

こんにちは 山本です
秋になり紅葉も始まってきましたね
標高の高い山では一足早く紅葉が来て去っていきました
写真は先月の仙ノ倉山です

電波も入らない山奥に行き
何も考えずに景色を楽しみながら歩き続けるのは至福の時間です
AWS DMS を使って Aurora Postgres ⇔ Aurora Postgres 間で継続的レプリケーションをする
AWS DMS を使って Aurora Postgres ⇔ Aurora Postgres 間で継続的レプリケーションをする機会がありました
かんたんに手順を残しておきますね
※概要等はあまり書きません
前提・目的
前提:
- 使用するAWSアカウントは 1つ
- レプリケーション元の Aurora Postgres クラスター があること
- レプリケーション先の Aurora Postgres クラスター があること
- レプリケーション先の Aurora Postgres クラスターはレプリケーション元の Aurora クラスターのスナップショットから作成
目的:
2つの Aurora Postgresクラスターを双方向同期した状態にする
手順
DMSサービス画面
サブネット作成
レプリケーションを行うインスタンス(レプリケーションインスタンス)を配置するサブネットを決定します

VPCはAurora Postgres クラスターと同じVPCにするとネットワーク構成が単純になります
2つ以上のアベイラビリティゾーンにそれぞれ 1つ以上のサブネットが必要です

完了と出ます
ご参考
レプリケーションインスタンスのためのネットワークのセットアップ - AWS Database Migration Service
レプリケーションインスタンス作成
レプリケーションを行うインスタンス(レプリケーションインスタンス)を作成します
画面の下に補足を記載します
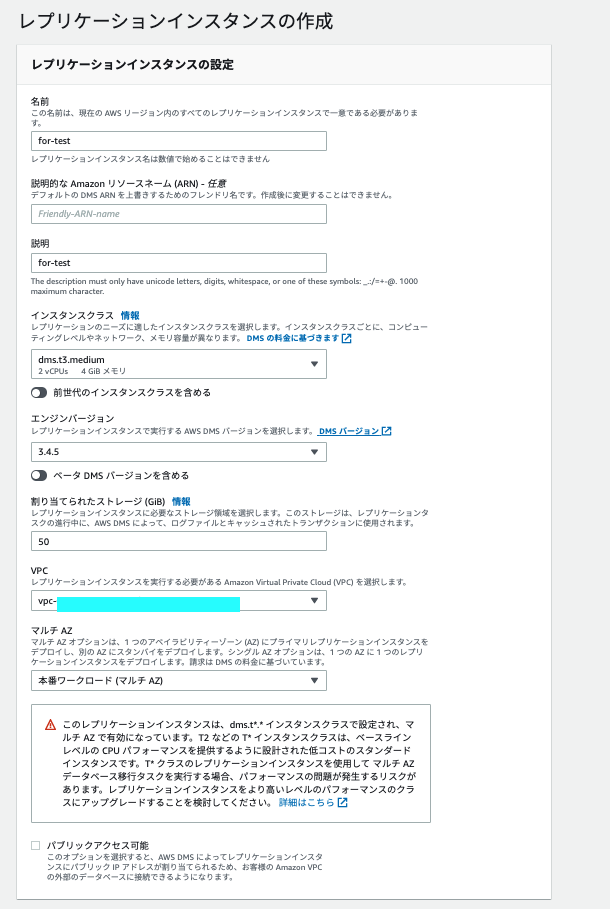
- インスタンスクラス
- レプリケーションのニーズに適したインスタンスクラスを選択します
- エンジンバージョン
- 最新を選びます
- 割り当てられたストレージ (GiB)
- レプリケーションタスクの進行中に AWS DMS が ログファイルとキャッシュされたトランザクションの保存に使用するストレージ
- Choosing the best size for a replication instance - AWS Database Migration Service
- "Consider the following factors when choosing a replication instance class and available disk storage:" を参照
- レプリケーションタスクの処理量に応じ設定
- パブリックアクセス可能
- レプリケーション対象のデータベースにインターネット経由で接続する際にチェックする
- 同じVPC内の Aurora Postgres クラスター 2つをレプリケーションさせるため チェックを外します
- VPC
- Aurora Postgres クラスターと同じVPCを選択
- 異なる場合は VPCピアリング等を行いルーティングを行うこと
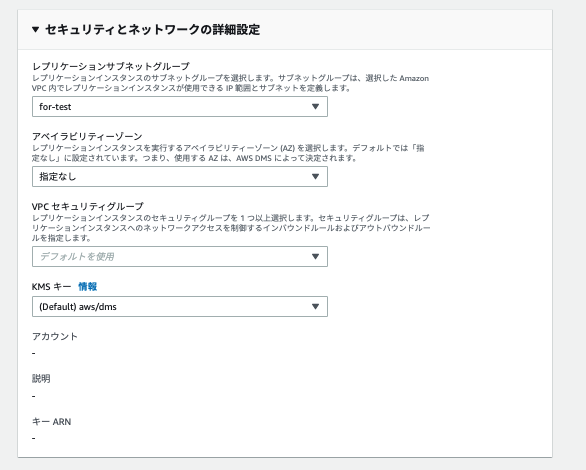
- レプリケーションサブネットグループ
- 作成したものを選択
- VPCセキュリティグループ
- このセキュリティグループからの DBポート(5432)接続 を Aurora のセキュリティグループのインバウンドルールに許可しておくこと
- ここで選択するセキュリティグループのアウトバウンドルールは アウトバウンド通信をすべて許可していること
- KMSキー
- レプリケーションインスタンスに割り当てるストレージを暗号化する際に使用
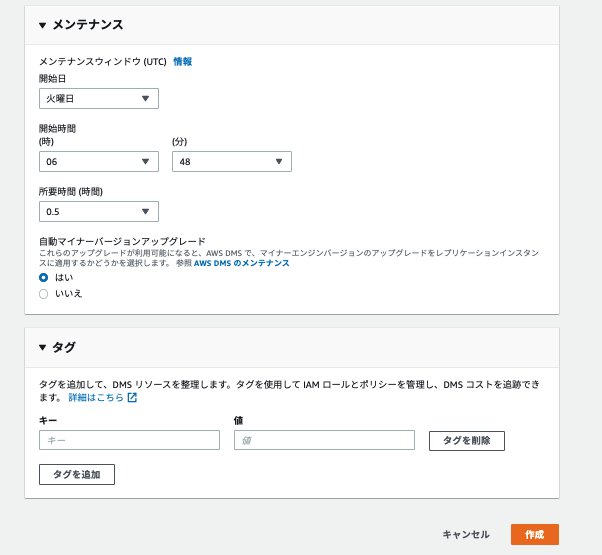
- メンテナンスウィンドウ (UTC)
- AWSが行う定期的なメンテナンスを実施する場合の実施時間
- メンテナンスがこの時間に必ずあるというわけではなく「実施する場合」の時間
10分くらい待つと利用可能状態になります
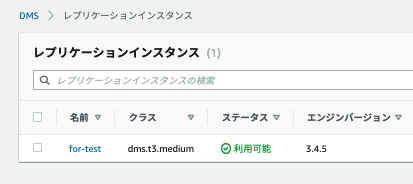
エンドポイント作成
以下の 2つを作成します
- ソースエンドポイント
- レプリケーションインスタンスがレプリケーション元のAurora Postgresクラスターと接続する方法
- ターゲットエンドポイント
- レプリケーションインスタンスがレプリケーション先のAurora Postgresクラスターと接続する方法
エンドポイントの作成を押します

ソースエンドポイントを作成していきます

- RDS DB インスタンスの選択
- チェックします
- RDS インスタンス
- 選ぶと「エンドポイント識別子」「ソースエンジン」を自動入力します
- エンドポイントデータベースへのアクセス
- Aurora への接続方式によって変わります
- この検証においては 手動入力します
- ユーザーはマスターユーザーの使用を推奨します
- Secure Socket Layer (SSL) モード は 使用している場合に選択します
- データベース名はレプリケーションするデータベースを選択します
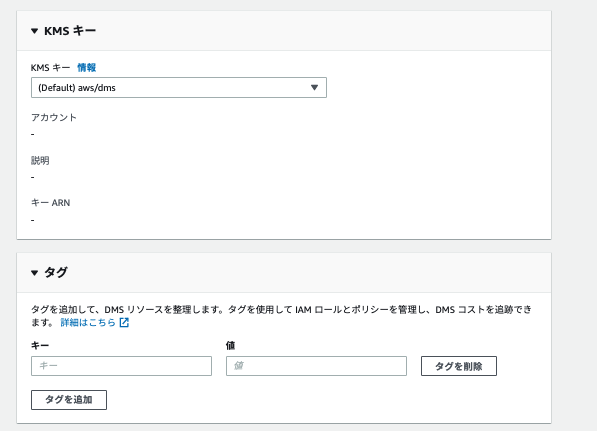
- KMSキー
- データベースへのアクセスに関する認証情報を暗号化する際に使用します
- この検証においてはデフォルトの暗号化キーを利用します
「アクティブ」になりました

作成したソースエンドポイントを参照し「接続」タブから接続テストをします
画面右上の「接続のテスト」を押します
testing になり
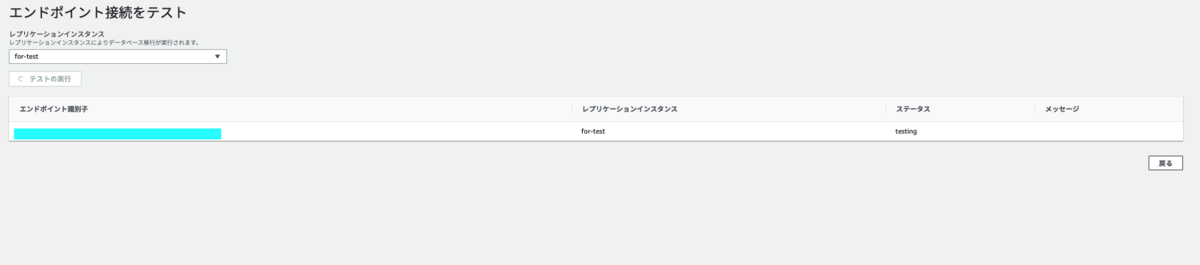
しばらくするとsuccessful になります

ターゲットエンドポイントも同様に作成し接続テストをします (手順略)
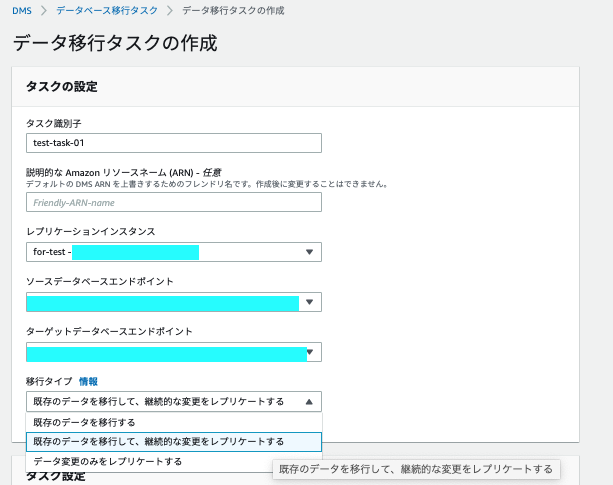
データベース移行タスクの作成
さて 準備が整ってきました
いよいよ移行タスクを作成していきます

識別子を付与して
作成したレプリケーションインスタンス
ソースエンドポイント
ターゲットエンドポイントを選択します
継続的レプリケーションをするため
「既存のデータを移行して、継続的な変更をレプリケートする」を選択します
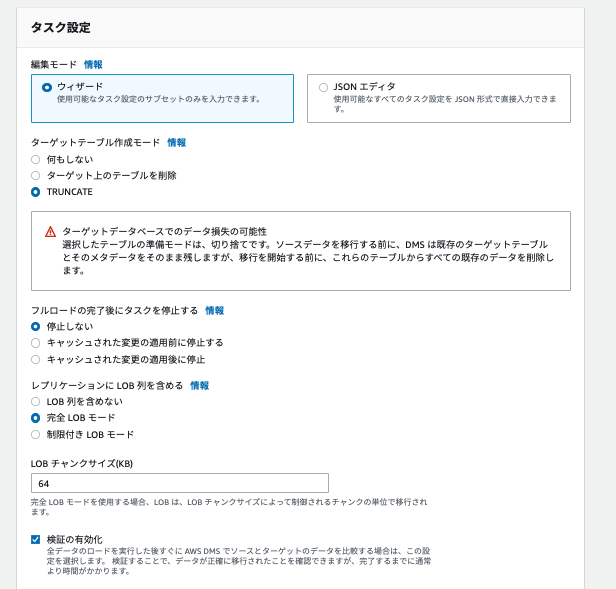
- ターゲットテーブル作成モード
- スナップショットから作成したレプリケーション先Aurora Postgresクラスターにレプリケーションするため 「TRUNCATE」 を選択します
- 何もしない - ターゲットに既にテーブルがあっても、テーブルへの影響はありません。 それ以外の場合は、AWS DMS によって新しいテーブルが作成されます。
- ターゲット上のテーブルを削除 - AWS DMS はテーブルを削除し、新しいテーブルを作成します。
- TRUNCATE - AWS DMS はテーブルとそのメタデータはそのまま残しますが、データはそこから削除されます。
- スナップショットから作成したレプリケーション先Aurora Postgresクラスターにレプリケーションするため 「TRUNCATE」 を選択します
- フルロードの完了後にタスクを停止する
- 継続的にレプリケーションするため「停止しない」を選択します
- レプリケーションに LOB 列を含める
- LOBがあるかもしれないので 完全LOBモードにしておきます
- 検証の有効化
- レプリケーションタスク開始後にレプリケーションしたテーブル同士を比較するもの
- 便利なのでチェックします
- ただしプライマリーキーの無いテーブルは比較してくれません
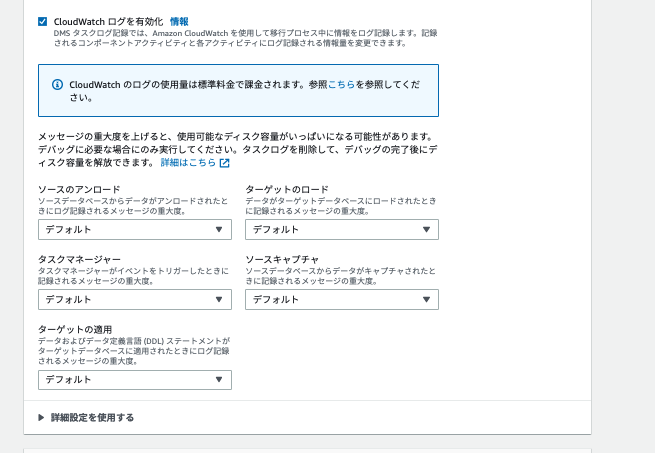
- CloudWatch ログを有効化
- レプリケーション関連のログをCloudWatchに出力します
- 一旦デフォルトにて有効にしておきます
- 詳細デバッグログも出力可能です
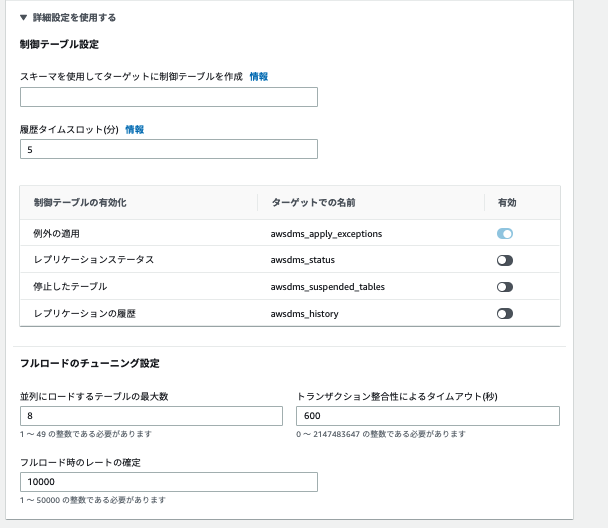
- 詳細設定を使用する
- ターゲットに制御テーブルを作成して各テーブルのレプリケーション状態を確認できます
- 本検証においては一旦そのままとします(また詳細が分かったら記載します)
- フルロードのチューニング設定
- レプリケーション開始時に最初に走るフルロードの並列実行数などのパフォーマンス設定です
- 一旦そのままとします(また詳細が分かったら記載します)
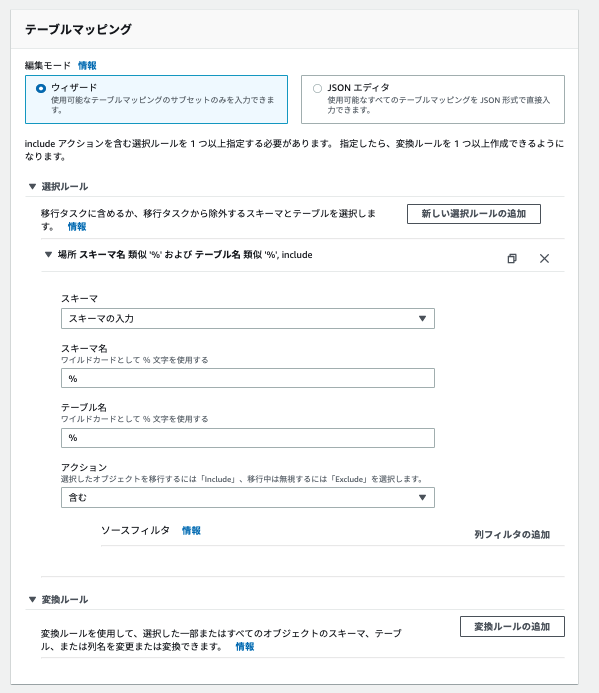
- 選択ルール
- スキーマ名
- すべてのスキーマをレプリケーションするため % を入力します
- テーブル名
- すべてのテーブルをレプリケーションするため % を入力します
- アクション
- 全てのスキーマの全てのテーブルをレプリケーションするため 「含む」を選択します
- スキーマ名
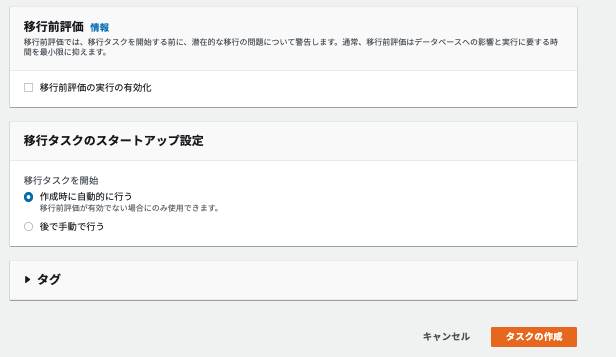
移行前評価
- 一旦そのままとします(また詳細が分かったら記載します)
移行タスクを開始
- 作成時に自動的に行う を選択します
- 後から手動で開始も可能です
- 作成時に自動的に行う を選択します
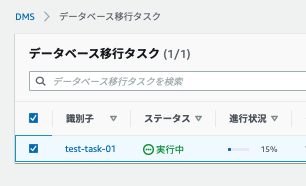
作成するとタスクが実行中になります
実行中にならない場合は「アクション」ボタンから「開始/再開」としてください
各テーブルのレプリケーション状態は「テーブル統計 」の画面から見れます
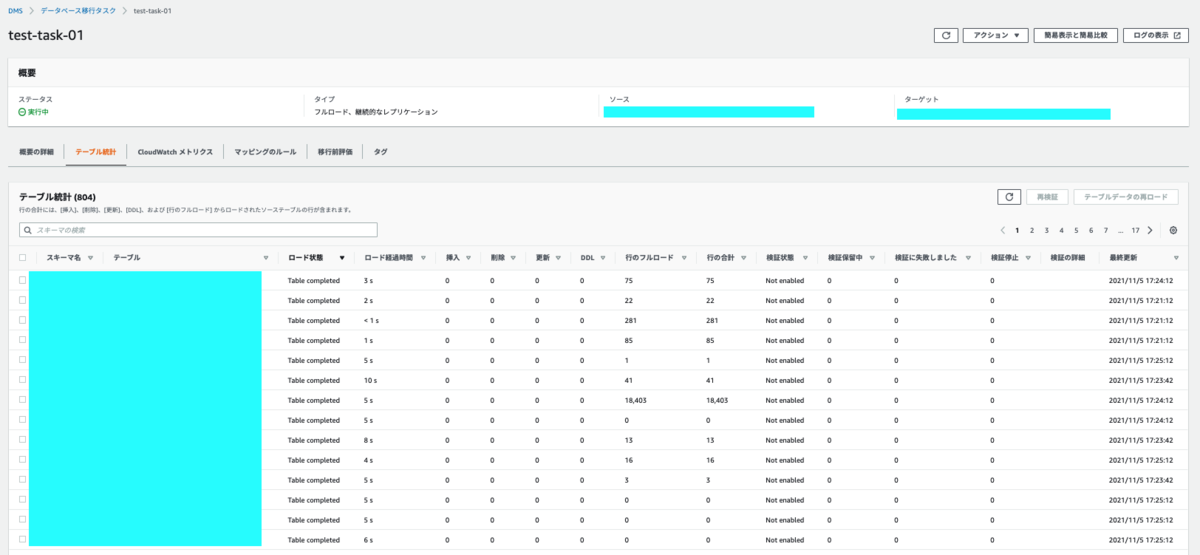
- 詳細は以下のリンクに
- 検証状態 の列においてプライマリキーの無いテーブルは 検証できないため No Primarykey と出ます
さて時間切れとなりました・・・・
色々と検証していますので徐々に本記事を更新していきます
ちなみにDMSは使用可能なDDL等の制約も色々とあるのでドキュメントは要確認です...
最終形をお楽しみに!