

こんにちは、技術2課の加藤ゆです。
秋ですね!梨が食べたいです。ラ・フランスが好きです。
さて今回EC2のステータスチェックの監視の検証をしてみたので書いてみました!
やりたいこと
「StatusCheckFailed_SystemのAutoRecovery設定をしたい」
EC2インスタンスがAWS側の問題で起動しなくなった時に、自動で回復してくれるCloudWatchアラームを設定したい!という事です。
EC2ステータスチェックとは?
インスタンスのステータスチェック - Amazon Elastic Compute Cloud
ステータスチェックには、システムステータスチェックとインスタンスステータスチェックの 2 種類があります
- システムステータスのチェック
- インスタンスステータスのチェック
それぞれ以下に記します。
システムステータスのチェック
システムステータスチェックは、インスタンスが実行されている AWS システムをモニタリングします。これらのチェックでは、修復には AWS の関与が必要なインスタンスの根本的な問題が検出されます。
簡単にいうと、AWS側の基盤に問題がある(ユーザでは解決できない)場合に検出されます。
システムステータスチェックの失敗の原因となる問題の例を次に示します。
- ネットワーク接続の喪失
- システム電源の喪失
- 物理ホストのソフトウェアの問題
- ネットワーク到達可能性に影響する、物理ホスト上のハードウェアの問題
いずれも見た通りAWSのマネージド部分(物理層)起因のものですね、私たちユーザではどうしようもありません。
インスタンスステータスのチェック
個々のインスタンスのソフトウェアとネットワークの設定をモニタリングします。Amazon EC2 は、ネットワークインターフェイス (NIC) にアドレス解決プロトコル (ARP) リクエストを送信することでインスタンスのヘルスをチェックします。これらのチェックでは、ユーザーが関与して修復する必要のある問題が検出されます。
簡単にいうと、ユーザ自身の設定や操作に問題がある(ユーザ自身が解決できる)場合に検出されます。
インスタンスステータスチェックの失敗の原因となる問題の例を次に示します。
- 失敗したシステムステータスチェック
- 正しくないネットワークまたは起動設定
- メモリの枯渇
- 破損したファイルシステム
- インスタンスの再起動、または Windows のインスタンスストアバックトインスタンスがバンドルされている間は、インスタンスが再度使用可能になるまで、ステータスチェックで失敗がレポートされます。
たとえば、インスタンスを再起動する、インスタンス設定を変更するなどによってユーザが解決することが出来る問題が検出されます。
CloudWatchアラームの設定
インスタンスの利用可能な CloudWatch メトリクスのリスト表示 - Amazon Elastic Compute Cloud
最近 1 分間にインスタンスが システムステータスチェックに成功したかどうかを報告します。
このメトリクスは 0 (合格) または 1 (失敗) となります。
StatusCheckFailed_Instanceメトリクス・StatusCheckFailed_Systemメトリクスが「1」となる時、ALARM状態へ遷移してもらいたいので、以下の様に設定しました。
- 統計:最大
- 期間:1分
- しきい値の種類:静的
- アラーム条件:以上
- しきい値:1
- アラームを実行するデータポイント:2/2
- 欠落データの処理:欠落データを見つかりませんとして処理
再起動と復旧アクション間で不具合が発生するのを回避するには、再起動アラームと復旧アラームを同じ評価期間に設定するのを避けます。復旧アラームを各 1 分間の 2 回の評価期間に設定することをお勧めします。
docs.aws.amazon.comインスタンスを停止、終了、再起動、または復旧するアラームを作成する - Amazon Elastic Compute Cloud
データポイントを1分の期間で作成し、上記ドキュメント記載の通り、評価期間2回中 2 回メトリクスがしきい値「1」以上になればALARM状態へ更新される設定とします。
AutoRecoveryとは?
インスタンスのステータスチェックのうち、システムステータスが失敗した場合に、自動復旧をする機能です。
インスタンスの復旧 - Amazon Elastic Compute Cloud
マネジメントコンソールで「AutoRecovery」をポチっと出来る訳では無く、CloudWatchアラームのアクションで設定します。
(※マネジメントコンソール上に「AutoRecovery」という設定は出てこない(存在しない)のでご注意ください)
AutoRecoveryの設定をしておくと、AWS基盤側の問題でEC2が起動できなくなった場合に、CloudWatchアラームで検知して、アクションとして自動で再起動をします。
Create alarms to stop, terminate, reboot, or recover an EC2 instance - Amazon CloudWatch
Amazon EC2インスタンスを監視し、基になるハードウェア障害または修復にAWSの関与が必要な問題が原因でインスタンスが障害になった場合に、インスタンスを自動的に回復するAmazonCloudWatchアラームを作成できます。 終了したインスタンスは回復できません。復元されたインスタンスは、インスタンスID、プライベートIPアドレス、Elastic IPアドレス、およびすべてのインスタンスメタデータを含め、元のインスタンスと同じです。
注意ポイント
CloudWatch では、復旧アクションをサポートしていないインスタンスにあるアラームに、復旧アクションを追加することはできません。
EC2アクション設定で「このインスタンスを復旧」を選択できる条件を満たす必要があります。
大きく3つの条件があります。
- 指定のインスタンスタイプであること
- 専有型ホストを利用していないこと
- インスタンスストアを利用していないこと
復旧アクションによって再起動が自動で実行されます。したがって、物理ホスト層に影響するインスタンスの使い方をしていると、復旧アクションは選べませんよ、という事ですね
復旧アクションは、StatusCheckFailed_System でのみ使用できます。StatusCheckFailed_Instance では使用できません。
CloudWatchメトリクスで取得可能なAWS/EC2 名前空間には、デフォルトで以下の3つのステータスチェックメトリクスが含まれています
- StatusCheckFailed
- StatusCheckFailed_Instance
- StatusCheckFailed_System
(各メトリクスの取得する情報については、ステータスチェックメトリクスをご覧ください)
上記メトリクスのうち、「StatusCheckFailed_System」メトリクスのみ復旧アクションを設定出来るという事です。
「StatusCheckFailed_System」のメトリクスがアラーム状態へ更新された際に復旧アクションが開始されます。
設定方法
インスタンスを停止、終了、再起動、または復旧するアラームを作成する - Amazon Elastic Compute Cloud
CloudWatchアラームのEC2アクションとして設定します。
今回はアラームを作成済みの場合の設定方法を以下に記します。 アラームを新規作成する場合とGUIは同じです。
対象のアラームを選択し「編集」を押下
 「アクション」から「編集」を押下
「アクション」から「編集」を押下

「メトリクスと条件の指定」は希望する条件でALARMとなるよう設定します。
アクションの設定
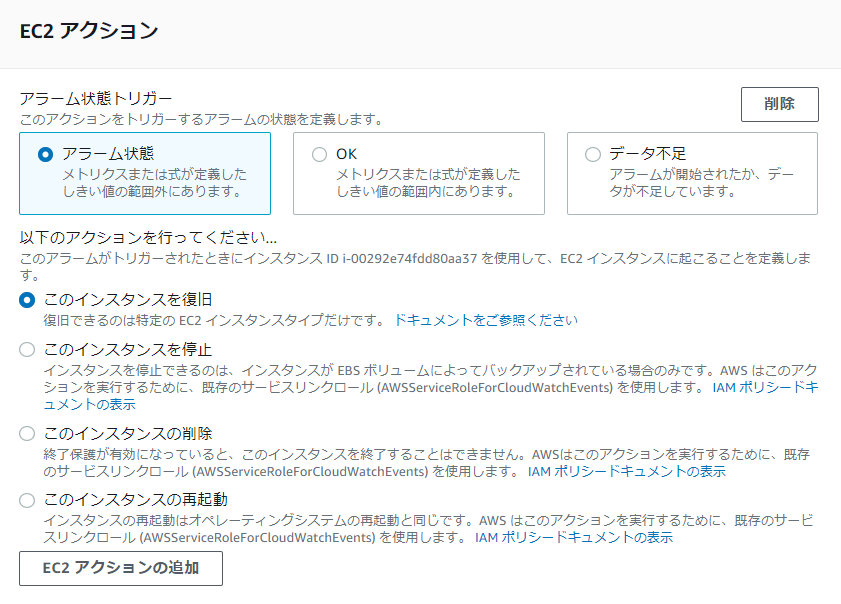
注意ポイント で述べた条件をクリアしている場合は、EC2アクションで「このインスタンスを復旧」を設定することが出来ます。
(※条件をクリアしない場合はグレーアウトされ、選択できません)
検証してみよう
結論から述べると、ユーザ側の原因による検証(インスタンスステータスのチェックを検出させる)は可能ですが、AWS管理側の原因による検証(システムステータスのチェック)はできません。悪しからず。
システムステータスの問題発生時に本当に回復されるよね?という検証が出来ないのが残念ポイントですね…
StatusCheckFailed_Systemメトリクス
Amazon CloudWatch でのアラームの使用 - Amazon CloudWatch
set-alarm-state — AWS CLI 1.20.45 Command Reference
システムステータスの問題発生を促すことは出来ませんが、アラームの動作をテストするためにAWS CLI の set-alarm-state コマンドを使用して、アラームの状態を一時的に設定することが出来ます。
コマンドで実行
[cloudshell-user@ip-10-0-143-97 ~]$ [cloudshell-user@ip-10-0-143-97 ~]$ aws cloudwatch set-alarm-state --alarm-name "xxxxxx-status-check-failed_system" --state-value ALARM --state-reason "test" [cloudshell-user@ip-10-0-143-97 ~]$
set-alarm-stateコマンドを使用して、「xxxxxx-status-check-failed_system」という名前のAmazon CloudWatchアラームの状態を一時的に変更し、テスト目的でALARM状態に設定しました。
結果

ALARM状態に更新し、EC2アクションが実行されている事を確認
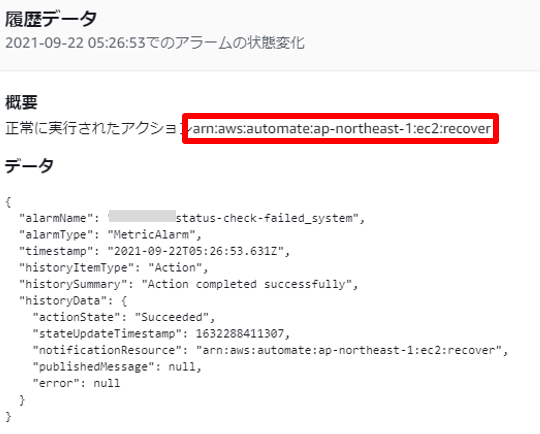
EC2アクション実行時の履歴データです。
一時的にALARM状態としたので、その後OK状態へ更新されています。
StatusCheckFailed_Instanceメトリクス
EC2インスタンスのNICを無効化することで、インスタンスとの疎通が出来ないようにしてみましょう。
コマンドで実行
NICの無効化
NICの無効化/有効化、再起動を行うには? ifdown/ifupコマンド:ネットワーク管理の基本Tips - @IT
$ ifdown eth0
結果
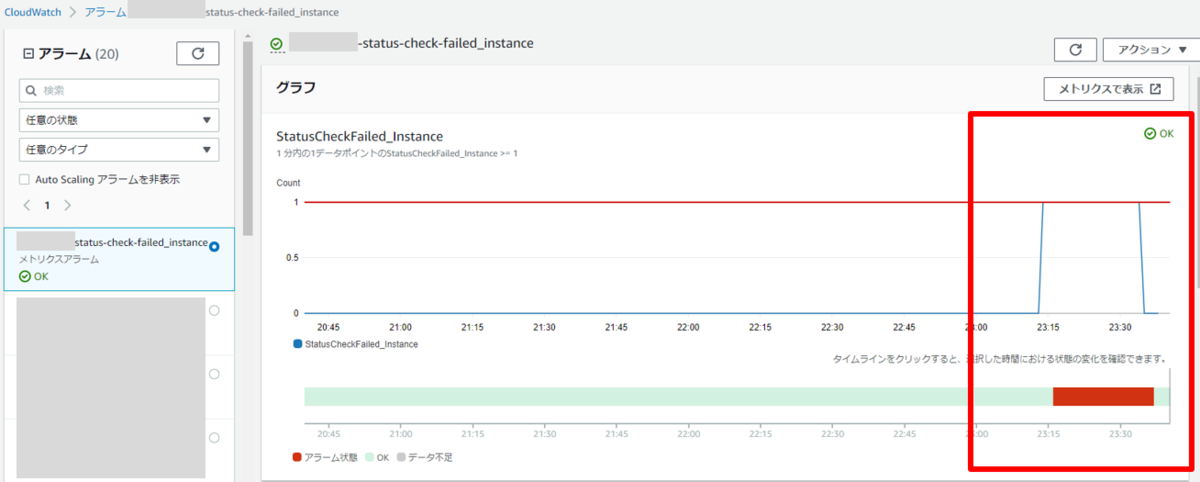
NICを無効にすることで、インスタンスと疎通不可となりインスタンスステータスが問題ありとして検知されます。

NICを新たに追加でアタッチすることで、OK状態へ戻ります。

ステータスチェック2/2に合格

CloudWatchアラームもALARM状態からOK状態へ更新されました。
所感
EC2インスタンスのステータスチェックを監視して、ALARM状態へ更新・OK状態へ更新されたときにSNSで通知する設定もやったので、次に書きます!
EC2は利用機会が多いサービスだと思うので、運用時に利用して頂けると良いなと思います