

営業部 佐竹です。
本ブログは、Redshift クラスターの運用知見を記載します。特に Manual WLM を利用している場合での同時実行数チューニングについて記載します。
はじめに
Redshift クラスター が Queue 詰まりを起こした場合に、どのように対処すればよいでしょうか。
また、どのように調査すれば、Redshift クラスターが Queue 詰まりを起こしているかすぐに判断できるでしょうか。
このあたりの知見は「知っている人は当たり前のように知っている」のですが、わからない人にとっては完全に未知の世界です。
今回は、ある程度 Redshift について知っている方を前提に、Redshift クラスターの運用保守において、パフォーマンスが悪化してしまった場合に Queue 詰まりを起こしていないかどうか調査し、それをチューニングして解決するまでの流れをご紹介します。
シナリオ
今回は、以下の環境を想定します。
- 本番環境で Redshift クラスターを運用
- クラスターは RA3 で動作中
- Redshift の利用方法はバッチ処理によるデータ取り込みと BI ツールを活用した描画
- Redshift への負荷はある程度想定が可能で、バッチ処理は夜間に負荷が高く、BI ツールからの接続は日中の営業時間帯である
- ワークロード管理(WLM)は Auto ではなく Manual(手動)で設計
このような環境で、BI ツールの速度劣化や動作不安定が発生した状況を解決します。
調査方法
Redshift のコンソールから調査する
事象が発生しているクラスターを選択し「クエリのモニタリング」タブを開きます。加えて、「ワークロードの同時実行」を選択します。
表示できたら、調査を行いたい時間帯を表示させます。「タイムスケール」を移動させて、絞り込みます。
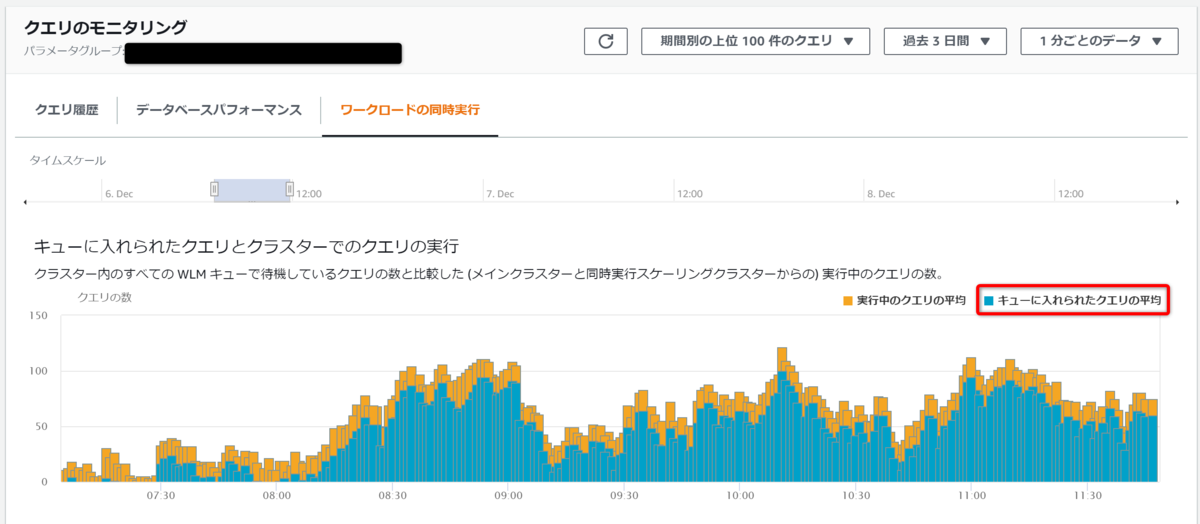
「キューに入れられたクエリとクラスターでのクエリの実行」に表示される、オレンジ色と青色のバーが見て取れます。
オレンジ色が実行中のクエリで、青色がキューに入っているもののそのまま動いていない、云わば「待たされている」クエリです。つまり、青色が多いということはキューが詰まっているということになります。
ワークロード管理
Redshift の「設定」に「ワークロード管理」という設定画面があります。ここは、パラメータグループに紐づいたワークロード管理の設定を行う箇所です。
今回 Queue 詰まりを起こしている Redshift クラスターのパラメータグループを特定し、予め設定を確認しておきます。理由は、この後の調査で必要なためです。
対象のクラスターは、ワークロード管理が「手動 WLM」であり、ワークロードキューは Queue 1~4に分かれており「BI ツールを活用した描画」では Queue 2 が利用されていることが判明しています。

また、チューニング前の Queue 2 における「メインでの同時実行(Concurrency on main)」は 13、「同時実行スケーリングモード(Concurrency Scaling)」は off となっていました。
ワークロード管理の全体設定をまとめると以下の表の通りとなっていました。
| Queue No | 同時実行数(スケーリング) |
|---|---|
| Queue1 | 25(off) |
| Queue2 | 13(off) |
| Queue3 | 2(off) |
| Queue4 | 1(off) |
| Default queue | 1(off)) |
| 合計 | 42 |
CloudWatch のコンソールから調査する
先に Redshift のコンソールから確認した負荷状態を CloudWatch でも確認します。
「すべてのメトリクス」を選択後、Redshift のサービスを検索し、「ClusterIdentifier,QueueName」を表示します。これを利用することで、WLM に設定されている Queue ごとのクエリの実行状況がわかります。
具体的に利用するメトリクスは以下の通りですので、この名称で検索していただいても問題ありません。
- WLMRunningQueries:対象の Queue で何個のクエリが同時に実行されているか
- WLMQueueWaitTime:Queue に入っているものの、そのQueue の中で待たされているクエリの待ち時間
Queue 2 調査
まずは本番クラスターの「Queue 2 WLMRunningQueries」を描画します。

左軸に、WLMRunningQueries として実行中のクエリがカウントされていますが、これが「メインでの同時実行」=「13」という設定で頭打ちしていることがわかります。

Queue 2 WLMQueueWaitTime を右軸に追加して確認してみると、待ち時間が増え続けていることがわかります。つまり、BI ツールの処理は「クエリが流れるよりもクエリが増える速度の方が早く Queue が積み上がり続けている」状態になってしまっています。
Queue 1 調査

同メトリクスを、Queue 1 でも確認してみます。
同じ時間帯の Queue 1 は問題なくクエリを処理できており、Queue 詰まりは起きていないことがわかります。
スパイクしている箇所でも「18」となっており、事前に設定した同時実行数「25」を超えていない(7 の余裕がある)ことがわかります。
チューニングによる対応
このような場合に、どう設定変更をすれば対処ができるでしょうか?
結論としては、Manual WLM 利用時において、以下の2つが効果的です。
- 同時実行スケーリングモード(Concurrency Scaling) を有効化する
- メインでの同時実行(Concurrency on main) の値をチューニングする
同時実行スケーリングモード(Concurrency Scaling) を有効化する
ワークロード管理において同時実行スケーリングモード(Concurrency Scaling) は、デフォルトで「オフ」となっており「自動(auto)」に設定することで有効化されます。また、Queue ごとに設定を行う必要があります。

同時実行スケーリングモードを有効にすると、その Queue でさばき切れない「待ち」となるクエリができたタイミングでクラスターが動的に追加され、同時実行数が増加します。
ドキュメントに記載がありませんが、同時実行スケーリングモードを有効化した場合、1台のクラスター追加につき「5つ」の同時実行数が確保されます。同時実行スケーリングモードの設定変更は「動的」であり、即時クラスターへと反映されます。

同時実行スケーリングモード時の最大追加台数は、パラメータグループのパラメータ max_concurrency_scaling_clusters で制御されております。これもドキュメントに記載がありませんが、max_concurrency_scaling_clusters の反映は「静的」であるため、反映にはクラスターの再起動が必要です。
今回、max_concurrency_scaling_clusters は「1」台追加のままで有効化しました。
| Queue No | 同時実行数(スケーリング) | 変更後 | 変化 |
|---|---|---|---|
| Queue1 | 25(off) | 25(off) | |
| Queue2 | 13(off) | 13(auto) | 同時実行スケーリングの有効化 |
| Queue3 | 2(off) | 2(off) | |
| Queue4 | 1(off) | 1(off) | |
| Default queue | 1(off) | 1(off) | |
| 合計 | 42 | 42 |
同時実行スケーリングの無料枠
同時実行スケーリングには無料枠が存在します。
Redshift クラスターは、1 日あたり最大 1 時間の無料同時実行スケーリングクレジットを獲得します。クレジットは、AWS アカウントのアクティブなクラスターについて 1 時間単位で付与され、クレジットが付与された後に同じクラスターでのみ使用できます。アクティブなクラスターあたり最大 30 時間の無料同時実行スケーリングクレジットを累積できます。クラスターが解約されない限り、クレジットは期限切れになりません。
本クラスターでは稼働後30日以上経過していることと、一度も同時実行スケーリングを有効化していないことから、30時間のクレジットが残存していました。また、設定は「1」台追加のため、30時間まで連続使用しても無料枠に留まります。同時実行スケーリングをすぐに有効化した背景にはこの「無料枠の利用」が可能だった点もあげられます。
基本的に同時実行スケーリングは高負荷時のみの利用になるため、1日1時間のクレジットで十分となる想定です。これを超える場合は、この後紹介する同時実行数自体のチューニングが必要です。

後日改めて利用料を確認しましたが、問題なく $0 の請求でした。
同時実行スケーリングモードを有効にした後の負荷

WLMRunningQueries を確認すると、同時実行スケーリングモードを有効にした直後に処理数が 13 から 18(13+5) に増えていることがわかります。
また、WLMQueueWaitTime も直後に下がり始めました。しかし、スケーリング後の「18」でも WLMRunningQueries が張り付いているのがわかります。18 でも不足している状態ということが判明しました。
しかし、1時間半ほど経過すると、18 張り付きが一時的に緩和され、Queue 詰まりが解消されたことがわかります。
同時実行スケーリングが実行されているかの確認方法
Redshift のコンソール、CloudWatch どちらでも確認が可能です。
Redshift コンソール
対象クラスターの「クエリのモニタリング」タブを開きます。加えて、「ワークロードの同時実行」を選択します。
その下部に「同時実行スケーリングアクティビティ」と「同時実行スケーリングの使用」があり、ここに使用状況が描画されます。

指定した範囲時間内での合計使用量(分)も同時に確認できるため、無料のクレジット枠の消費状況を事前に計算・把握することが可能となっています。
CloudWatch コンソール
以下のメトリクスで同時実行スケーリングの状態が確認できます。
- ConcurrencyScalingActiveClusters

WLMRunningQueries と並べてみると、負荷が高いタイミングで適時アクティブになっていることがわかります。
メインでの同時実行(Concurrency on main) の値をチューニングする
ワークロード管理において、各 Queue で同時実行可能な最大数を事前に規定します。
それぞれの Queue ごとに設定可能な最大数は 50 で、またそれぞれの Queue の同時実行数合計も 50 までである必要があります。
手動 WLM を使用した場合、Amazon Redshift は、同時実行レベルが 5 (最大 5 個のクエリを同時実行) のキューを 1 つと、同時実行レベルが 1 の定義済みスーパーユーザーキューを 1 つ設定します。最大で 8 個のキューを定義できます。各キューの同時実行レベルは最大で 50 に設定できます。すべてのユーザー定義キュー (スーパーユーザーキューは含みません) の同時実行レベルの合計の最大値は 50 です。
https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/c_workload_mngmt_classification.html
先にお見せした以下の表の通り、本ワークロード管理の設定は最大の 50 に到達していません。
| Queue No | 同時実行数(スケーリング) | 変更後 | 変化 |
|---|---|---|---|
| Queue1 | 25(off) | 25(off) | |
| Queue2 | 13(off) | 13(auto) | 同時実行スケーリングの有効化 |
| Queue3 | 2(off) | 2(off) | |
| Queue4 | 1(off) | 1(off) | |
| Default queue | 1(off) | 1(off) | |
| 合計 | 42 | 42 |
よって、50 まで Queue を追加することができる余力があるとなります。
加えて、Queue 1 の過去ログを CloudWatch で数か月分析した結果、その最大が「22」に留まることがわかりました。つまり、Queue 1 への割り当てを減らして Queue 2 へと振り替えすることができます。
| Queue No | 同時実行数(スケーリング) | 変更1 | 変更2 | 変化 |
|---|---|---|---|---|
| Queue1 | 25(off) | 25(off) | 22(off) | -3 |
| Queue2 | 13(off) | 13(auto) | 24(auto) | +11 |
| Queue3 | 2(off) | 2(off) | 2(off) | 0 |
| Queue4 | 1(off) | 1(off) | 1(off) | 0 |
| Default queue | 1(off) | 1(off) | 1(off) | 0 |
| 合計 | 42 | 42 | 50 | +8 |
上表の通り手動でワークロード管理の調整を行うことで、Queue 2 は最大「24+5=29」までクエリを同時実行できるようになりました。
メインでの同時実行(Concurrency on main) の値をチューニングした後の負荷
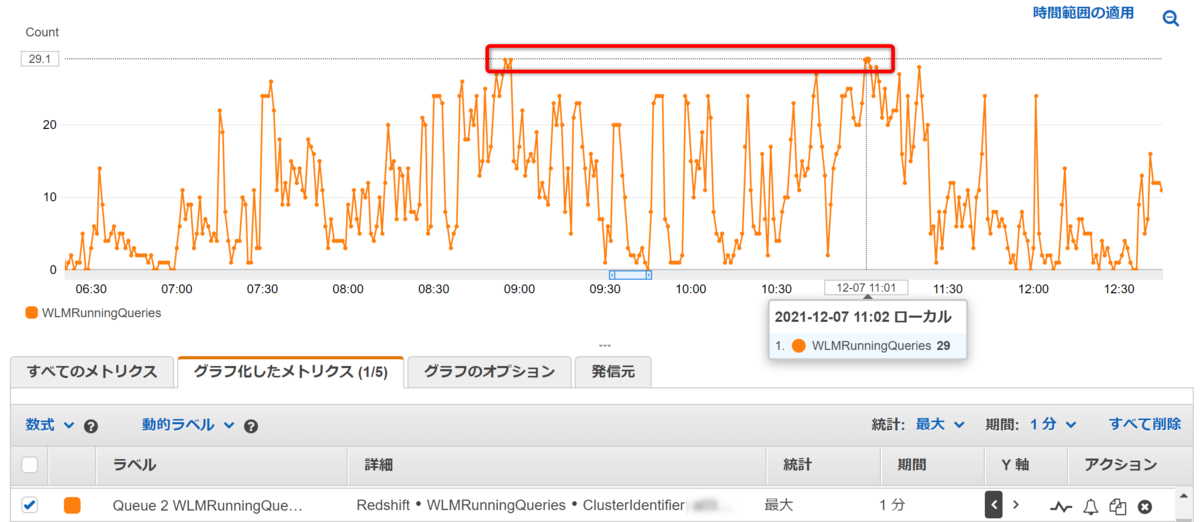
CloudWatch で確認すると、WLMRunningQueries が 29 まで到達している時間帯があるのがわかります。しかし、十分にクエリは処理されています。

Redshift コンソールにおいても待ち時間を示す「青色」がかなり減ったことが確認できました。
加えて、同時実行スケーリングの実行時間は、有効にした日(13+5=最大18)が24時間で「192分」であったのに対し、Queue 2 をチューニング(24+5=最大29)した後は「34分」まで下げることができました。
先にご紹介した通り、同時実行スケーリングは24時間で1時間回復するため、その実行時間を60分以内に抑える必要があります。「メインでの同時実行」のチューニングは、この同時実行スケーリングの処理時間を減らす目的で行いました。
最後の調整
最後に、Queue 1 の同時実行スケーリングも有効化を行いました。それは以下の背景からとなります。
ワークロードの並列実行に 15 を超えるクエリが必要な場合は、同時実行スケーリングを有効にすることをお勧めします。これは、クエリスロット数を 15 より大きくすると、システムリソースの競合が発生し、単一クラスターの全体的なスループットが制限される可能性があるためです。
Queue 1 は「22」のため、有効化しておくほうが安全です。
調整の経緯をまとめると以下の通りになります。
| Queue No | 同時実行数(スケーリング) | 変更1 | 変更2 | 変更3 | 変化 |
|---|---|---|---|---|---|
| Queue1 | 25(off) | 25(off) | 22(off) | 22(auto) | 同時実行スケーリングの有効化 |
| Queue2 | 13(off) | 13(auto) | 24(auto) | 24(auto) | |
| Queue3 | 2(off) | 2(off) | 2(off) | 2(off) | |
| Queue4 | 1(off) | 1(off) | 1(off) | 1(off) | |
| Default queue | 1(off) | 1(off) | 1(off) | 1(off) | |
| 合計 | 42 | 42 | 50 | 50 |
まとめ
本ブログは、Redshift クラスターの運用知見を記載しました。特に Manual WLM を利用している場合での同時実行数チューニングについて、負荷状況を鑑みた実際の対応を記載しました。
以下の2つが主な対応手段です。
- 同時実行スケーリングモード(Concurrency Scaling) を有効化する
- メインでの同時実行(Concurrency on main) の値をチューニングする
これらの対応手段について詳細な対応を記載しました。またこれらのポイントを運用の視点でまとめると以下の通りになります。
- 同時実行スケーリングモードの有効化は「動的」であり即時クラスターへ反映される
- 同時実行スケーリングモードの最大追加台数は「静的」であり反映にはクラスターの再起動が必要
- 同時実行スケーリングでは 1 つの追加クラスターにつき「 5 つの同時実行数」が追加される
- 同時実行スケーリングには無料のクレジットがあり、24時間毎に1時間の蓄積が行われ、最大30時間の蓄積が可能
- Manual WLM において Queue ごとの同時実行数は全体の合計でも 50 以内にする必要がある
- メインでの同時実行数の修正は「動的」であり即時クラスターへ反映される
- メインでの同時実行数を調整することで、日々の同時実行スケーリング実行時間を「無料でカバーし切れる1時間未満」に抑える
本ブログ記事のまとめは以上となります。
それでは、またお会いしましょう。
佐竹 陽一 (Yoichi Satake) エンジニアブログの記事一覧はコチラ
セキュリティサービス部所属。AWS資格全冠。2010年1月からAWSを業務利用してきています。主な表彰歴 2021-2022 AWS Ambassadors/2020-2025 Japan AWS Top Engineers/2020-2025 All Certifications Engineers。AWSのコスト削減やマルチアカウント管理と運用を得意としています。