

こんにちは! エンタープライズクラウド部技術2課の日高です。
もし私のことを少しでも知りたいと思っていただけるなら、私の後輩が書いてくれた以下のブログを覗いてみてください。
本ブログではAWSでのDisaster Recovery(ディザスタリカバリ)について記載します。
今後Disaster Recovery(ディザスタリカバリ)はDRと表記します。
はじめに
下記のAWS でのディザスタリカバリ (DR) アーキテクチャを参考にAWSでのDisaster Recoveryについて記載していきたいと思います。
本ブログは「AWS初心者の方が、ブログを通してAWSでのDRの選択肢を理解する。」ことを目的として記載します。
前提知識
Disaster Recoveryの概要
そもそも、DRとは自然災害・人為的災害等によるシステム障害時にシステムを復旧する事や、そういった状態になることを予防(または回避)する戦略や体制のことをいいます。
DRの主な目的は災害や障害による業務への影響を最小限に抑え、組織がスムーズに運営を続けられるようにすることです。
Disaster Recoveryの基本方針
Disaster Recoveryの概要で挙げた自然災害・人為的災害とは、具体的に何を指すのでしょうか?
一例を下記に記載します。
- 地震: 地震によってデータセンターやサーバー施設が損傷し、システムが停止する可能性があります。
- 洪水: 洪水によって電力供給が中断し、データセンターの機器が損傷することがあります。
- 嵐やハリケーン: 強風や竜巻、ハリケーンによって通信ラインや通信タワーが破壊され、ネットワークが利用不能になることがあります。
- サイバーセキュリティ攻撃: ハッカーやマルウェアによるサイバーセキュリティ攻撃が、システムへの不正アクセス、データの盗難、システムの停止を引き起こすことがあります。
- テロ攻撃: テロリストによる物理的な攻撃が、データセンターや通信インフラに損傷を与え、システムの中断を引き起こす可能性があります。
- 人為的エラー: 誤って重要なデータを削除したり、システム設定を誤ったりすることによって、システムの障害が発生することがあります。
簡単に思いつくものを例として挙げましたが、他にも色々な例が想像できると思います。
また世間一般的なものだけではなく、内部プロセスの問題や業界固有の規制など組織特有の例も挙げられると思います。
これらの全てのケースに対して完璧に備えることは金額面でも負担面でも現実的ではありません。
そのためDRを考える上では最初に「会社としてどんな災害に備えるのか?」を定義する必要があります。
上記で定義した災害に対して「どのように復旧するか?予防するか?回避するか?」を次に定義し、アーキテクチャの計画・構築をしていきます。
実際に運用が始まってからも、継続的に見直し・改善をしていくことで災害や障害による業務への影響を最小限に抑え、組織がスムーズに運営を続けられるようにします。
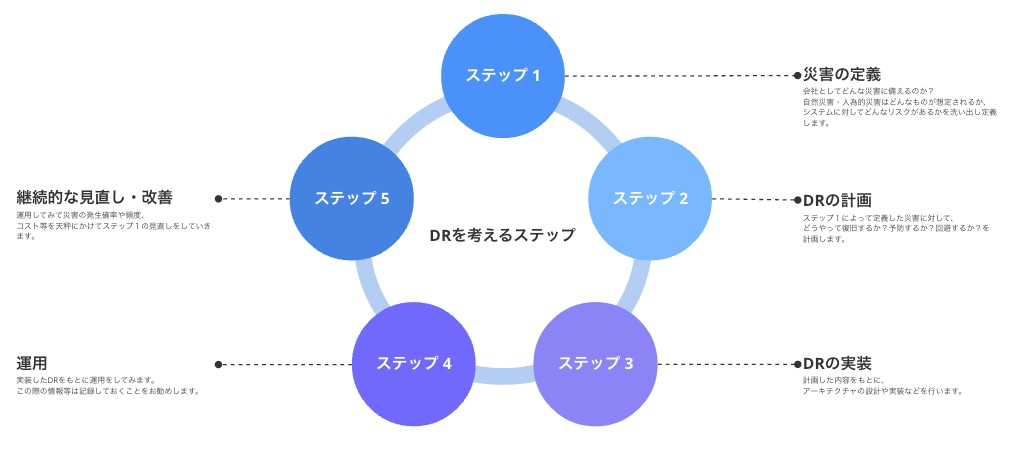
DRの基本方針をまとめると上記のサイクル図のようなイメージになります。
これらの各ステップを考える上で指標となるのがRTO、RPO、RLOです
Disaster Recoveryを考える上での重要な指標
DRを考える上で重要になる指標がRTO、RPO、RLOの3つです。
これらの指標は、各々が関連し合っています。
また、3つの指標を高めていけば行くほどコストが増えていきます。
そのため、コストと3つの指標のバランスを取りながらDR戦略を考えていく必要があります。
この章では、RTO、RPO、RLOの3つの指標を解説することに努めます。
これらの指標をもとに、どのようにAWS上でのDR戦略を選択すればいいかについては「4.AWSでのDR戦略の決定方針」にまとめます。
RTO(Recovery Time Objective)
RTO(Recovery Time Objective)は、システムの復旧を「どのくらいの時間で復旧するか」を示す指標で、目標復旧時間とも言われます。
つまり、RTOはシステムの復旧にかかる時間を明確にするために設定されます。
RTOを考える際は以下のポイントを考えてみてください。
- システムのダウンやサービス停止が利用者(顧客、利用者、ステークホルダーなど)にどのくらいの影響を与えるか?
- システムダウンから復旧までの最大許容時間はどれくらいか?
- どれくらいのコスト(予算)をかけることができるのか?
RPO(Recovery Point Objective)
RPO(Recovery Point Objective)は「どの時点までのデータを復旧するか」を示す指標で、目標復旧時点とも言われます。
要するに、システムやデータベースが障害を受けた場合、過去のある特定の時点までのデータを復旧する目標を示すものです。
RPOを考える際は以下のポイントを考えてみてください。
- 災害が起きてからどのくらいの時間分のデータが戻ればいいか?
- データのバックアップを最後に行った時点から、災害や障害が発生しサービスが停止するまでの期間中に、データがどれだけ失われても許容できるか?
- どのデータの重要度が高いか?
RLO(Recovery Level Objective)
RLO(Recovery Level Objective)はどの程度(範囲や数値、能力)まで復旧させるかを示す指標で、目標復旧レベルとも言われます。
RLOの設定対象となる「レベル」は多岐にわたります。
例えば、物理的な施設のキャパシティ、生産能力、商品やサービスの品質などが考えられます。
RLOを考える際には以下のポイントを考えてみてください。
- 業務上重要なシステムは何か?
- どのくらいの範囲や能力まで復旧させるか?
AWSのDR戦略
全体像
AWSのDR戦略の全体像がこちらの図になります。
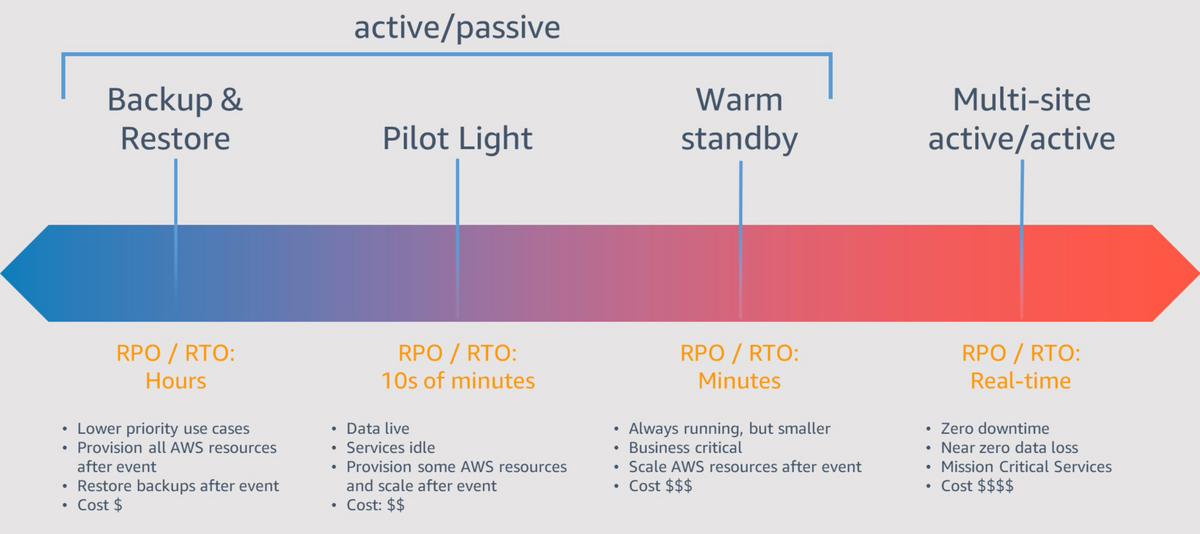
※AWS でのディザスタリカバリ (DR) アーキテクチャ、パートI:クラウドでのリカバリの戦略-図 2.DR 戦略 — RTO/RPOとコストの間のトレードオフ 抜粋
AWSのDR戦略は、アクティブパッシブ/アクティブアクティブの2つのカテゴリーに大別されます。
さらに細分化すると、アクティブパッシブにBackup & Restore・Pilot Light・Warm standbyが、アクティブアクティブにMulti-siteが存在します。
この関係を図にまとめたものが下記になります。
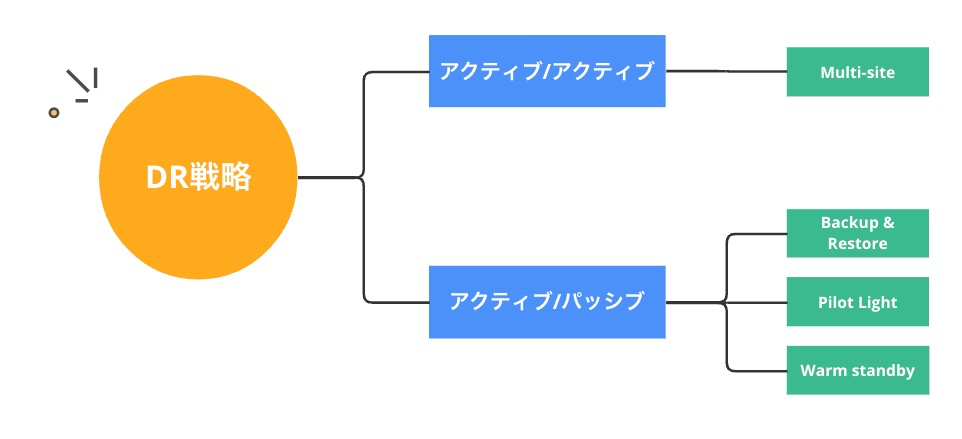
アクティブパッシブ/アクティブアクティブ
アクティブパッシブ
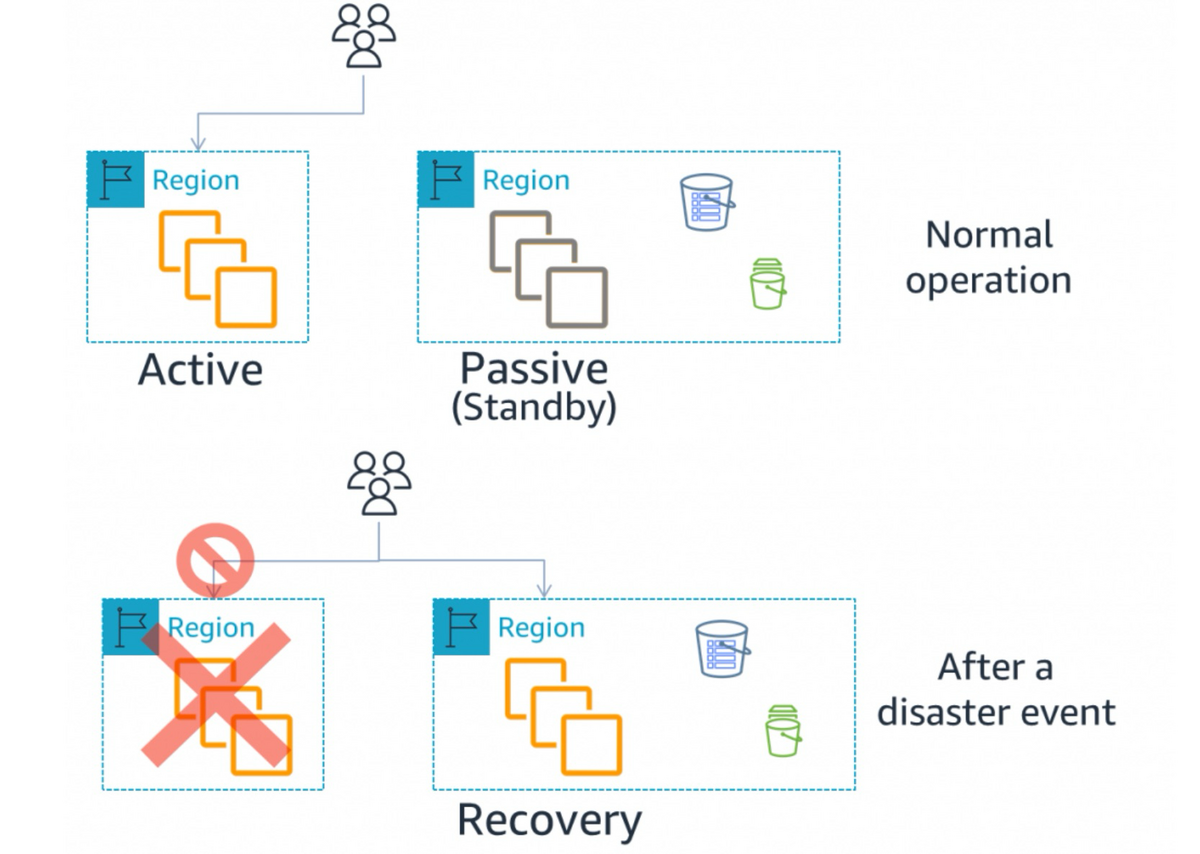
※AWS でのディザスタリカバリ (DR) アーキテクチャ、パートI:クラウドでのリカバリの戦略-図 3.アクティブ/パッシブ DR 抜粋
アクティブパッシブでは、1つのシステム(環境)を稼働させ、もう片方のシステム(環境)を待機状態で用意しておきます。
通常時は稼働しているシステムのみがリクエストを処理します。
稼働しているシステム(環境)で障害が発生した場合、待機状態のシステムを稼働させ、リクエストを処理します。
この「待機状態のシステムを稼働させる時間」がダウンタイムとなります。
このダウンタイムとコストのバランスによって後述するBackup & Restore・Pilot Light・Warm standbyの中からDR戦略を選択します。
アクティブアクティブ
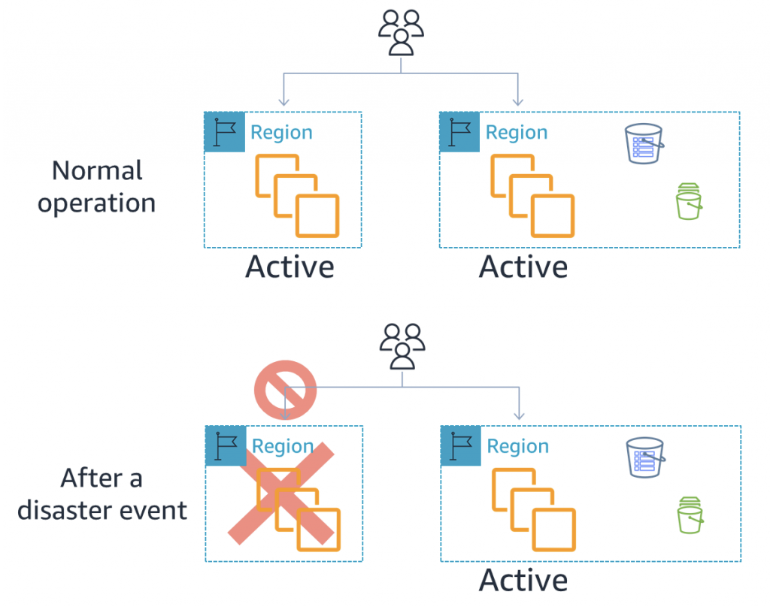
※AWS でのディザスタリカバリ (DR) アーキテクチャ、パートI:クラウドでのリカバリの戦略-図 4.アクティブ/アクティブ DR 抜粋
アクティブアクティブでは、同じ構成のシステム(環境)を複数用意し(冗長化)、それぞれのシステム(環境)でリクエストを処理します。
システムの一つに障害が発生した場合、そのシステムへのリクエストが遮断され、残りの稼働中のシステムが全てのリクエストを処理します。
システムが多重化されているため、信頼性が高く、障害発生時にもサービスの継続が可能です。(ダウンタイムが生じない)
ただし、障害発生時には全体の性能が低下する可能性があります。
比較表
アクティブパッシブ/アクティブアクティブの比較をまとめます。
| 特徴 | Active/Active | Active/Passive (Active/Standby) |
|---|---|---|
| 概要 | AWS内の複数のシステム(環境)が共に稼働し、業務を行っている。 | AWS内で1つのシステム(環境)が稼働し、もう1つは待機状態。 |
| 障害時 | 1つのシステム(環境)がダウンしても、もう1つで業務を継続。ただし、性能は半減する。 | 待機状態のシステム(環境)が稼働を開始する。 |
| メリット | ・ダウンタイムが起きる可能性が低い。 ・障害発生時の影響を最小限に抑えることが可能。 |
・コストが安い。 |
| デメリット | ・障害時に性能が半減する可能性がある。 ・コストが高い |
・ダウンタイムが起きる。 |
AWSの4つのDR戦略
Backup & Restore
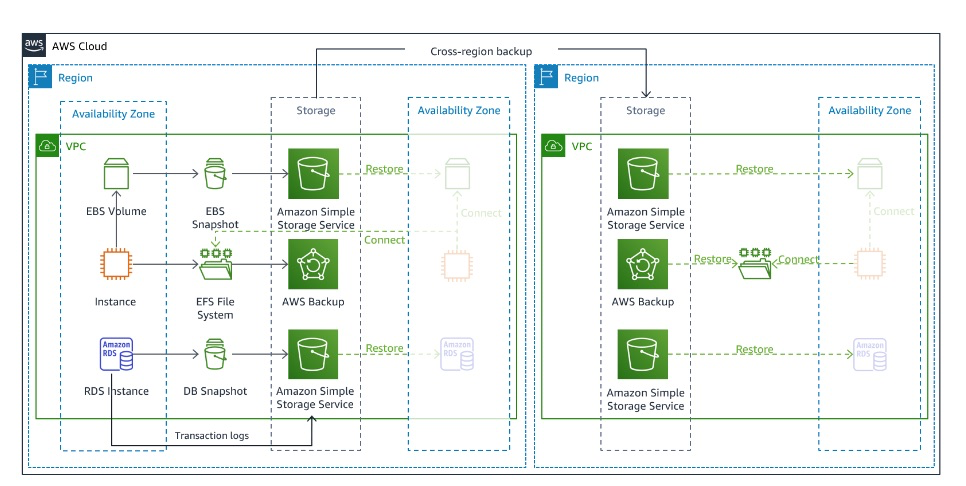
クラウドでの災害復旧オプション_図 7 - バックアップと復元のアーキテクチャ 引用
別のリージョンにバックアップを保存しておくことで、データの損失や破損を回避する方法です、
障害が発生した際には、別リージョンにあるバックアップを用いてサービスを再開します。
この戦略を取る際には、Infrastructure as Code (IaC) の使用をおすすめします。
Backup & Restoreでは、待機しているリージョンにリソースは存在していないためバックアップを用いてインフラストラクチャ、設定、アプリケーションコードを復旧先のリージョンに再デプロイする必要があります。
この際に、復旧先のリージョンに作成するワークロードが大きくなるほど復元することが複雑になり、復旧時間が長くなって RTO を超えるおそれがあるためです。
注意する点としては、IaCのコードを常に最新化することになります。
稼働している環境で行なった変更等をIaCに反映させておかないと、復元時に稼働している環境と別のものが出来上がってしまいます。
そのため、IaCへの変更手順を作っておくことが必要になります。
AWSアーキテクチャの設計としては、障害が起きた際の通知の仕組みを作る、バックアップを定期的または継続的に実行することが求められます。
※ Backup & Restore で利用が勧められるサービス例について、詳しくはこちらをご覧ください。
Pilot Light
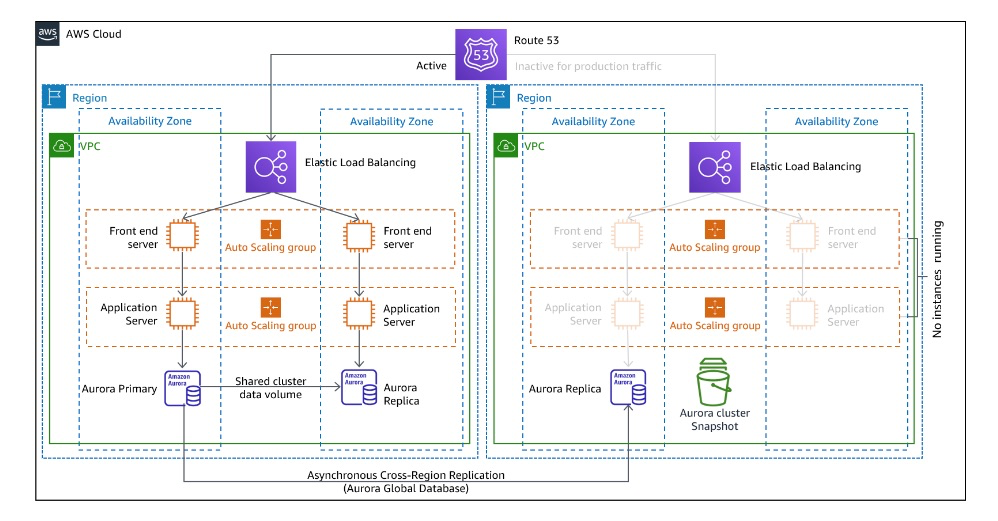
クラウドでの災害復旧オプション_図 6.パイロットライト DR アーキテクチャ 引用
別のリージョンに稼働している環境と同様のリソースを作成し、停止状態にしておく方法です。(停止できないサービス=コアインフラストラクチャ は起動しておく)
障害が発生した際には、別リージョンにあるサービス起動させて再開します。
Backup & Restoreと比べると、コストは上がりますが、RPOが短くなります。
Backup & Restoreと同様IaCは必要になります。
Pilot Lightでは、アクティブなリソースを最小限に抑えて災害対策の継続的なコストを最小化することがポイントになります。
AWSアーキテクチャの設計としては、障害が起きた際の通知の仕組みを作る、バックアップを定期的または継続的に実行すること、コンテナやサーバーレスを採用するなどが挙げられます。
※ Pilot Light で利用が勧められるサービス例について、詳しくはこちらをご覧ください。
Warm standby
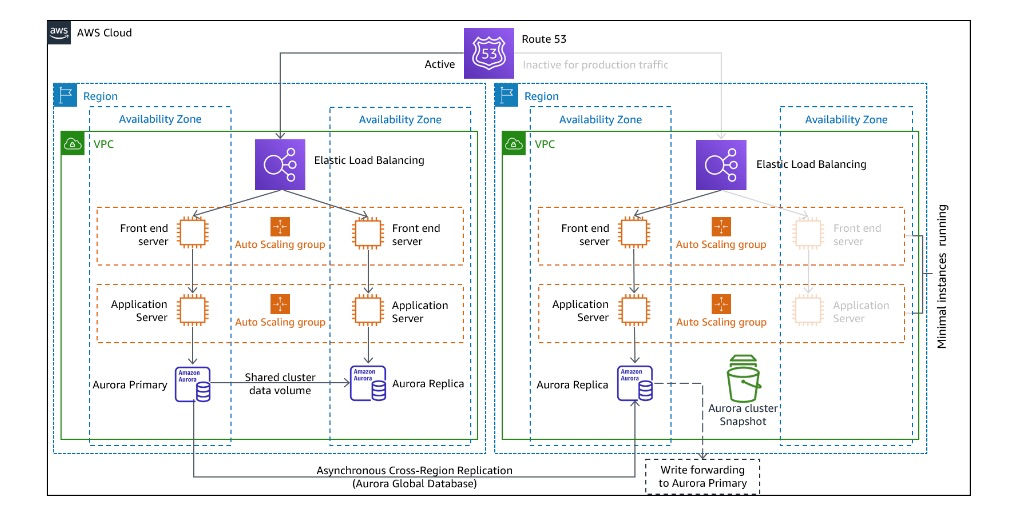
クラウドでの災害復旧オプション_図 7 - ウォームスタンバイDRアーキテクチャ 引用
別のリージョンに稼働している環境と同様のリソースを作成し、縮小状態で起動しておく方法です。
障害が発生した際には、稼働している環境と同等のスペックに戻して復旧します。
Pilot Lightとの違いは、Pilot Lightは最初に追加のアクション(リソースの起動)を実行しないとリクエストを処理できないのに対し、Warm standbyは (縮小した容量レベルで) トラフィックを即座に処理できる点です。
AWSリソースは稼働している状態なので、復旧までの時間はPilot Lightに比べ短くなりますが、コストは上がります。
※ Warm standby で利用が勧められるサービス例について、詳しくはこちらをご覧ください。
Multi-site
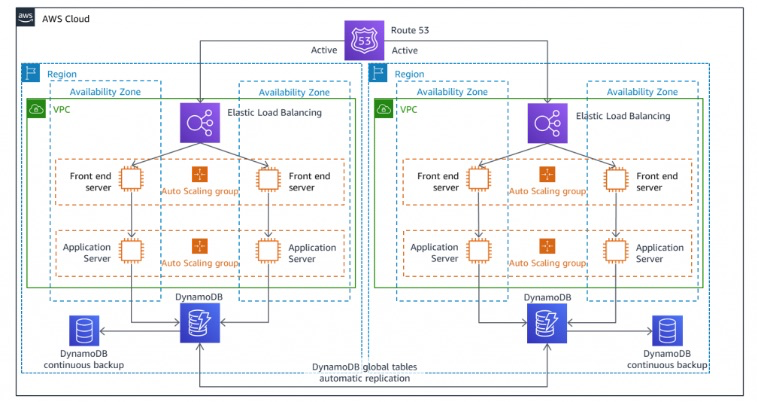
クラウドでの災害復旧オプション_図 8.マルチサイトアクティブ/アクティブ DR アーキテクチャ 引用
今回紹介するAWSの4つのDR戦略のなかで最短のRTO、最小のRPOで障害復旧することができる方法になります。
ただ、もっともコストが高くアーキテクチャがもっとも複雑になる戦略になります。
2つ以上のリージョンで同時に本番環境を稼働させます。
障害が発生時は、障害が起きていないリージョンのみにリクエストが飛ぶようになるのでユーザーから見ると障害があったかどうかわからない状態になります。
つまりダウンタイムが発生しないと想定します。
※ Multi-site で利用が勧められるサービス例について、詳しくはこちらをご覧ください。
AWSの4つのDR戦略のまとめ
今まで解説した内容を元に表にまとめます。
| DR戦略 | 復旧時間 | 復旧点 | コスト | 分類 |
|---|---|---|---|---|
| Backup & Restore | 長い | 一定期間 | 低 | オフサイトバックアップ |
| Pilot Light | 中間 | 短い | 中 | 最小限稼働環境 |
| Warm Standby | 短い | 短い | 高 | 縮小稼働環境 |
| Multi-site | 最短 | 最短 | 最高 | 全リージョン稼働 |
表の内容を簡単に説明すると、次の通りです。
- Backup & Restore: バックアップしておいたデータを使って、障害が起きた後にサービスを元に戻します。コストは低いですが、復旧には時間がかかります。
- Pilot Light: 必要最小限のリソースを別のリージョンで稼働状態に保ち、障害時にはそれをフル稼働させてサービスを復旧します。コストと復旧時間は中間です。
- Warm Standby: リソースを小規模で常に稼働させておき、障害時には迅速にフルスケールで稼働させます。復旧時間は短いですが、コストは高めです。
- Multi-site: 複数のリージョンでリソースを完全稼働させ、障害が起きた場合もダウンタイムなくサービスを継続します。復旧時間は最短ですが、コストは最も高くなります。
AWSでのDR戦略の決定方針
AWSが提供しているホワイトペーパーには下記のように記載があります。
RTO基準
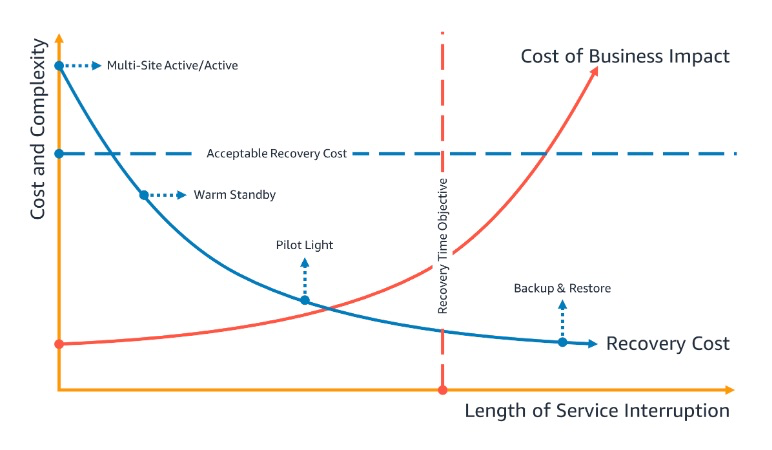
ビジネス継続性計画 (BCP) 図 4 - 目標復旧時間 引用
この図の縦軸には「コストと複雑さ」が、横軸には「サービス中断の長さ」が示されています。
赤い線はビジネスインパクトのコスト、つまりサービスが中断している間に企業が負う損失の大きさを表しており、中断時間が長くなるにつれてこのコストは増加しています。
青い線は復旧コストを示しており、これは復旧に必要な費用と時間のことです。
短時間で復旧するための戦略ではコストが高くなりますが、時間が経過するにつれて復旧コストは下がっていきます。
図には、4つの戦略が下記のように示されています。
- Multi-site:サービス中断の時間をほぼゼロにすることができます。
- Warm Standby:比較的短い時間での復旧が可能です。
- Pilot Light:中規模の時間が必要です。
- バックアップ&リストア:復旧にはもっとも長い時間がかかります。
RPO基準
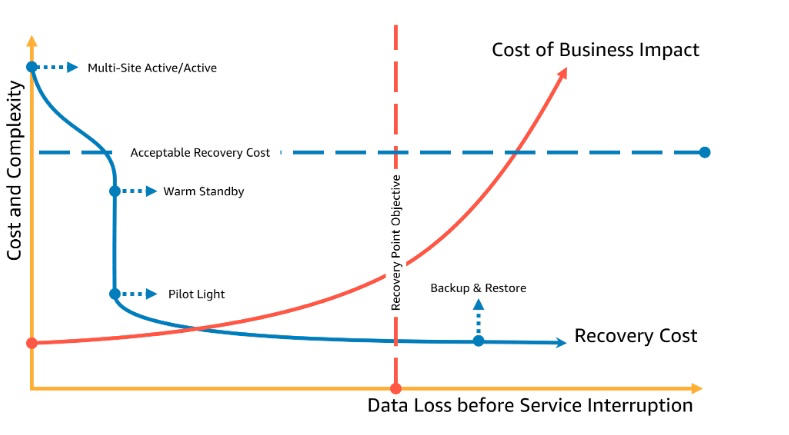
ビジネス継続性計画 (BCP) 図 5 - 目標復旧時点 引用
RTO基準と同様にRPO基準も見ていくとまた、図には4つの戦略が下記のように示されています。
- Multi-site:非常に高いコストと複雑さを伴いますが、サービス中断前のデータ損失をほとんどゼロに近づけることができます。
- Warm Standby:より低いコストで、ある程度のデータ損失は許容されますが、比較的迅速に復旧できる戦略です。
- Pilot Light:Backup & Restoreよりはデータ損失が少なくて済みます。
- Backup & Restore:最も基本的で低コストな戦略ですが、復旧までの時間とデータ損失が最も大きくなります。
個人的解釈
個人的な解釈になりますが、RPOとRTOを元に4つのDR戦略に分けると下記のようになる想定です。(あくまで個人的な解釈になるためご注意ください)
- Backup & Restore: 数十分〜数時間のRTO、バックアップ頻度やレプリケーション頻度・時間によりRPOは左右される
- Pilot Light: 数十分のRTO、バックアップ頻度やレプリケーション頻度・時間によりRPOは左右される
- Warm Standby: 数秒〜数分のRTO、ほぼ最小のRPO
- Multi-site: 最短のRTO・最小のRPO
まとめ
長くなってしまいましたが、AWS上でのDRについてまとめました。
DRを考える上でアーキテクチャの設計が非常に重要になることがわかりました。
本記事が誰かの助けになれば幸いです。
日高 僚太(執筆記事の一覧)
2024 Japan AWS Jr. Champions / 2024 Japan AWS All Certifications Engineers / Japan AWS Jr. Champions of the Year 2024
EC部クラウドコンサルティング1課所属。2022年IT未経験でSWXへ新卒入社。
記事に関するお問い合わせや修正依頼⇒ hidaka@serverworks.co.jp