

こんにちは、近藤(りょう)です!
社内で複数の近藤さんがいますので識別するために()付きにしています。
ソリューションアーキテクトでも問題としてピックアップされていますね。
EMRについていくつ調べましたので概要と他社SaaS比較についてご紹介していきます~!
EMRとは?
Hadoop, Spark, Hive, Presto などの オープンソースフレームワークを使⽤した ペタバイトスケールのビッグデータ分析が可能なAWSサービス です。
データ処理以外にも相互分析、機械学習を行なう業界をリードするクラウドビッグデータソリューションとなります。
参考
EMRで利用可能なオープンソース(一部)
Hadoop
- 分散ファイルシステムであるHadoop Distributed File System (HDFS) と、分散処理を行うためのMapReduceフレームワーク(分散処理モデル)
- MapReduceは比較的低レベルなプログラミングモデルであるため、後続の処理フレームワークとしてApache Sparkを利用することが多い
Spark
- メモリ内処理を活用することで高速なデータ処理を並列実行可能
- Scala、Java、Python、Rなどの複数のプログラミング言語をサポート
Hive
- SQLに似た言語であるHiveQL(HQL)を使用し、データを問い合わせるための高水準なクエリインターフェースを提供
Presto
- Facebook 開発者が作成したオープンソースの分散 SQL クエリエンジンで、大量のデータに対してインタラクティブな分析を実行
そのほか
- こちらを参照のこと ▶ Configure applications - Amazon EMR
EMRはどんなことができるのか?
ビックデータ処理(ペタバイトスケールの分析)
EMRを使用して、ビッグデータセットに対する複雑な分析や処理を行うことができます。SQLクエリ、機械学習、統計分析、グラフ処理や構造データ、非構造データなど多岐にわたるビッグデータワークロードに対応しています。
ストリーム処理
Amazon Kinesis、Apache KafkaなどからApache Spark StreamingやApache Flinkを使用することで、ストリームデータのリアルタイム処理や処理結果を処理することができます。
機械学習
EMRは機械学習フレームワークであるApache Spark Mllibを使用して、ビッグデータセットを用いた機械学習モデルの構築やトレーニングができます。
参考 資料たち
Hadoop ▶ Amazon EMR の Apache Hadoop | AWS
Spark ▶ Amazon EMR での Apache Spark | AWS
Presto ▶ Amazon EMR での Presto | AWS
他アプリケーション概要 ▶ Configure applications - Amazon EMR
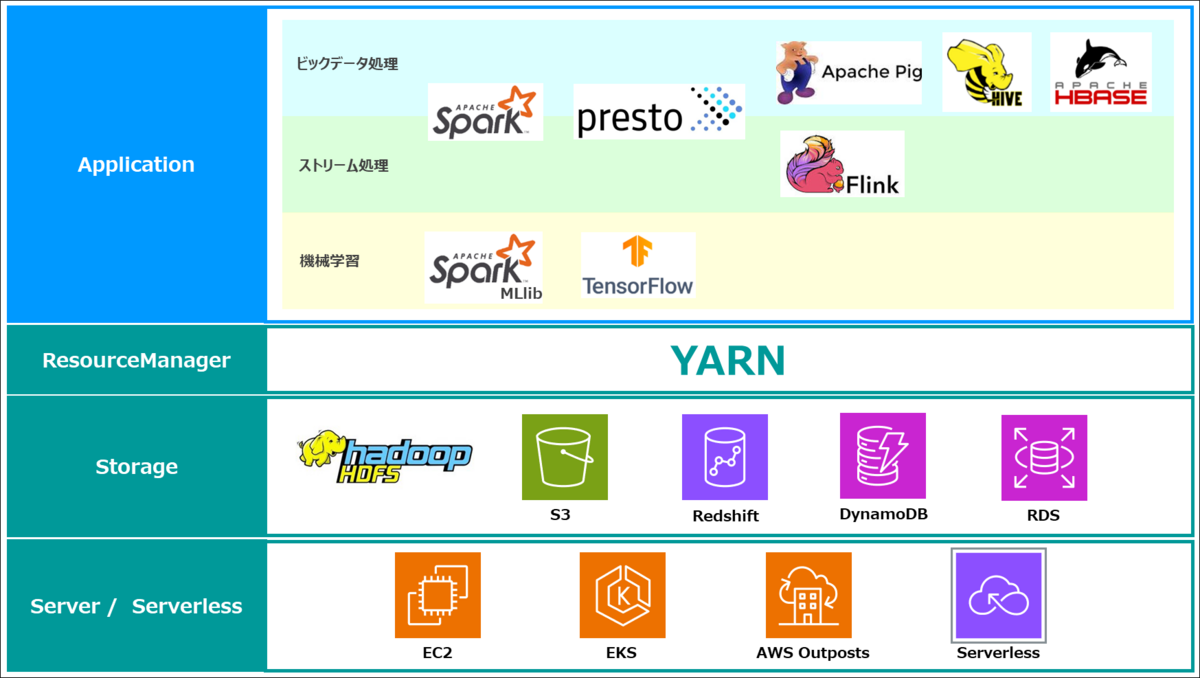
EMRアーキテクチャ
EC2やEKSを使って処理をするサーバを起動でき、EMR Serverlessもあり使ったリソース分だけ料金を支払うことも可能です。
処理するデータのIN/OUTのストレージもHadoop HDFSの他にS3やRedshift、DynamoDB、RDSなどが利用できます。
分散アプリケーションのリソースはYARNが制御を行います。
アプリケーションとしては、ビッグデータ処理やストリーム処理には、Spark StreamingやPrestoを使い、機械学習の場合は、Spark MLlibやTensorFlowになります。
最終的には開発/利用したいアプリケーションを要件に応じて選定いただければと思います。
アーキテクチャの図があまりなかったのでイメージとしてはこのような感じです。
Amazon EMR の特徴 ▶ 特徴 - Amazon EMR | AWS
Amazon EMR アーキテクチャの概要 ▶ Amazon EMR アーキテクチャの概要 - Amazon EMR
他社SaaS比較
大量データ分析基盤観点の他社の比較を記載してみました。
個人的見解を含むので参考程度としてご確認ください。
※データセキュリティ、ビッグデータ分析、ストリーム処理、機械学習はどのSaaSサービスも利用可能でした。
データモデル
- AWS EMR:分散データ処理基盤(Hadoop、Spark)
- Google BigQuery:サーバーレス、分散データストア
- Azure Databricks:データレイクとデータウェアハウス 一体型
- Snowflake:メタデータサーバーとストレージ層 分離
データ処理
- AWS EMR:Hadoop MapReduce、Spark など ※フレームワークによる
- Google BigQuery:SQLベース
- Azure Databricks:SQLベースおよびSpark
- Snowflake:SQLベース
分散処理フレームワーク
- AWS EMR:Hadoop、Spark、その他のフレームワーク
- Google BigQuery:- (独自)
- Azure Databricks:Spark
- Snowflake:- (独自)
コスト
- AWS EMR:
- サーバの場合:
インスタンス単位の料金、ストレージ料金 - サーバレスの場合:
クエリ料金、ストレージ料金
- サーバの場合:
- Google BigQuery:クエリ料金、ストレージ料金
- Azure Databricks:Azureリソース利用料、Databricksソフトウェア利用料
- Snowflake:コンピューティング料金、ストレージコスト、クエリ料金
- AWS EMR:
移植性
- AWS EMR:○ ※OSSを採用しているため
- Google BigQuery:×
- Azure Databricks:△ ※Sparkの場合
- Snowflake:×
AWS EMR マニュアル ▶ Amazon EMR とは - Amazon EMR
BigQuery マニュアル ▶ BigQuery の概要 | Google Cloud
Azure Databricks マニュアル ▶ Azure Databricks のドキュメント | Microsoft Learn
Snowflake マニュアル ▶ ガイド - Snowflakeドキュメント
AWS EMR の料金 ▶ 料金 - Amazon EMR | AWS BigQuery の料金 ▶ 料金 | BigQuery: クラウド データ ウェアハウス | Google Cloud Azure Databricks の料金 ▶ Azure Databricks の価格 | Microsoft Azure Snowflake の料金 ▶ 総コストについて | Snowflake Documentation
その他
Amazon EMR SLA
Amazon EMRのSLAは、99.9%以上となっています。
EC2 SLAは99.99%などなので他のサービスと比べるとSLAは劣りますね。
Amazon EMR SLA
Amazon EMR Service Level Agreement
EC2 SLA
https://d1.awsstatic.com/legal/AmazonComputeServiceLevelAgreement/Amazon_Compute_Service_Level_Agreement_Japanese_2022-05-25.pdf
ブラックベルト:Amazon EMR の基礎
ブラックベルトのAmazon EMR の基礎はこちらをご参照ください。
Amazon EMR の基礎
https://pages.awscloud.com/rs/112-TZM-766/images/AWS-Black-Belt_2023_Amazon-EMR_0929_v1.pdf
まとめ
いかがでしたでしょうか?
少しでもAmazonEMRについて概要をご理解いただけたら嬉しいです。
データセキュリティ、ビッグデータ分析、ストリーム処理、機械学習は、どのSaaSサービスでも利用できるので今後の維持運用を踏まえた保守(アプリケーション改修含む)やコストと性能(検証しないと実値は分かりませんが)を比較したうえで選定していただければ幸いです。
近藤 諒都
(記事一覧)カスタマーサクセス部CS5課
夜行性ではありません。朝活派です。
趣味:お酒、旅行、バスケ、掃除、家庭用パン作り(ピザも)など
2025 Japan AWS All Certifications Engineers