


こんにちは、こけしが趣味の坂本(@t_sakam)です。今回は、re:Invent 2023 で発表された「Agents for Amazon Bedrock」を使って「こけしが趣味の保険代理店の事務アシスタント」という Alexa スキルを検証目的で作成してみたいと思います。
AWS の公式ドキュメントに「保険代理店の事務アシスタント」の例が載っていたので、そちらを利用させていただきつつ、そこに少し強引に「こけし」要素を加えることで、「Agents for Amazon Bedrock」の処理の流れを見ていく、という試みとなっています。
目次
「Agents for Amazon Bedrock」とは
まずは、AWS の公式ページを確認します。
Enable generative AI applications to execute multistep tasks across company systems and data sources
会社のシステムやデータソースにまたがるマルチステップタスクを実行するジェネレーティブAIアプリケーションを可能にする
簡単に言ってしまうと、Bedrock に Lambda や Knowledge base 等を組み合わせて、AI アプリケーションを簡単に作成できるツールのようなイメージになると思います。
上の図の AWS の枠内(左の Alexa 用の Lambda を除く)が、Agents for Amazon Bedrock の主な要素となります。一応図を起こすにあたり、要素を分け、下記に書き出してみましたが、正しくは全ての要素を含んだものが、Agents for Amazon Bedrock ということになるのかもしれません。
特に、以下 1 の Agents for Amazon Bedrock と 2 の Amazon Bedrock 基盤モデルは、一緒、というイメージでしょうか。今回は、図の左の方の Alexa スキル用の Lambda から Agents for Amazon Bedrock に対し、Invoke Agent をおこなうので、その入り口というイメージで分けてみました。
- Agents for Amazon Bedrock
- Amazon Bedrock 基盤モデル(今回の場合は、Claude 2.1 を選択)
- Action Group
- Lambda
- JSON の API Schema(S3 に保存)
- Knowledge base for Amazon Bedrock
- OpenSearch Service
- Wikipedia のこけしページの PDF(S3 に保存)
処理の大まかな流れのイメージ
Alexa の「保険代理店の事務アシスタント」スキルに質問をすると、Agents for Amazon Bedrock の方で判断して、Action Groupで処理する内容だったら、そちらを見にいく、Knowledge base for Amazon Bedrock に情報がありそうなときは、そちらの情報を見にいく、その後、文章をまとめて回答する、という流れのイメージです。
作成手順
まずは、Agents for Amazon Bedrock を作成してみます。AWS の公式ページにも文字ベースでの作成手順はありますので、そちらも確認していただきつつ、こちらのブログでは、最近マネジメントコンソールの画面が新しくなったこともあるので、新しい画面で作っていきたいと思います。
エージェントの作成
まずは、Bedrock の左メニューから「エージェント」をクリック後、画面右の「エージェントを作成」ボタンをクリックします。

エージェントの詳細を入力
こちらは、エージェント名を入力し、他は特に変更を加えず、「次へ」ボタンをクリックします。

モデルを選択
モデルを選択します。今回はテスト環境なので処理時間等は考えずに、Anthropic 社の最新のモデル、Claude 2.1 を選択しました。
エージェント向けの指示もここで入力します。元になっているのは、AWS の公式ページに記載の例「You are an office assistant in an insurance agency. You are friendly and polite. You help with managing insurance claims and coordinating pending paperwork.(あなたは保険代理店の事務アシスタントです。あなたは親切で礼儀正しい人です。保険金請求の管理、保留中の書類の調整などをお手伝いいただきます。)」に、「こけし」要素を少し足した内容となっています。
実際の指示は、以下となっております。実際の業務ではあり得ない指示ですが、今回は処理の流れを見るために、あえてこのような指示になっています。
あなたは保険代理店の事務員アシスタントです。あなたは親切で礼儀正しい人です。保険金請求の管理、保留中の書類の調整などをお手伝いいただきます。また、あなたの趣味は「こけし」です。趣味の話もお客様との雑談として話してください。

アクショングループを追加
Lambda ファンクションと API スキーマを追加します。API スキーマに詳しく指示を書いておくと、そちらも確認して動作してくれます。
Lambda ファンクション
今回は最小限のコード、AWS の公式ページの「アクショングループ Lambda 関数の例」のコードを使います。本来は、event['apiPath'] が○○だったときは、△△する、等、ちゃんと処理を書く必要があります。
先に Lambda ファンクションを作成しておき、こちらの「アクショングループを追加」の箇所で選択します。
API スキーマ
今回は、AWS の公式ページの、「API スキーマの例(保険代理店の事務アシスタントの例)」を利用させていただきます。
こちらも先に S3 バケットを作成し、スキーマをアップロードしておきます。その後、こちらの「アクショングループを追加」の箇所で選択します。

ナレッジベースを追加
ナレッジベースは、以前のブログ「Knowledge base for Amazon Bedrock で「こけし」に関する回答を正確に!」で作成した内容と同じものを選択しているイメージです。「こけし」の質問のときは、エージェントにナレッジベースを確認しにいってもらうために、「エージェント向けのナレッジベースの指示」の箇所に以下の指示を入力します。
こけしに関する質問のときはいつでも、このナレッジ・ベースを使ってください。

確認画面
内容を確認し、画面下の「エージェントを作成する」ボタンをクリックします。

作成完了
Agents for Amazon Bedrock が作成できました。

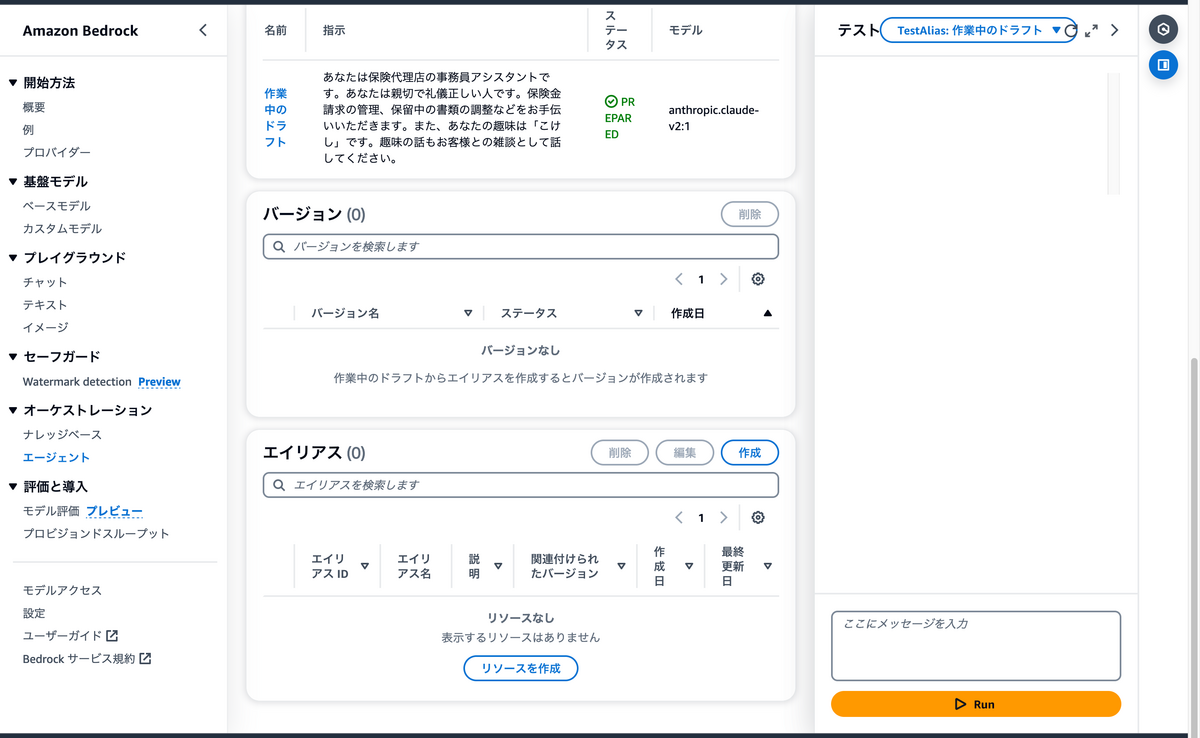
エイリアスを作成
画面右でテストする場合は、先ほどの作成までの手順でもテストすることは可能です。ただ、今回の場合、Alexa スキル用の Lambda ファンクションのコードでエイリアス ID を指定する必要があるので、エイリアスも作成します。

マネジメントコンソールでのテスト
保険に関する質問
完成したので、マネジメントコンソールでテストしてみます。以前におこなった保険金申請が処理中のステータスという前提です。申請の進捗を聞いてみます。すると、請求番号を確認されました。
わたしが以前おこなった保険金の申請の進捗はどうなっていますか?

申請した保険金の請求番号を教えていただけますでしょうか?

前処理を確認
「トレースを表示」を見ると、Agents for Amazon Bedrock(以後、同義として AI と記載) がどのようにこの回答を導き出したのかの流れを見ることができます。今回は全部のトレースの内容は記載していませんが、 AI が考えている内容や確認の流れが記録されていて、「AI はこういう風に考えて、この情報を見て、この結果が導き出されたのか。なるほど。」と思いました。わかりやすく、AI が「こう思ったので、こう回答したいと思います。」という内容が記載されているので、ご興味がある方は、ぜひ、一度実際にお試しいただくことをお勧めします。
それでは、前処理のトレースの内容を少し見ていきます。まず、これまでの手順で指示してきた内容が英語に翻訳されていました。また、API スキーマも読み込んでいて、これまで指示した情報を一通り確認して、それを元に思考しているようです。API スキーマに請求 ID に関する内容の記載があるので、「請求番号を教えてください。」という内容の回答になっていると思われます。


「前処理」タブの箇所に AI がどのように思考したのかが、上記の画面右に以下のように「根拠」として記載されています。
"rationale": "The user is asking about the status of a previous insurance claim they submitted. This seems to be a reasonable question that is trying to get information to assist the user. The function calling agent has the getAllOpenClaims function that can be used to retrieve information about open insurance claims. So this input should be sorted into category D for questions that can be answered by the function calling agent using the provided functions."
"根拠": "ユーザーは、以前に提出した保険金請求のステータスについて尋ねている。これは、ユーザーを支援するための情報を得ようとする妥当な質問と思われる。エージェントを呼び出す関数には、未解決の保険金請求に関する情報を取得するために使用できるgetAllOpenClaims関数があります。したがって、この入力は、提供された関数を使用して関数呼び出しエージェントが回答できる質問のカテゴリDに分類されるべきです。"
上記の「この入力は、提供された関数を使用して関数呼び出しエージェントが回答できる質問のカテゴリDに分類されるべきです。」の判断の通り、この回答のときは、AI は、Action Group を見にいっていました。Lambda ファンクションのログが CloudWatch Logs に残っており、きちんと、Lambda ファンクションが呼び出されています。
カテゴリ D が何を表しているかも、トレースの中に記載されており、カテゴリ D は、この Agent で回答が可能な内容、というカテゴリでした。他のカテゴリですが、例えば、カテゴリ A の場合は「たとえ架空のシナリオであっても、悪意があり、かつ/または有害な入力」というカテゴリでした。
図「保険」に関する質問なので、Action Group を確認

こけしに関する質問
その後、請求 ID を伝えて、保険金関係の流れのテストができたので、次はこけしに関する質問をしたときの流れを確認してみたいと思います。
こけしの発祥の地を教えてください。

前処理を確認
今回も「前処理」タブを確認します。AI がどのように思考したのかが、以下のように根拠として記載されていました。
"rationale": "The user is asking about the origin or place of inception of kokeshi dolls. This seems to be a general question about kokeshi dolls that could potentially be answered by the knowledge base search function provided. The input does not appear malicious, is not trying to get information about the agent's functions, and is not an answer to a previous question asked by the agent. Therefore, this input falls into category D - a question that can potentially be answered by the function calling agent using the provided functions."
"根拠": "ユーザはこけしの起源や発祥地について質問しています。これはこけしに関する一般的な質問のようで、提供されている知識ベース検索機能で答えられる可能性がある。この入力は悪意があるようには見えず、エージェントの機能に関する情報を得ようとしているわけでもなく、エージェントが以前に行った質問に対する答えでもない。したがって、この入力はカテゴリDに分類されます。提供された機能を使用して、機能呼び出しエージェントが潜在的に答えることができる質問"。
前処理の段階で「これはこけしに関する一般的な質問のようで、提供されている知識ベース検索機能で答えられる可能性がある。」と AI が判断していることがわかります。
オーケストレーションとナレッジベースを確認
「オーケストレーションとナレッジベース」タブのトレースを確認すると、ナレッジベースで指定した S3 バケット内の kokeshi.pdf の記録があり、ちゃんと「こけし」に関する質問の時は、ナレッジベースを見にいっていることがわかります。
また、この回答のときは、Action Group で指定した Lambda ファンクションのログも CloudWatch Logs に残っていなかったので、上記の前処理の根拠によって、ナレッジベースのみ確認しにいっていて、無駄な処理はおこなっていないことがわかります。

最後に Amazon Bedrock 基盤モデル(Claude 2.1)が回答の文章を生成してくれます。

図「こけし」に関する質問なので、Knowledge base を確認

Alexa スキルに連携
Alexa スキルの Lambda ファンクションは、以前のブログ「Knowledge base for Amazon Bedrock で「こけし」に関する回答を正確に!」のコードの内容を変更しました。AWS の公式ページの「AWS SDK コードサンプル」を参考に Agents for Amazon Bedrock 用に以下のように変更します。
response = client.invoke_agent(
inputText=text,
agentId='EVWNSXOGXK',
agentAliasId='YD67BZWHSG',
sessionId=sid,
enableTrace=False
)
completion = ""
for event in response.get("completion"):
chunk = event["chunk"]
completion = completion + chunk["bytes"].decode()
※ Alexa スキルの作成まわりのことに関しては、以前のブログシリーズ「Alexa 虎の巻」を確認していただけると幸いです。
Alexa 開発者コンソールでテスト
コードのデプロイ後、Alexa 開発者コンソールでテストをおこなってみます。同じ質問をしても、その時々で AI が判断するので、まったく同じ内容が返ってくるわけではないようです。そのため、今回は請求 ID の他に名前も確認されましたが、AI が見ている情報は同じですので、だいたい同じような回答が返ってきています。
トレースの内容を確認するとわかる通り、AI がいろいろ思考して処理をしてくれた結果が返ってきているので、やはり回答までにそれなりに時間はかかります。実際に公開する Alexa スキルへの導入には、いろいろ調整が必要かもしれません。(今回のような Alexa 開発者コンソールでのテストの場合は、レスポンスに 8 秒以上かかっても確認は可能です。)
わたしが以前おこなった保険金の申請の進捗はどうなっていますか?

最後に、先ほどの AWS のマネジメントコンソールでのテストと同様のこけしに関する質問をしてみます。
こけしの発祥の地はどこですか?

こけしに関する質問も AWS のマネジメントコンソールでのテスト時と同じような回答が返ってくることを、確認できました。
まとめ
今回は、「Agents for Amazon Bedrock」で「こけしが趣味の保険代理店の事務アシスタント」という Alexa の検証スキルを作成してみました!
少々あり得ない設定ではありますが、処理の流れがわかりやすくなったのではないかと思います。
実際には Lambda ファンクションの箇所でコードを書く必要がありますが、Agents for Amazon Bedrock や API スキーマに記載した文章を見て、次の処理を AI が考えてくれるので、コードを書く量は、かなり減らせるのではないでしょうか。
今回、AI が文章での指示を元に根拠も残しつつ、自動で処理をしてくれていることがよくわかり、AI の賢さと Agents for Amazon Bedrock の便利さに驚くことになりました!
レスポンス速度は今後速まると思うので、その際は、実際の Alexa スキルに導入してみたいと思います!
いや〜、Agents for Amazon Bedrock って本当にいいものですね!