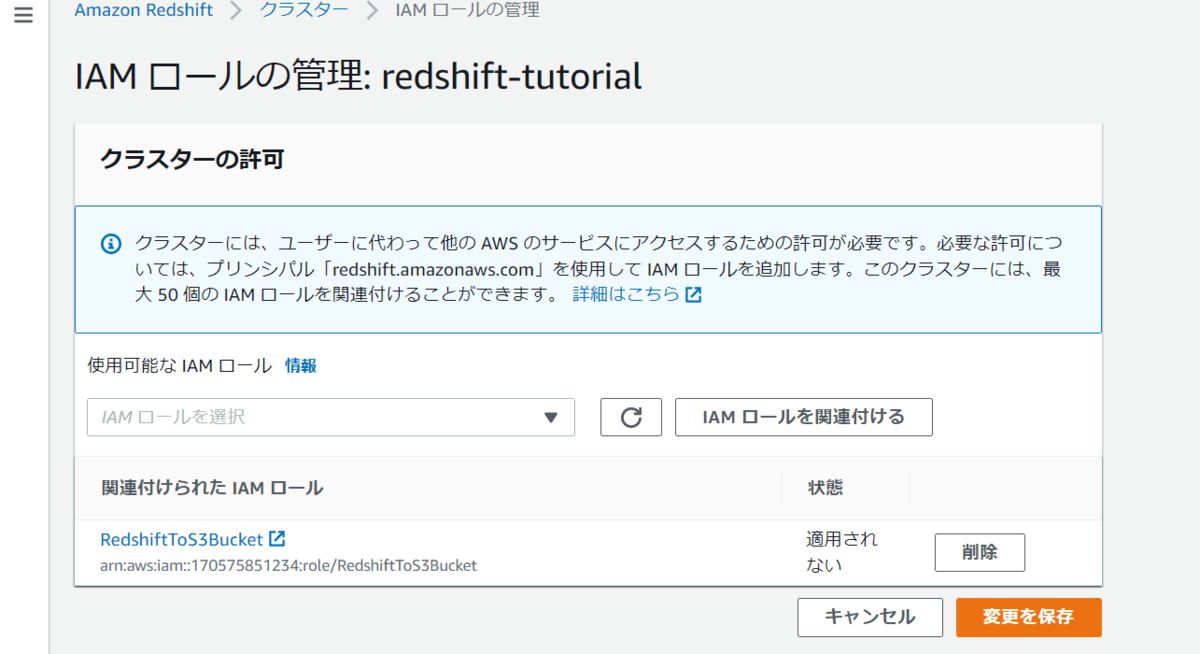
クラスターにデータベースを作成する
「クエリエディタ v2」を選択します。
選択したページでデータベースを作成できます。
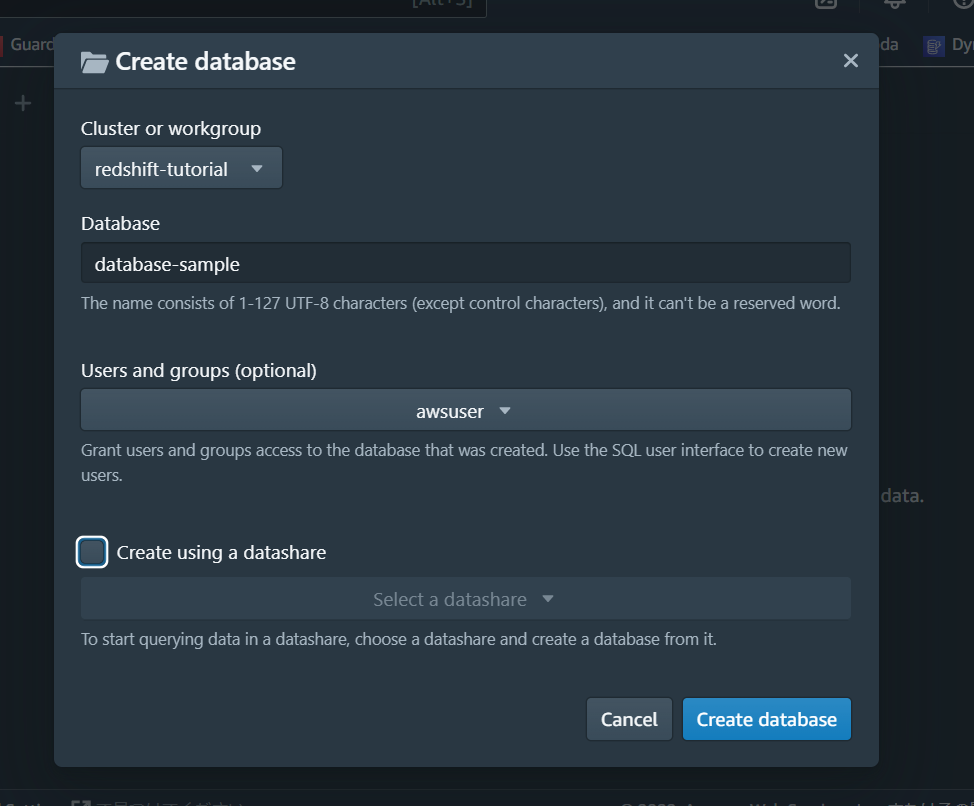
 データベースの名前などを設定します。
データベースの名前などを設定します。
データベースにテーブルを作成する
次にテーブルの作成を選択します。
この作成ページでカラムを設定することができます。
今回は画像の設定でテーブルを作成しました。
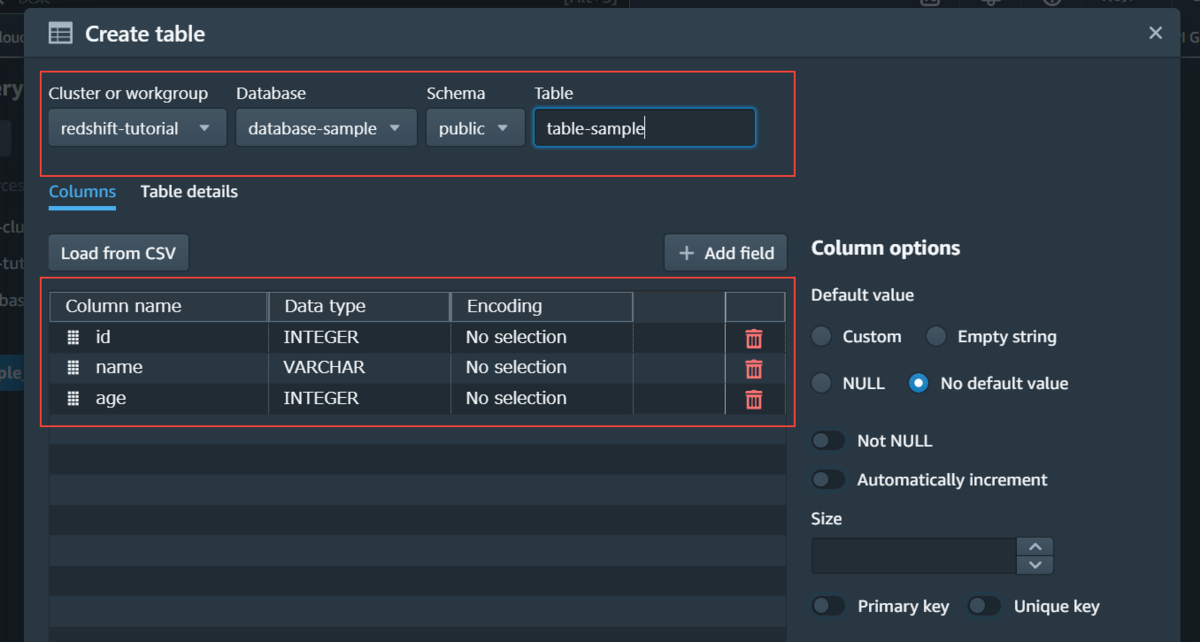
CREATEコマンド
今回はGUIでDDLを作成していますが、DDL内容は以下になります。
CREATE TABLE public.<テーブル名>( id integer, name varchar(16), age intger );
Amazon RedShiftにS3バケットのファイルを読み込ませる
次に3バケット内のファイル内容を、作成したテーブルにコピーします。
「Load data」を選択します。
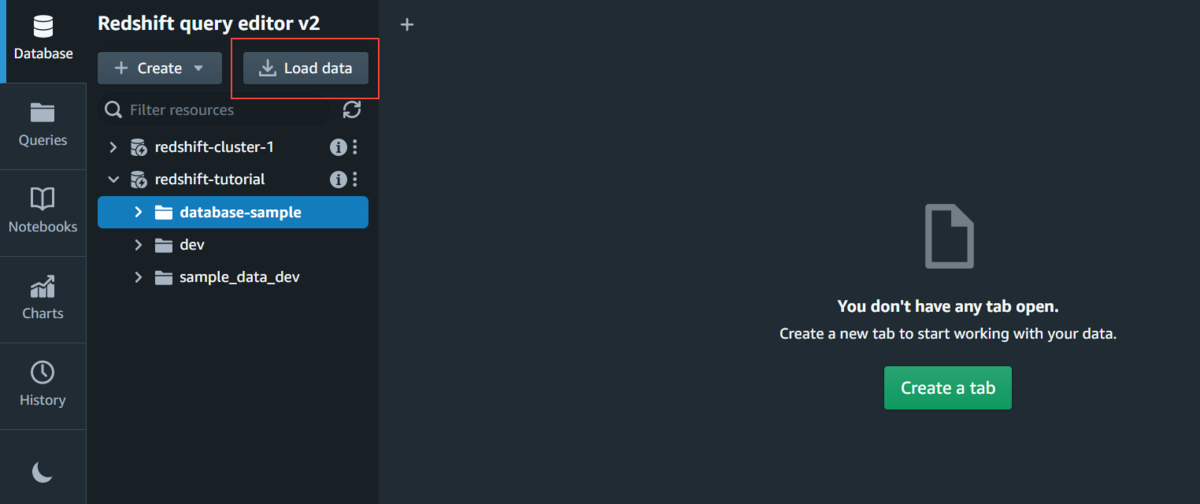
次に、下の画像のように
- S3バケット、ファイルの指定
- アップロードするRedShiftのデータベース・テーブルの指定
- RedShiftに付与するIAMロールの指定
を指定できたら、「Load data」で実行に進んでください。
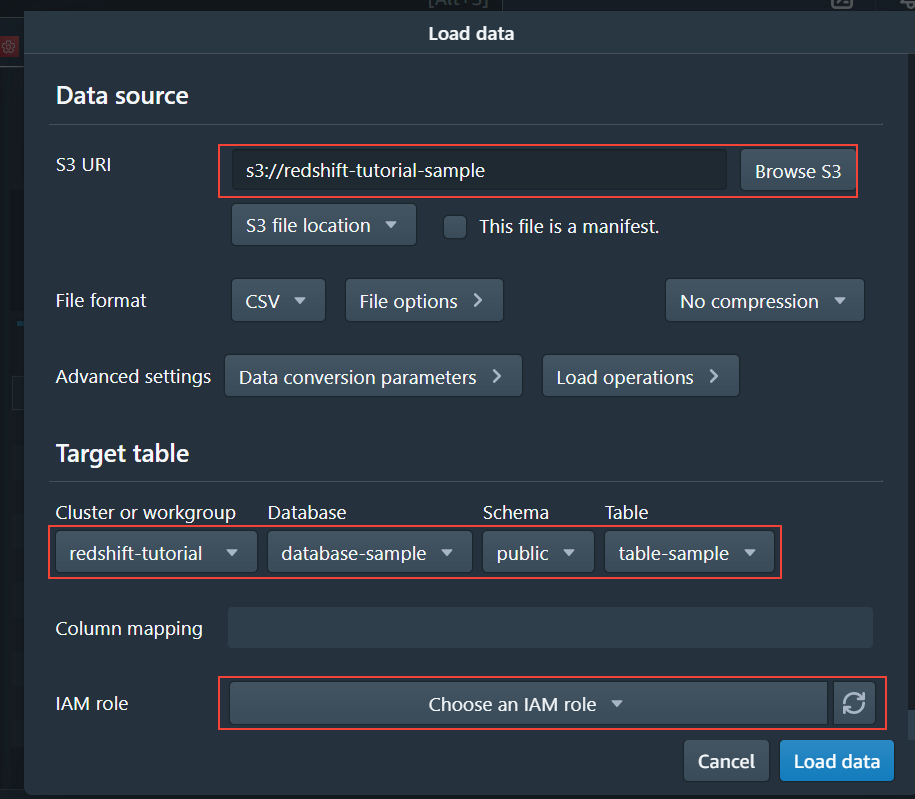
COPYコマンド内容は以下になります。
COPY <データベース名>.public.<テーブル名> FROM <S3バケットディレクトリ> IAM_ROLE <IAMロールARN> FORMAT AS CSV DELIMITER ',' QUOTE '"' REGION AS 'ap-northeast-1'
実行内容の確認
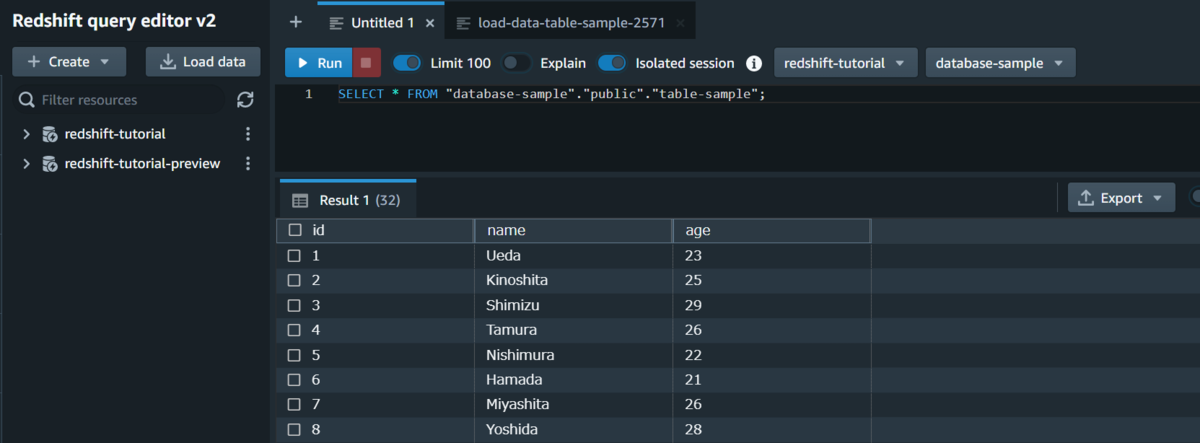
CSVファイルの中身がコピーされているのか確認します。
下期のクエリによって、テーブルの中のアイテムを全て取得できます。
SELECT * FROM <データベース名>."public".<テーブル名>;
下の画像のようにコピーが出来ていることが確認できました。
手動でCOPYコマンドを実行してコピーする方法は以上です。
次章からお待ちかねの自動コピーの紹介です!
エラーが出る場合
確認すべきポイントを以下にまとめました。
- RedShiftのテーブルの形式とCSVファイルの形式が合っているか
- RedShiftに適切なIAMロールが付与できているか
- アップロード時のクラスター、データベース、テーブルの選択が正しいか
Amazon RedShiftに自動コピーを行う
ここから自動コピーの方法について説明します。
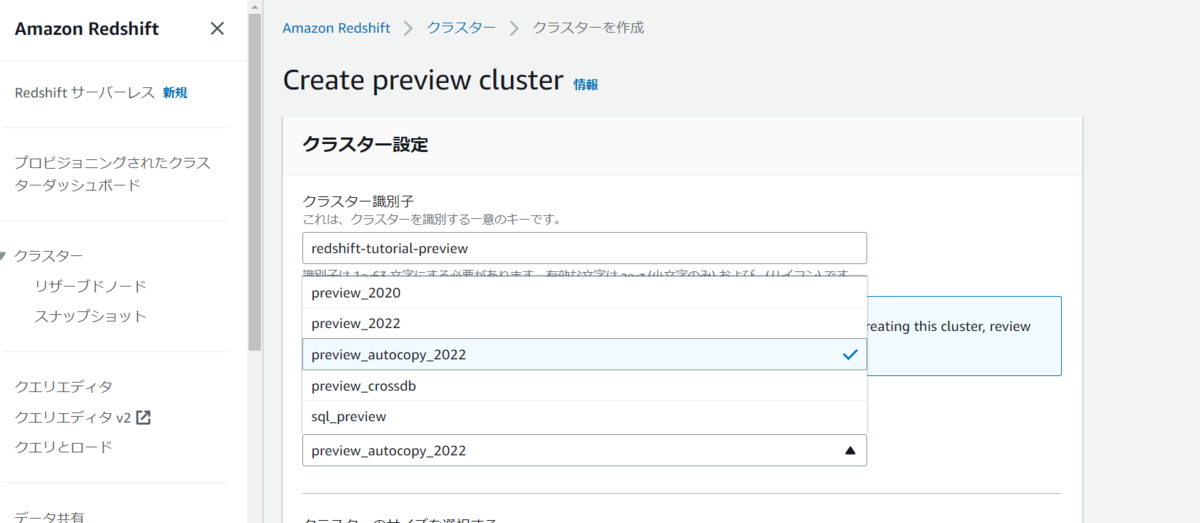
最初に「Create preview cluster」を選択して、プレビュー版の使用に進みます。

クラスターの作成
クラスター作成画面に遷移します。
この時にPreview trackの項目でプレビュー版の選択が可能です。
「preview_autocopy_2022」を選択します。
ここからは前段と同じ方法でクラスター・データベース・テーブルを作成します。
自動コピー実行
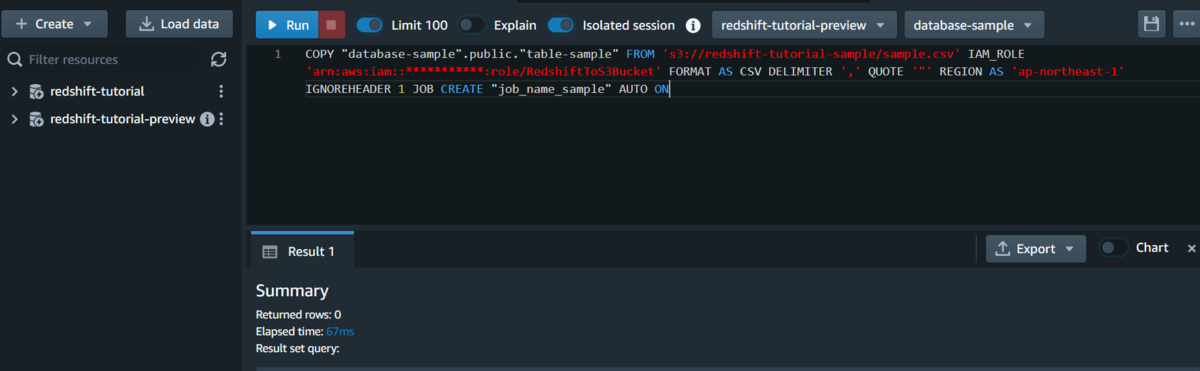
自動コピーを実行するCOPYコマンドは以下のようになります。
COPYコマンドにAUTOパラメーターが選択できるようになっています。
COPY <データベース名>.public.<テーブル名> FROM <S3バケットディレクトリ> IAM_ROLE <IAMロールARN> FORMAT AS CSV DELIMITER ',' QUOTE '"' REGION AS 'ap-northeast-1' IGNOREHEADER 1 JOB CREATE <ジョブ名> AUTO ON;
下は実行時の画面になります。
自動コピーの確認
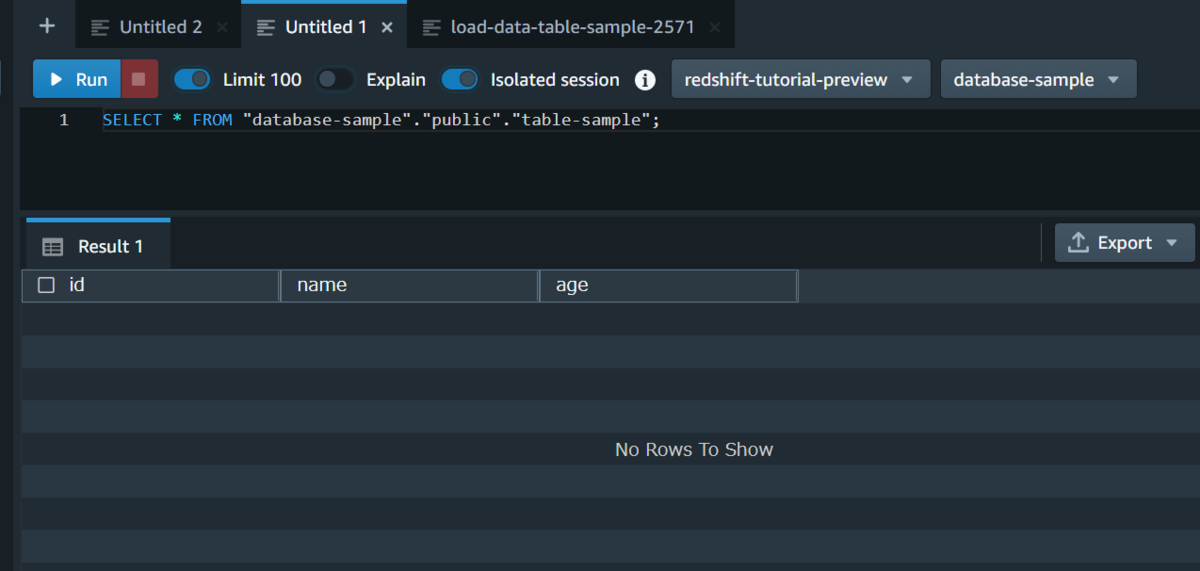
テーブルの中身は空の状態で、S3バケットにファイルをアップロードします。
アップロード後にテーブルにコピーされているか確認します。
実行前のテーブルを確認
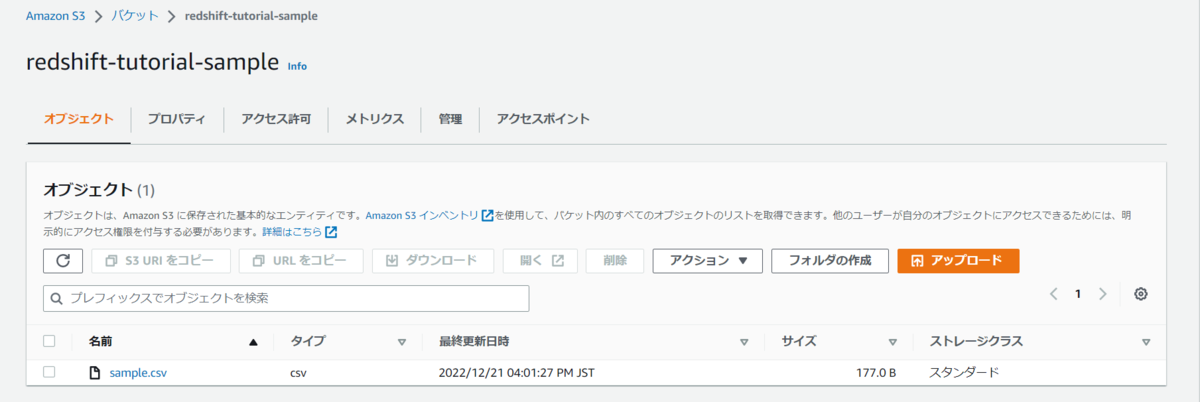
S3バケットにファイルをアップロード
実行後のテーブル
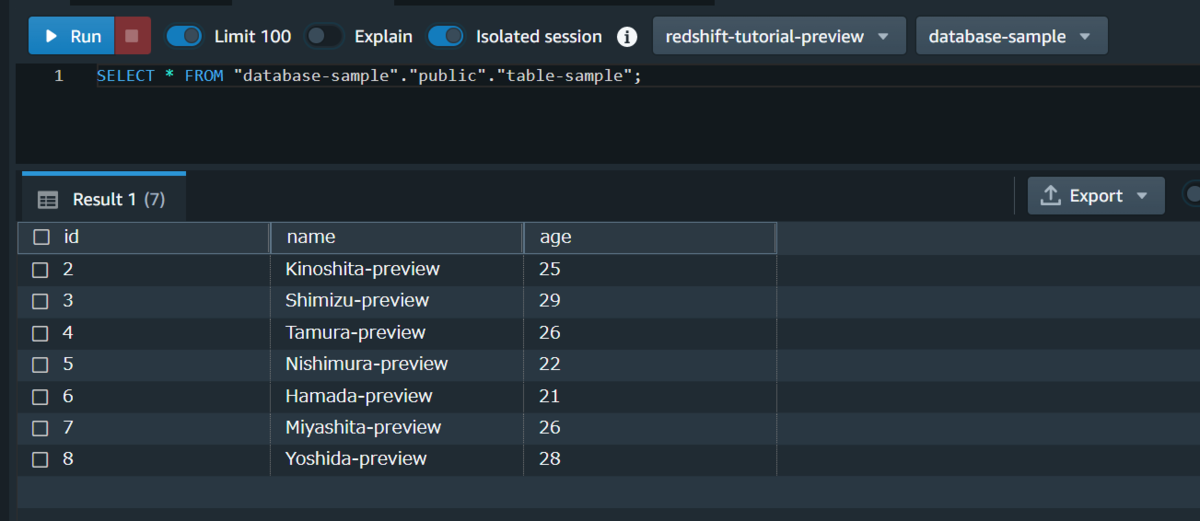
ファイルの中身がテーブルにコピーされていることを確認できました!
使ってみて
今回自動コピーを使って感じたことをまとめました。
- 自動コピーはCOPYコマンドにパラメーターを追加するだけなので簡単!
- COPYコマンドを手動で実行する手間がいらないので、かなり便利!
この機能でS3からRedShiftへのコピーの手間が大幅に削減できます。
多くの方が嬉しいアップデートだったのではないでしょうか。
気になる方はぜひ使ってみてください!
▼AWS re:Invent 2022▼
米・ラスベガスで開催されるAWS最大のカンファレンスイベント
最後まで読んでいただき、ありがとうございました。