


こんにちは。新規開発チームの小田切です。
みなさん、8月も終わろうかというのに、連日の猛暑で体調など崩されていませんか?
そんな暑さのなか、Amazonからまた新しいサービスが発表されました。
その名も「Amazon Glacier(グレイシャー:氷河)」です。
特徴は何と言っても、こちらでも紹介されています通り、きわめて低価格なストレージサービスという事です。
東京リージョンで使用した場合、一ヶ月あたり1G$0.012という驚きの価格です。(S3と比べるとほぼ10分の1の価格です!!)
そのかわり、S3はいつでも即ファイルのダウンロードが行えるのに対して、Glacierではファイルの取り出しには、3.5〜4.5時間程度待たされます。
ちなみに、以下の図がGlacierの仕組みが分かりやすいかと思います。
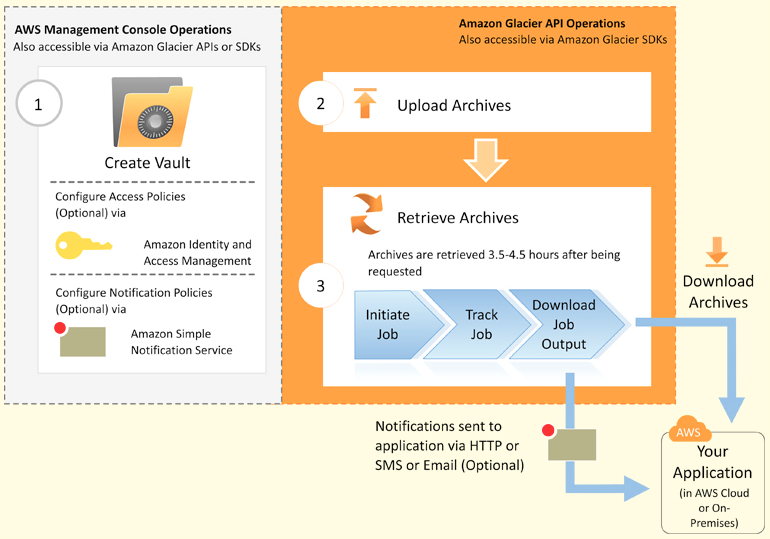
① Vaultを作成する
② ファイルをアップロードする
③ ダウンロードの指示をすると、3.5時間〜4.5時間くらいでダウンロードが可能になる
(SNSを使用してダウンロードが可能になったか通知し、それを受けてファイルのダウンロードを行う。もしくは、常にジョブの状況をポーリングし確認して、ダウンロード可能になったらダウンロードを行う。)
今回、そんなサービスを早速試して見ました。
ManagementConsoleでは「Vault(金庫?)」と呼ばれるS3でいうところのバケットの作成を行う事は出来るのですが、ファイルのアップロード、ダウンロードはAPIを利用します。
現在、AWSからは、Javaと.netのSDKでGlacierに対応しているとの事で、今回はJavaにて検証を行ってみました。
事前準備
まずは、Vaultの作成を行います。
AWS Management Consoleより「Glacier」を選択しますと、以下のような画面が表示されます。
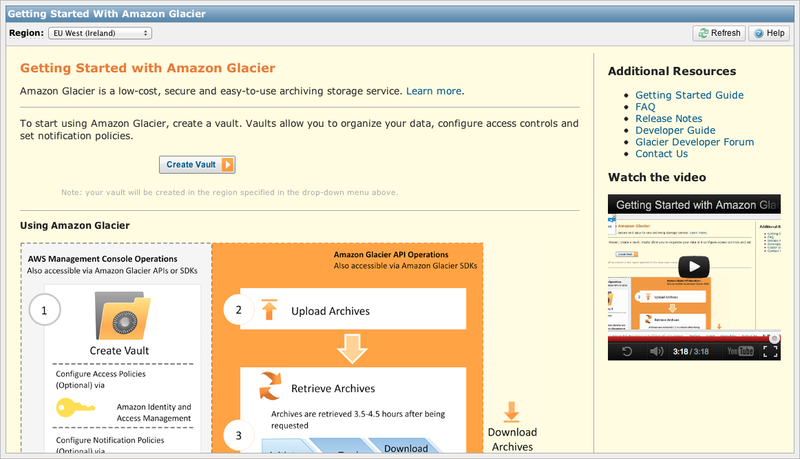
「Create Vault」をクリックしますと、Vault名を入力するウィンドウが表示されますので、好きな名前を付けます。
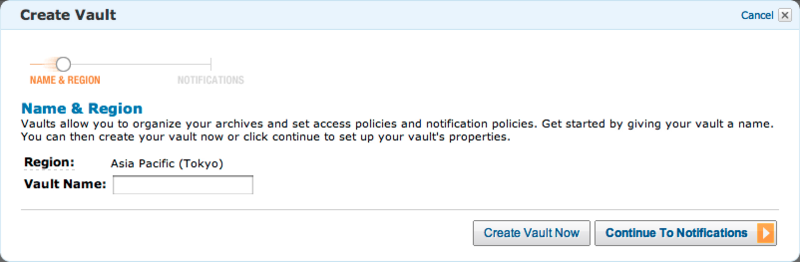
通知の設定に関しては、後でいつでも変更可能なので、今回は名前だけ入力し「Create Vault Now」をクリックし、Vaultを作成します。
Vault作成後の画面はこちら。
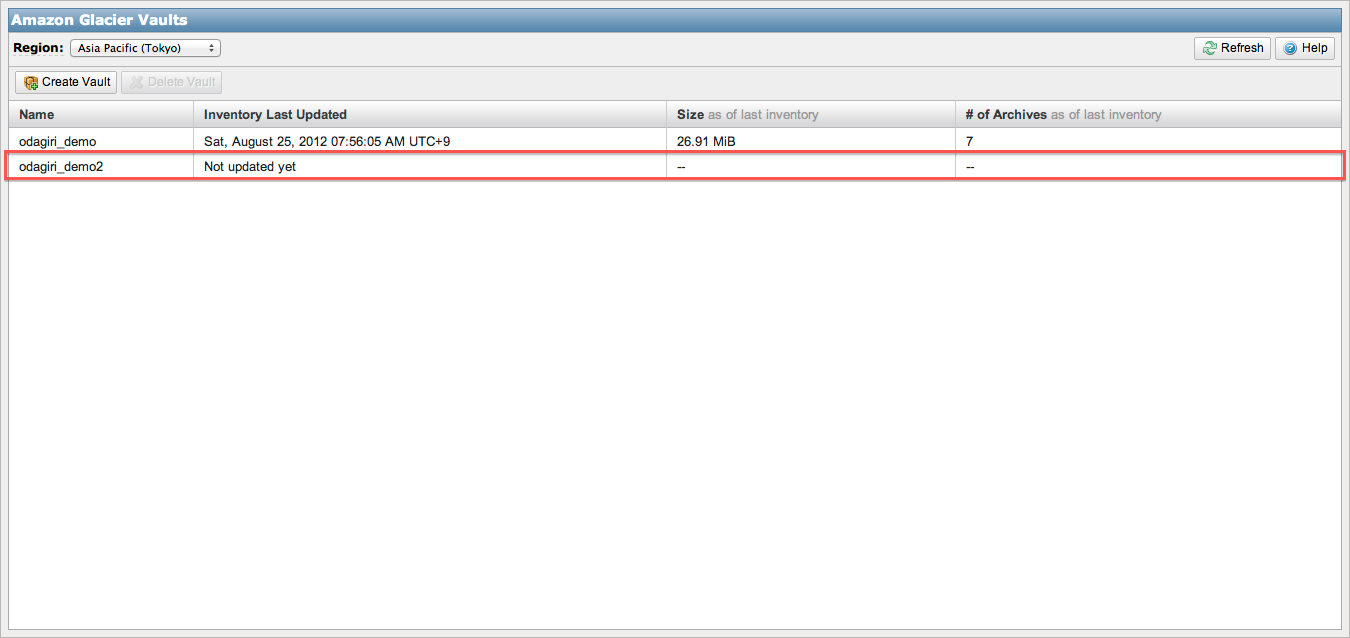
まだ、ファイルを上げていないので、"Not updated yet"のような表示になっています。
では、早速ファイルをアップロードしたい所ですが、先にSNSでの通知設定を行っておきます。
対象のVaultを選択しますと、画面下部にVaultのプロパティが表示されます。

「Notifications」タブをクリックして、Notificationsオプションを「enabled」にします。
Notificationsオプションをenabledにしますと、「Amazon SNS Topic ARN」以下が入力可能になります。
まずは、SNSの設定を行うので、「create a new SNS topic」をクリックします。
上記画面が表示されますので、適当な名前、説明を入力し、「Create Topic」をクリックし、SNSを作成します。
SNSを作成しますと、Amazon SNS Topic ARNに自動で値が設定されます。
後は、何を通知するかの設定を行います。
「Archive Retrieval Job Complete」と「Vault Inventory Retrival Job Complete」をチェックし、右下の「Save」をクリックして完了です。
また、別途ManagementConsoleのSNSの画面にて、上記で作成されたSNSの通知先をEmailにし、通知を受け取るメールアドレスを設定しておきます。
ファイルのアップロード
AWSCredentials credentials = new PropertiesCredentials(
ArchiveUploadHighLevel.class.getResourceAsStream("AwsCredentials.properties"));
AmazonGlacierClient client = new AmazonGlacierClient(credentials);
client.setEndpoint("http://glacier.ap-northeast-1.amazonaws.com/");
String archiveToUpdate = "アップロードするファイルを指定";
ArchiveTransferManager atm = new ArchiveTransferManager(client, credentials);
String archiveId = atm.upload("Vault名", "アップロードするファイルの説明", new File(archiveToUpdate)).getArchiveId();
System.out.println("Archive ID: " + archiveId);
今回、約1GBのファイルをアップロードしましたが、アップロードにかかった時間は、約362秒でした。
なお、ファイルをアップロードした際に、アーカイブIDという物がGlacierで付与されます。
ファイルのダウンロードを行う際に必要になりますので、アップロードしたファイルとアーカイブIDは自分でマッピングして置く必要があります。(なお、アーカイブIDはアップロードしたファイルの削除にも必要なのでしっかり保存しておく必要があります。)
ファイルのダウンロード
AWSCredentials credentials = new PropertiesCredentials(
ArchiveDownloadHighLevel.class.getResourceAsStream("AwsCredentials.properties"));
AmazonGlacierClient client = new AmazonGlacierClient(credentials);
client.setEndpoint("http://glacier.ap-northeast-1.amazonaws.com/");
JobParameters jobParameters = new JobParameters()
.withArchiveId("ファイルをアップロードした際に取得したアーカイブID")
.withDescription("archive retrieval")
.withType("archive-retrieval");
InitiateJobResult initiateJobResult = client
.initiateJob(new InitiateJobRequest().withJobParameters(
jobParameters).withVaultName("Vault名"));
String jobId = initiateJobResult.getJobId();
System.out.println("Job ID: " + jobId);
{
"Action": "ArchiveRetrieval",
"ArchiveId": "xxxxxxxxxxxxxxxxxxxxxxxxxx",
"ArchiveSizeInBytes": 93928,
"Completed": true,
"CompletionDate": "2012-08-27T07:17:08.098Z",
"CreationDate": "2012-08-27T02:59:43.400Z",
"InventorySizeInBytes": null,
"JobDescription": null,
"JobId": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"SHA256TreeHash": "3c6e9cd90403aea838feb8c7d44901619aae2eb9f32c25975c691cef66f4ccf8",
"SNSTopic": "arn:aws:sns:ap-northeast-1:xxxxxxxxxxxx:odagiri-glacier",
"StatusCode": "Succeeded",
"StatusMessage": "Succeeded",
"VaultARN": "arn:aws:glacier:ap-northeast-1:xxxxxxxxxxxx:vaults/odagiri_demo"
}
AWSCredentials credentials = new PropertiesCredentials(
ArchiveDownloadHighLevel.class
.getResourceAsStream("AwsCredentials.properties"));
AmazonGlacierClient client = new AmazonGlacierClient(credentials);
client.setEndpoint("http://glacier.ap-northeast-1.amazonaws.com/");
GetJobOutputRequest jobOutputRequest = new GetJobOutputRequest()
.withJobId("SNSで通知されたJOB ID").withVaultName("Vault名");
GetJobOutputResult jobOutputResult = client
.getJobOutput(jobOutputRequest);
InputStream input = new BufferedInputStream(jobOutputResult.getBody());
OutputStream output = null;
try {
output = new BufferedOutputStream(
new FileOutputStream("保存先のファイルパス名"));
byte[] buffer = new byte[1024 * 1024];
int bytesRead = 0;
do {
bytesRead = input.read(buffer);
if (bytesRead <= 0)
break;
output.write(buffer, 0, bytesRead);
} while (bytesRead > 0);
} catch (IOException e) {
throw new AmazonClientException("Unable to save archive", e);
} finally {
try {
input.close();
} catch (Exception e) {
}
try {
output.close();
} catch (Exception e) {
}
}
System.out.println("Retrieved archive to " + fileName);
これで、ファイルのダウンロードが完了します。
ダウンロードしたファイルは約1GBのファイルでしたが、ダウンロードにかかった時間は、約769秒でした。
今回、使用しなかったもう一つのダウンロード方法は、ダウンロードするアーカイブを指定し、ダウンロードの指示を行った後、定期的にポーリングを行い、ジョブの状態をチェックし、ダウンロードが可能になったらファイルをダウンロードするという方法です。
こちらの「Example2」にサンプルがありますので、興味のある方は是非そちらも試してみてください。
まとめ
| Glacier | S3 | |
| 価格(東京リージョン、月) | $0.012/GB | $0.130/GB(スタンダードストレージ。最初の1TBまで) |
| データの堅牢性 | 99.999999999% | 99.999999999% |
| データの取り出し | 3〜4時間待ち | 即時取り出し可能 |
| 操作性 | APIを使用する必要がある | ManagementConsoleだけで完結できる |