

こんにちは。
ブッシュクラフトにハマりかけている島村です。
最近は、ロープワークを練習しようと考えています。
さて、今回はAurora Serverless v2(PostgreSQL互換)を使用して、負荷をかけてみます。
負荷をかけた際にAurora Serverlessv2がどの程度の時間でスケールアップ/スケールダウンするのか、AWS公式ブログを参考にしながら
挙動を確認してみたいと思います。
Aurora Serverlessってなに?という方は、以下のブログを読んでみてください。
構成
今回のAWS環境構成です。
EC2を2台使用して、Aurora Serverlessに負荷をかけていきます。
単純なスケールの挙動確認だけなら一台だけでも良いと考えます。
せっかくなので、読み取り処理/書き込み処理それぞれがスケールしたタイミングで向上しているかも合わせて確認したいため2台用意しました。
負荷をかけるツールですが、pgbenchを使用します。
pgbenchはPostgreSQLに含まれています。
そのため、EC2にはPostgreSQL(バージョン14系)をインストールします。

インスタンスタイプはc6i.largeを選択しました。
さいさいt3.mediumを負荷をかけている途中で、バーストクレジットを使い切ってタイムアウトしてしまいました。
pgbenchの実行はSystems Manager Runcommandを使用して実行します。
そのため、Systems Managerのマネージドインスタンスに登録されるようネットワーク環境をご用意ください。
環境作成
EC2の作成
それでは環境構築を行なっていきます。
EC2はAmazon Linux2のAMIを使用します。
EC2は同じ構成なので、1台のセットアップが終えてからAMIを取得して複製します。
EC2の作成は特に詳細は解説せずに進みます。
PostgreSQLをインストールする
EC2が作成できたら、PostgreSQLをインストールするため、Systems Manager Session Manager経由でログインします。
yumでもPostgreSQLはインストールできるのですが、現状確認すると、15系がインストールされそうです。
sudo yum list available | grep postgresql collectd-postgresql.x86_64 5.12.0-16.amzn2023.0.2 amazonlinux postgresql15.x86_64 15.0-1.amzn2023.0.2 amazonlinux postgresql15-contrib.x86_64 15.0-1.amzn2023.0.2 amazonlinux postgresql15-docs.x86_64 15.0-1.amzn2023.0.2 amazonlinux postgresql15-llvmjit.x86_64 15.0-1.amzn2023.0.2 amazonlinux postgresql15-plperl.x86_64 15.0-1.amzn2023.0.2 amazonlinux postgresql15-plpython3.x86_64 15.0-1.amzn2023.0.2 amazonlinux postgresql15-pltcl.x86_64 15.0-1.amzn2023.0.2 amazonlinux postgresql15-private-devel.x86_64 15.0-1.amzn2023.0.2 amazonlinux postgresql15-private-libs.x86_64 15.0-1.amzn2023.0.2 amazonlinux postgresql15-server.x86_64 15.0-1.amzn2023.0.2 amazonlinux postgresql15-server-devel.x86_64 15.0-1.amzn2023.0.2 amazonlinux postgresql15-static.x86_64 15.0-1.amzn2023.0.2 amazonlinux postgresql15-test.x86_64 15.0-1.amzn2023.0.2 amazonlinux postgresql15-test-rpm-macros.noarch 15.0-1.amzn2023.0.2 amazonlinux postgresql15-upgrade.x86_64 15.0-1.amzn2023.0.2 amazonlinux postgresql15-upgrade-devel.x86_64 15.0-1.amzn2023.0.2 amazonlinux
amazon-linux-extras経由でPostgreSQLバージョン14をインストールします。
Amazon Linux2だとデフォルトでamazon-linux-extrasリポジトリが使用できます。
amazon-linux-extras | grep postgresql 6 postgresql10 available [ =10 =stable ] 41 postgresql11 available [ =11 =stable ] 58 postgresql12 available [ =stable ] 59 postgresql13 available [ =stable ] 63 postgresql14 available [ =stable ]
トピックを有効にします。
sudo amazon-linux-extras enable postgresql14 postgresql14=latest enabled [ =stable ]
有効にした後、インストールコマンドを実行します。
contrib モジュールもインストールしておきます。
sudo yum -y install postgresql sudo yum -y install postgresql-contrib
pgbench実行用のシェルを作成します。
ホームディレクトリに /benchmark というディレクトリを作成し、benchmark.shというファイルを作成します。
作成後、benchmark.shの権限を変更します。
chmod +x benchmark.sh
スクリプトファイルの中身は次のとおりです。
#!/bin/bash # SYNTAX FOR RUNNING FOR A SPECIFIC AMOUNT OF TIME IN SECONDS pgbench -c $BENCHMARK_CONNECTIONS -j $BENCHMARK_THREADS -T $BENCHMARK_TIME -U $BENCHMARK_USER -d $BENCHMARK_DB -h $BENCHMARK_HOST -p $BENCHMARK_PORT -f $BENCHMARK_SQL_FILE
pgbenchを扱うのが初めてなので、pgbenchオプションで何をやっているか理解するためメモ程度に残しておきます。
| 使用されているオプション | 内容 |
|---|---|
| -c(clients) | 同時実行されるデータベースセッション数を指定する。デフォルト(指定しない場合)は1。 |
| -j(threads) | pgbench内のワーカースレッド数を指定する。 |
| -T(Second) | 指定した秒数でテストを実行します。(※クライアントあたり) |
| -U(login) | DBに接続するユーザ名 |
| -d(debug) | デバッグ用出力を表示する。 |
| -h(hostname) | 接続先データベースホスト名を指定する。 |
| -f(filename) | トランザクションスクリプトを実行されたスクリプトリストに追加する。 |
次に、Writerノードに負荷をかけるためのトランザクションファイルを作成します。
ファイル名は任意で問題ないです。
\set order_item_quantity random(1,100)
\set order_item_price double(random(1,1000))
\set order_payment double(random(1, :order_item_price))
\set order_update_id random(1,10000000)
\set order_delete_id random(1,10000000)
BEGIN;
-- get a unique number for customer order
SELECT nextval('order_seq') \gset p_
-- insert customer_order
INSERT INTO customer_order(order_id, order_description, order_date) VALUES (:p_nextval, concat('description for order',:p_nextval), CURRENT_TIMESTAMP);
-- insert order item
INSERT INTO order_item(order_id, item_description, quantity, price) VALUES (:p_nextval, concat('item count is ',:order_item_quantity) ,:order_item_quantity, :order_item_price);
-- insert order payment
INSERT INTO order_payment(order_id, amount, payment_date) VALUES (:p_nextval, :order_payment, CURRENT_TIMESTAMP);
-- update random order item
UPDATE order_item set item_description = concat(item_description,' random update') WHERE order_id = :order_update_id;
-- delete random order item
DELETE FROM order_item WHERE order_id = :order_delete_id;
END;
Readerノード用の読み取りトラフィックの負荷をかけるファイルも用意します。 こちらもファイル名は任意で。
\set order_id random(1,10000000) BEGIN; -- select random orders SELECT SUM(order_item.PRICE * order_item.quantity) FROM customer_order , order_item WHERE customer_order.order_id = :order_id AND customer_order.order_id = order_item.order_id; --select random order payment SELECT customer_order.order_id, order_item.item_description, order_item.quantity, order_payment.amount FROM customer_order , order_item , order_payment WHERE customer_order.order_id = :order_id AND order_item.order_id = customer_order.order_id AND order_payment.order_id = customer_order.order_id; END;
ここまでできたら、EC2のイメージを取得し、複製します。
負荷をかけてみる
実行手順
実際に負荷をかけてみます。
まずは読み込み処理の負荷をかけていきます。
[Systems Manager]コンソールへ移動し、[Run Command]を選択します。
ドキュメント検索欄に[AWS-RunShellScript]を入力し、選択します。
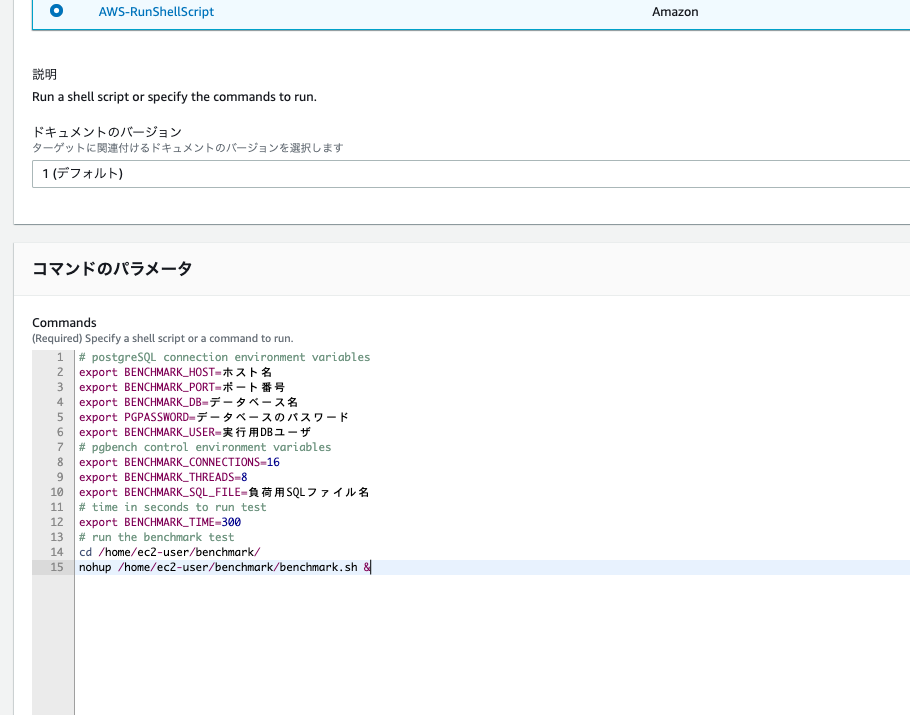
コマンドは以下の通り入力します。
まずは読み取り処理の負荷をかけるので、BENCHMARK_SQL_FILEは読み取り用のSQLファイルを指定します。
# postgreSQL connection environment variables export BENCHMARK_HOST=ホスト名 export BENCHMARK_PORT=ポート番号 export BENCHMARK_DB=データベース名 export PGPASSWORD=データベースのパスワード export BENCHMARK_USER=実行用DBユーザ # pgbench control environment variables export BENCHMARK_CONNECTIONS=16 export BENCHMARK_THREADS=8 export BENCHMARK_SQL_FILE=負荷用SQLファイル名 # time in seconds to run test export BENCHMARK_TIME=600 # run the benchmark test cd /home/ec2-user/benchmark/ nohup /home/ec2-user/benchmark/benchmark.sh &
10分間負荷をかけ続けて、5分後に同じインスタンスから負荷をかけてみます。
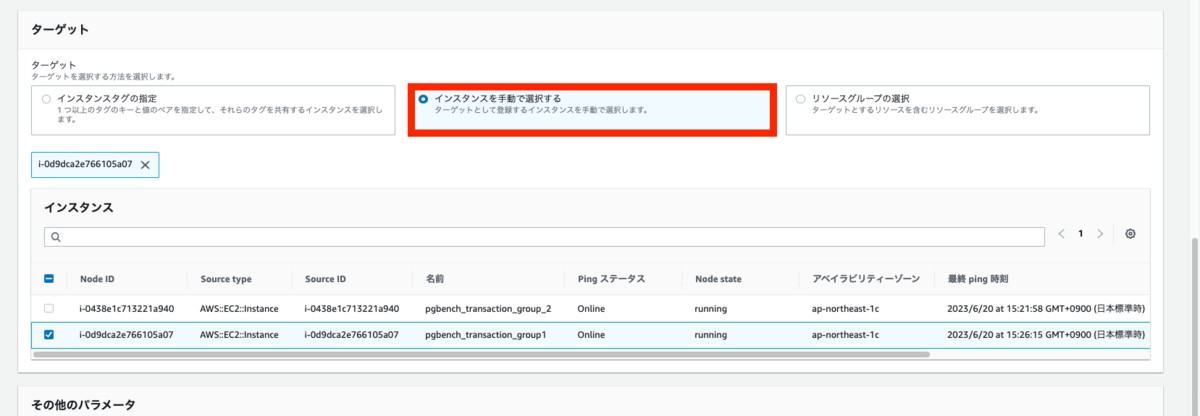
実行するインスタンスを指定します。今回は手動で選択しましょう。
2台のうちどちらかを指定します。
今回はコマンド結果はS3に出力せずに実行します。
5分後、同様の手順で異なるインスタンスから負荷をかけてください。
スケーリングの挙動確認
リーダーインスタンス
まずは、ServerlessDatabaseCapacityメトリクスだけを確認し、どのくらいの時間でスケールするか確認します。

1回目に実行したのは、13:47:34で、2回目に実行したのは、13:52:31です。
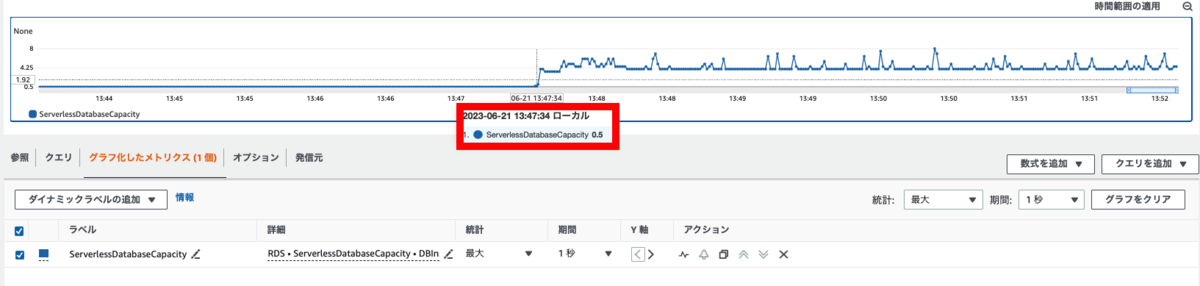
1秒単位で値の変化を確認していきます。
13:47:34時点では設定している最小ACUである、0.5になっています。
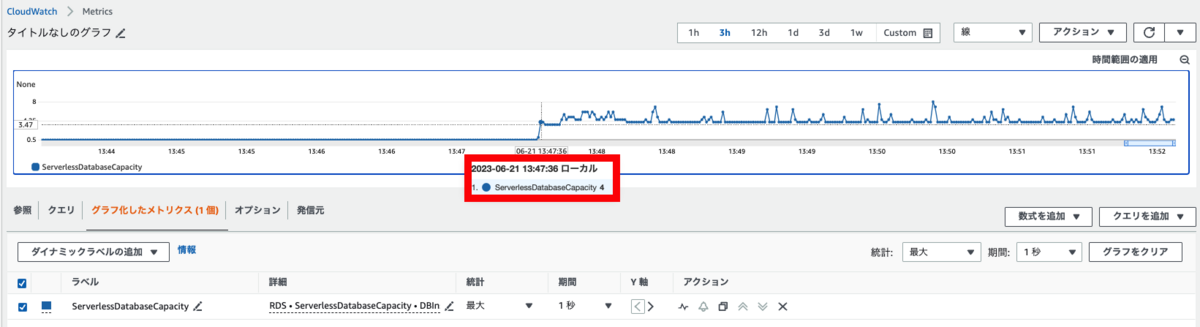
2秒後にはACUが4になっており、スケールしていることが確認できます。
ライターインスタンス
念の為ライターインスタンスでも確認しました。

1回目に実行したのは、14:50:45で、2回目に実行したのは、14:55:12です。
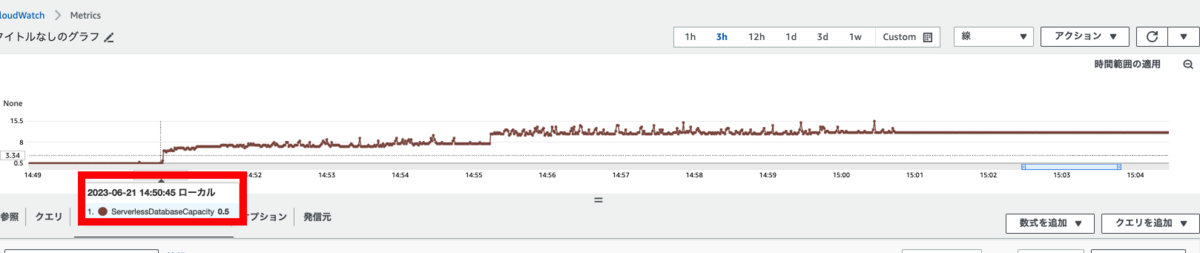
リクエストを受け付けた時間は最小ACUである0.5であることが確認できます。
1秒後のメトリクスを確認すると、1.5になっていました。スケーリングが始まっていることが確認できます。

読み取り処理の負荷を確認する
負荷をかけている時のパフォーマンスはCloudWatchで確認していきます。
確認するメトリクスは以下の通りです。
| メトリクス名 | 内容 |
|---|---|
| ServerlessDatabaseCapacity | 使用しているACUの容量を確認できます。クラスターレベルでは平均値が確認できます。インスタンスレベルではインスタンスが使用しているACU量を確認することができます。 |
| ACUUtilization | 最大ACUに対しての使用量です。ワークロードの負荷に対して、このメトリクスのパーセンテージが100%になっている場合、最大ACUが不足している可能性があります。 |
| FreeableMemory | 使用可能なメモリ量です。Aurora Serverless v2ではACUが消費され、スケールする度にメモリ量が増えるため0になることはありません。 |
| Read Latency | 1 回のディスク I/O 操作にかかる平均時間を確認できます。バッファキャッシュを使用している場合、低下する値です。 |
| Read Throughput | 1 秒あたりのディスク I/O 操作の平均回数を確認できます。バッファキャッシュを使用している場合、低下する値です。 |
| BufferCacheHitRatio | バッファキャッシュのヒット率を確認できます。 |
| DataBaseConnections | クライアント接続数を確認します。 |
| CPU Utilizations | CPU使用率を確認します。 |
読み取りパフォーマンス
ServerlessDatabaseCapacity以外も確認していきます。
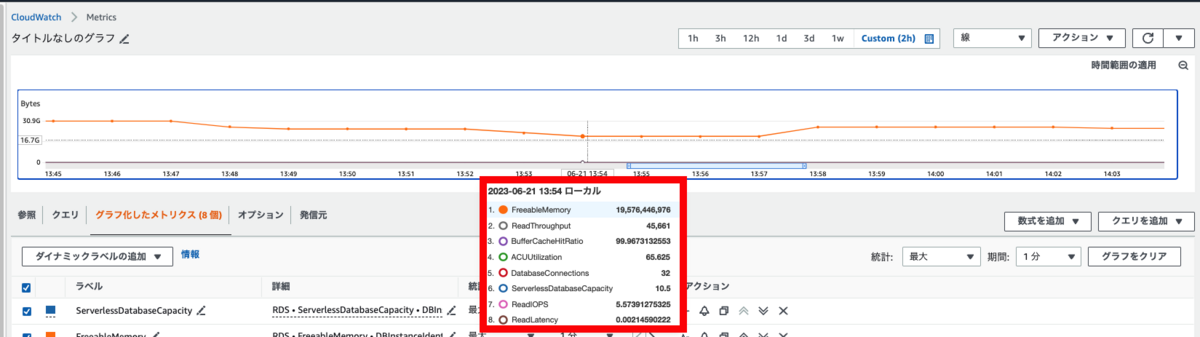
Database Connectionsメトリクスを確認すると、32になっています。
今回クライアントは1台のインスタンスあたり16クライアントとしたので、2台から接続を受けていることが確認できます。
Read ThroughputやRead IOPSの値としては下がってきてはいるものの、BufferCacheHitRatioがほぼ100となっているため
ほとんどバッファキャッシュで処理できているものかと推測できます。
キャッシュヒットしていないものがわずかながらあり、そのリクエストでディスクアクセスが生じてIOPS/スループットの値が低いものになっていますね。
バッファキャッシュを使用している分、代わりに利用可能なメモリが減ってきていますね。
Read Latencyに関しては負荷をかけている時間帯で多少変化はしているものの、ほぼ変化はしていませんでした。
書き込み処理の負荷を確認する
読み取り処理のパフォーマンス確認が終えたら、書き込み処理用のトランザクションファイルを指定し、負荷をかけていきます。
書き込み処理で確認するメトリクスは以下の通りです。
| メトリクス名 | 内容 |
|---|---|
| ServerlessDatabaseCapacity | 使用しているACUの容量を確認できます。クラスターレベルでは平均値が確認できます。インスタンスレベルではインスタンスが使用しているACU量を確認することができます。 |
| ACUUtilization | 最大ACUに対しての使用量です。ワークロードの負荷に対して、このメトリクスのパーセンテージが100%になっている場合、最大ACUが不足している可能性があります。 |
| FreeableMemory | 使用可能なメモリ量です。Aurora Serverless v2ではACUが消費され、スケールする度にメモリ量が増えるため0になることはありません。 |
| Write Latency | 1 回のディスク I/O 操作にかかる平均時間を確認できます。 |
| WriteThroughput | 永続的ストレージに 1 秒ごとに書き込まれた平均バイト数を確認できます。 |
| WriteIOPS | 1 秒あたりに生成された Aurora ストレージ書き込みレコードの数を確認できます。 |
| DataBaseConnections | クライアント接続数を確認します。 |
| CPU Utilizations | CPU使用率を確認します。 |
書き込みパフォーマンス
書き込み処理についても負荷をかけてメトリクスを確認していきます。
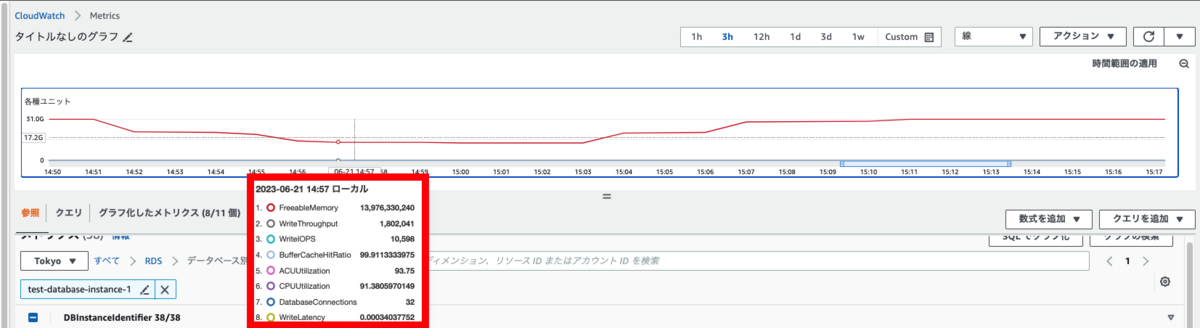
読み取りパフォーマンスを確認した時と同様にDataBaseConnectionsの値が32であることが確認できます。
Write Throughputの線が上がり幅を見せていることから、書き込みパフォーマンスも向上し続けていることが確認できます。
ACUUtilizationが91%と高くなっています。
処理はできているものの、これ以上の負荷がかかると、ACU上限に抵触しスケーリングすることができず、ボトルネックとなりそうです。
最後に
いかがでしたでしょうか。
Aurora Serverless v2はスケーリングされるとは知っていましたが、どの程度でスケーリングするのか気になったので検証をしてみました。結果的に想像よりも早くスケーリングすることが知れてよかったです。
オンデマンドのAuroraは常に指定したスペックの料金がかかってしまいますが、Aurora Serverlessだとリクエストに応じてスケーリングするのでコスト削減にも活用できそうですね。
参考
島村 輝 (Shimamura Hikaru) 記事一覧はコチラ