

サーバーワークスの村上です。
煽った感じのタイトルですが、検索も大事だよね、と捉えていただけると幸いです。
このブログでは、同じ意味だけど検索対象ドキュメントとは違う言葉を使って検索した際に、きちんと検索できるのか検証してみました。
最初に記事のまとめ
検証したこと
弊社ホームページの検索
Amazon KendraとAmazon OpenSearch Serverlessに弊社の採用関連ページを取り込み、検索精度を確認しました。
具体的に行ったことは以下のとおりです。
- サーバーワークス採用サイト配下の408個のURLをクロールします。
- 上記をAmazon KendraとAmazon OpenSearch Serverlessで検索可能な状態にします。
- それぞれに対し、「社員の階級は分かれていますか?」という検索クエリを実行しました。
- 検索対象のページには「役職とグレードの分離」という記事があり、このページがヒットするか確認しました。
- 検索クエリと検索した結果をAmazon Bedrockに入力して、回答内容を確認しました。
検証の目的
Amazon KendraとAmazon OpenSearch Serverlessで検索結果に差が出るのか確認することを目的にしました。
役職とグレードではなく、階級という記事に登場しないキーワードで検索した際に、ちゃんと「役職とグレードの分離」ページを検索できるか- 検索クエリに「社員」というキーワードが含まれていた際に、無関係なページ(例えば社員紹介)を検索してしまわないか
を確認します。
※階級って言葉は普通使わないかもしれませんが、意味的には同じだが異なるキーワードで検証したいという意図です。
結論
「社員の階級は分かれていますか?」という質問に対して得られた結果を記載します。
Amazon Kendraの場合
- Amazon Kendraではお客様事例の記事などが最初にヒットし、「役職とグレードの分離」ページは5番目にヒットしました。
- これにより、Amazon BedrockとのRAG構成で、基盤モデルからは文書から社員の階級については明確に分かりません。という回答が返ってきました。
- ※回答全文は後述します。
Amazon OpenSearch Serverlessの場合
- Amazon OpenSearch Serverlessでは「役職とグレードの分離」ページが最初にヒットしました。
- これにより、Amazon BedrockとのRAG構成で、基盤モデルからはこの会社では社員の階級(グレード)が分かれているようです。という回答が返ってきました。
- ※回答全文は後述します。
補足(というかDisclaimer)
今回の結果はあくまで検証した内容に限っての結果です。Amazon Kendraが言葉の意味を全く解釈できないという意図はありません。
下記のページにも、Amazon Kendraはキーワード検索ではなくセマンティック検索を使っており、ユーザーの検索意図を読み取った検索が可能と記載されています。例えば「PC」と「パソコン」が意味的に近いことを理解する、との記載もあります。
前提
RAG(検索拡張生成)とは
LLMの外部に情報の保管場所を作っておき、ユーザーの質問に関連する情報を検索・取得したうえで、LLMに入力し回答を求める手法です。
過去のブログに絵も載せていますのでご参照ください。
Amazon Kendraの検索
補足にも記載したとおり、セマンティック検索が可能な検索サービスです。
キーワード検索を使用する従来の検索サービスとは異なり、Amazon Kendra は質問のコンテキストを理解しようとし、クエリに最も関連性の高い単語、スニペット、またはドキュメントを返します。
What is Amazon Kendra? - Amazon Kendra
ただし、埋め込みモデルを使用した密ベクトルへの変換をしているかどうかはドキュメントから確認できませんでした。
Amazon OpenSearch Serverlessの検索
Amazon OpenSearch Serverlessはベクトル検索の機能をもったサービスです。ベクトル検索の機能自体はre:Invent2023で登場しました。
検証手順
Amazon Kendraに弊社ホームページを取り込む
Amazon KendraのIndexを作成後、Web Crawler V2.0を使ってData Sourceを追加します。
採用関連のページに限定するためhttps://www.serverworks.co.jp/recruit/をクローリングします。
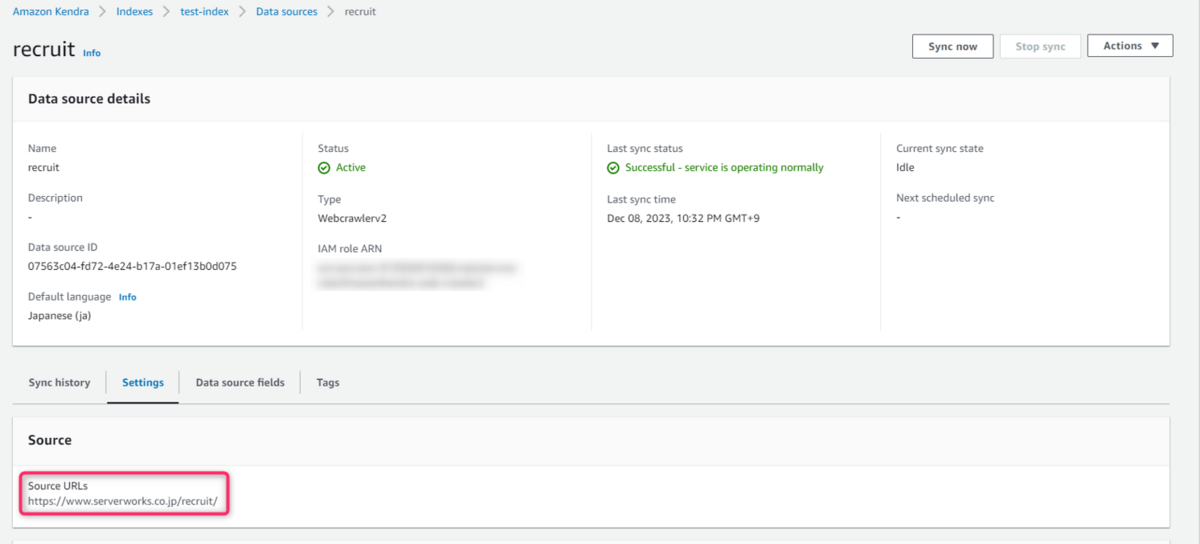
結果、408個のアイテムを取り込みました。

以上でAmazon Kendraのセットアップは完了です。とても簡単に検索ソリューションを構築できるのが魅力ですね。
Amazon OpenSearch Serverlessに弊社ホームページを取り込む
Amazon Kendraに取り込んだ内容と同じものをベクトルに変換して、Amazon OpenSearch Serverlessに挿入していきます。
CloudWatchからURLを取得
Amazon Kendraに取り込んだURLと同じURLを取得するための作業です。
まず、Amazon KendraのSync run history からアイテムを取得したログを確認します。下記画像のリンクをクリックするとCloudWatch Log Insightsの画面に遷移します。

CloudWatch Log Insightsでは、下記のようにhas been completed successfullyという文言を含むレコードだけフィルタすることで、Amazon Kendraに追加したアイテムと同数のレコードを検索することができました。

これはクローリングしたURLごとに、Crawling for the URL https://www.serverworks.co.jp/xxxx.html has been completed successfully.というログが出力されるので、そのレコードだけを検索するのが狙いです。
URLリストの作成
CloudWatch Log Insightsから出力したCSVからURLだけを抽出します。
import csv import re file_path = './kendra_crawler_list.csv' crawler_list = [] # CSVファイルを開き、内容を読み込む with open(file_path, newline='') as csvfile: reader = csv.reader(csvfile) for row in reader: crawler_list.append(row[0]) url_pattern = r'https://[^\s"]+' urls = [] for url in crawler_list: url = re.findall(url_pattern, url) urls.append(url[0])
URLリストの要素数がAmazon Kendraに取り込んだ408アイテムと同数であることを確認しました。

URLの内容をチャンク化
1URL(1ページ)をベクトル化するには長すぎるため、適切な長さに区切ります(チャンク化)。ここではLangchainを使用しています。
from langchain.document_loaders import UnstructuredURLLoader from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter(chunk_size = 1000, chunk_overlap = 100) url_loader = UnstructuredURLLoader(urls=urls) url_texts = url_loader.load_and_split(text_splitter=text_splitter)
埋め込み(ベクトル化)
次に、チャンクしたドキュメントをベクトルに変換します。
必要なクラスをインスタンス化します。
from langchain.embeddings import BedrockEmbeddings bedrock_embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-g1-text-02", client=bedrock)
次にAmazon OpenSearch Serverlessへの接続のための情報を定義します。
from opensearchpy import OpenSearch, RequestsHttpConnection, AWSV4SignerAuth from requests_aws4auth import AWS4Auth host = "xxxx.aoss.amazonaws.com" index = "yyyy" service = 'aoss' credentials = my_session.get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token)
最後にドキュメントをベクトルに変換し、Amazon OpenSearch Serverlessに挿入します。
from langchain.vectorstores import OpenSearchVectorSearch os_domain_ep = 'https://'+host OpenSearchVectorSearch.from_documents( index_name = index, documents=url_texts, embedding=bedrock_embeddings, opensearch_url=os_domain_ep, http_auth=awsauth, connection_class=RequestsHttpConnection, bulk_size=2000, timeout=3600, )
以上で準備が完了しました!
検索結果の比較
ここからはAmazon KendraとAmazon OpenSearch ServerlessそれぞれでRAGを構成し、レスポンスを比較します。
RAGで使用した基盤モデルはClaude 2です。
from langchain.llms.bedrock import Bedrock bedrock = my_session.client('bedrock-runtime', region_name=region) inference_modifier_claude = { "max_tokens_to_sample": 4096, "temperature": 0.1, "top_k": 250, "top_p": 1, "stop_sequences": ["\n\nHuman"], } llm = Bedrock( model_id="anthropic.claude-v2", client=bedrock, model_kwargs=inference_modifier_claude, )
Amazon Kendraの場合
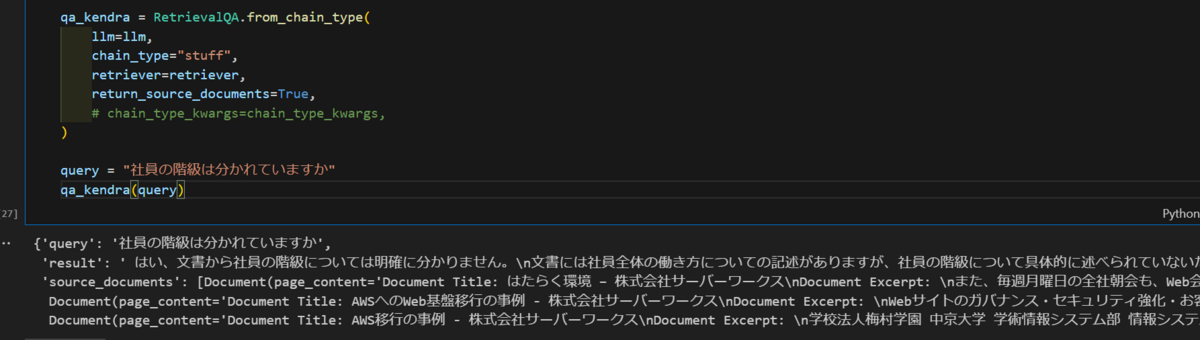
Amazon Kendraで、「社員の階級は分かれていますか」という質問に関連する文書を検索し、質問とともに基盤モデルに入力します。
from langchain.retrievers import AmazonKendraRetriever from langchain.chains import RetrievalQA KENDRA_INDEX_ID = "hogehoge" attribute_filter = { "AndAllFilters": [ { "EqualsTo": { "Key": "_language_code", "Value": {"StringValue": "ja"} } } ] } retriever = AmazonKendraRetriever( index_id=KENDRA_INDEX_ID, attribute_filter=attribute_filter, region_name=region ) qa_kendra = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=retriever, return_source_documents=True, ) query = "社員の階級は分かれていますか" qa_kendra(query)
レスポンス
レスポンスは下記のとおりです。
はい、文書から社員の階級については明確に分かりません。文書には社員全体の働き方についての記述がありますが、社員の階級について具体的に述べられていないため、階級が分かれているかどうかは不明です。従って、この文書から社員の階級が分かれているか判断することはできません。ご質問の答えは文書からは分からないと言えます。
検索結果
return_source_documents=Trueに設定しているので、Amazon Kendraが検索してきた結果も見ることができます。
また、LangchainのAmazonKendraRetrieverはデフォルトで上位3件の検索結果を返します。
検索結果は以下のとおりです。
- はたらく環境 – 株式会社サーバーワークス
- ページ内に「社員」というキーワードが9個
3つのゾーンに分かれたオフィスはフリーアドレス制となっており、という記載があり、検索クエリの「分かれていますか」との関連性が大きいと判断されたと推測役職、グレード、階級というワードはページ内に記載なし
- AWSへのWeb基盤移行の事例 - 株式会社サーバーワークス
- ページ内に「社員」というキーワードはなし
エンタープライズグレードのコンテンツ管理システム、Webサイトが分かれていたという記載があり、検索クエリとの関連性が大きいと判断されたと推測
- AWS移行の事例 - 株式会社サーバーワークス
- ページ内に「社員」というキーワードはなし
利用する期間によって判断が分かれるという記載があり、検索クエリとの関連性が大きいと判断されたと推測
所感ですが、検索クエリに含まれるキーワードに強く反応しつつ、階級≒グレードと解釈もしているような感じがしました。
Amazon OpenSearch Serverlessの場合
Amazon Kendraと同じくLangchainのRetrievalQAを使用しました。
opensearch_vector_search_client = OpenSearchVectorSearch(
index_name=index,
embedding_function=bedrock_embeddings,
opensearch_url=os_domain_ep,
http_auth=awsauth,
connection_class=RequestsHttpConnection,
)
qa_aoss = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=opensearch_vector_search_client.as_retriever(),
return_source_documents=True,
)
qa_aoss(query)
レスポンス
レスポンスは下記のとおりです。
はい、この会社では社員の階級(グレード)が分かれているようです。主なポイントは以下の通りです:
- 人事評価において、成果評価と行動評価の2つの観点で評価が行われている
- 行動評価はグレードごとに求められる行動が設定されており、これがグレード昇降格の基準になっている
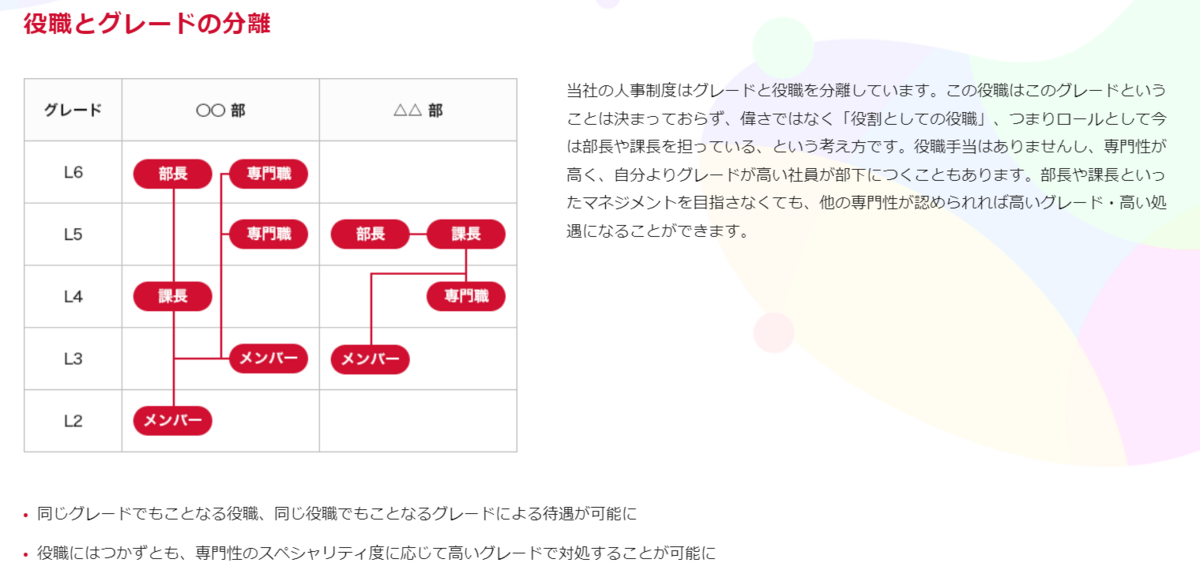
- グレードと役職が分離されている。同じグレードでも異なる役職があり、同じ役職でも異なるグレードがある
- 専門性が高ければ、役職につかなくても高いグレードが付与されることがある
以上から、この会社には社員の階級(グレード)があり、それに応じた評価と処遇が行われていることが分かります。

検索結果
検索結果は「役職とグレードの分離」のみが検索されました。
まとめ
生成AIのユースケースとして有名になったRAGですので、生成AIに目が行きがちですが、前段の検索システムの違いで結果も大いに変わります。
RAGを運用する中で意図した結果が返ってこなかった際、検索によるものなのか基盤モデルによるものなのか、まずは意識したいポイントかと思います。
お読みいただきありがとうございました。