

こんにちは、技術2課加藤ゆです
QuickSightデビューはじめの一歩、開始手順とデータのインポート方法についてご紹介します。
「とにかくQuickSight操作感を試してみたい!」という方向けの開始手順になります。
データのインポート方法は、.csvファイルを直接インポートしますので、QuickSightを本番実装する場合は、データソースとインポート方法の検討が必要です。
初期セットアップ
Amazon QuickSight にサインアップし、利用開始できるまでを説明します。
1.セットアップの開始
AWS マネジメントコンソールにログインし、リージョンをご利用するリージョンに設定します。
(キャプチャは東京)
サービス一覧から QuickSight を選択し、初めて利用する場合は以下の画面が表示されますので、
「Sign up for QuickSight」をクリック。

2.エディションの選択
エディション選択の画面に遷移されます。
初期状態では Enterprise Edition (エンタープライズ版)が選択されていますが、本手順ではStandard Edition(スタンダード版)でご案内します。
※後から Enterprise Edition にアップグレード可能です。
右上の「Standard」を押下

エンタープライズ版とスタンダード版の違いは?
ユーザーあたりの料金や SPICE 容量の料金は、スタンダード版のほうが安く利用が可能です。
加えて、利用可能な拡張機能数が大きく違い、エンタープライズ版の方が多くの拡張機能をご利用いただけます。
利用目的によっては、スタンダード版では期待する機能が利用できない場合がありますので、事前にご確認ください。
※下表は一部抜粋。公式ドキュメントをご覧ください。
| 項目 (※一部抜粋) |
エンタープライズ版 | スタンダード版 |
|---|---|---|
| 無料トライアル作成者数 (30 日間) | 4 | 4 |
| SPICE 搭載容量 | 10 GB/ユーザー | 10 GB/ユーザー |
| 通常利用時のコスト (月当たりのSPICE料金) |
0.38 USD/GB | 0.25 USD/GB |
| エディションの変更 | ✖ | 〇 |
| SAML または OpenID Connect によるシングルサインオンSAML または OpenID Connect によるシングルサインオン | 〇 | 〇 |
| 閲覧者の追加 | 〇 | ✖ |
| メールレポート | 〇 | ✖ |
| 保管中のデータの暗号化 | 〇 | ✖ |
| Active Directory への接続 | 〇 | ✖ |
| プライベート VPC およびオンプレミスのデータへの安全なアクセス | 〇 | ✖ |
Amazon QuickSight エディションによる相違点
料金 - Amazon QuickSight | AWS
Amazon QuickSight では Enterprise Edition (エンタープライズ版) を選択することをおすすめします。 Author (作成者) 権限のユーザーあたりの料金や SPICE 容量の料金は Standard Edition の方が安くなりますが、Standard Edition には Reader (閲覧者) 権限の概念がないため、閲覧者が多い一般的なユースケースでは Enterprise Edition の方が安くなることがあります。 また、MLインサイトの予測や異常検知、行レベルのセキュリティ、メールレポートなどの機能は Enterprise Edition でのみ利用可能です。
選択に当たっての注意点
エンタープライズ版からスタンダード版へのダウングレードは出来ません。
一方、スタンダード版からエンタープライズ版へのアップグレードは可能です。利用料金の関係で、まずはスモールスタート!という方はスタンダード版からの開始が良いでしょう。
3.QuickSight アカウントの設定

Authention method(認証方法)
認証方法を選択します。
ここでは、IAMフェデレーションIDとQuickSight管理ユーザーを使用できるよう、デフォルトのまま設定します。
QuickSight Region(QuickSight リージョン)
Author(製作者) ユーザに付属する SPICE 容量がどのリージョンに確保されるかを指定するものです。
後に変更不可の設定となりますので、利用されるリージョンをご指定ください。
(キャプチャは東京)
QuickSight account name (QuickSight アカウント名)
QuickSight の一意のアカウント名を指定ください。
(半角のアファベット、数字、ハイフンのみ利用可能で、他の人と被らないユニークなもの)
Notification email address(通知の E メールアドレス)
サービスおよび使用状況の通知を受信します。
ご自身のメールアドレスを入れてください。
QuickSightのAWSサービスへのアクセス
AmazonQuickSightと連携するようにAWSリソースを設定します。
今回は直接データをインポートしますので、IAMにチャックが入っていれば問題ないです。
4.登録完了
「完了」 を押下
少し待つと「Amazon QuickSighに移動する」のボタンが表示されます

CSV ファイルをアップロードし、データセットを作成する
CSV ファイルを SPICE 領域にアップロードします。
1.CSV ファイルを準備
本手順では、ハンズオン用に用意した、2つの関連するファイルを利用し、データを結合させていきます。
お手持ちのご利用になりたいcsvファイルをご準備ください。
2.CSV フ ァ イ ル を アッ プ ロ ードす る
画面左にある「データセット」を押下し、右上の「新しいデータセット」を押下
「ファイルのアップロード」を押下

ファイル選択のダイアログで、ご準備いただいた 一つ目の.csvファイル を選択してアップロードします。
確認画面で「設定の編集とデータの準備」を選択

「準備(PREPARE)」の 画面に遷移します
3.データセットを準備する
分析の準備として、データを利用しやすい形にします。
(例:フィールド(列)の名前を変える、不要なフィールドを見えなくする、事前に複数のデータソースを結合する)
本手順では、別データを追加して結合する作業を実施していきます。
別データの追加
画面上方の「データを追加」をクリックし、ダイアログから「ファイルのアップロード」を選択
 ファイル選択のダイアログで、ご準備いただいた 二つ目の.csvファイル を選択して、アップロードします。
ファイル選択のダイアログで、ご準備いただいた 二つ目の.csvファイル を選択して、アップロードします。

「次へ」を押下

データを結合したい
インポートした2つのファイルをデータを結合し、複数のテーブルを1つにまとめてみましょう。
2つの赤い円のようなアイコン(上部)を押下
画面下に出る結合設定で結合する列を指定します。

今回は、各ファイルの「Region」列を結合します。
両方とも 「Region」 を指定し、結合タイプは 「Inner」 に変更して、「適用」を押下。

結合タイプとは?
1. Inner (内部結合):2 つのテーブル間で一致するデータのみを表示
2. Left (左の外部結合):左のテーブルのすべてのデータと、右のテーブルの一致する行のみを表示
3. Right (右の外部結合):右のテーブルのすべてのデータと、左のテーブルの一致する行のみを表示
4. Full (完全外部結合):一致するデータに加えて、一致しない両方のテーブルのデータを表示
参考: 結合の種類
画面左側のフィールドに、2つめのファイル にあった Account Rep と Region[Assign.csv(2つめの.csvファイル)]が追加されていることが分かります。

Region 列は 1つ目のファイルにも存在し、2つある必要はないため、削除します。
Region[Assign.csv]の横にある「…」ボタンから、「フィールドを除外」を選択

フィールドの型を修正したい
Patient-ID フィールドが自動的に「整数(Int)型」に認識されていますが、正しくは「文字列」なので、文字列型に変更します。
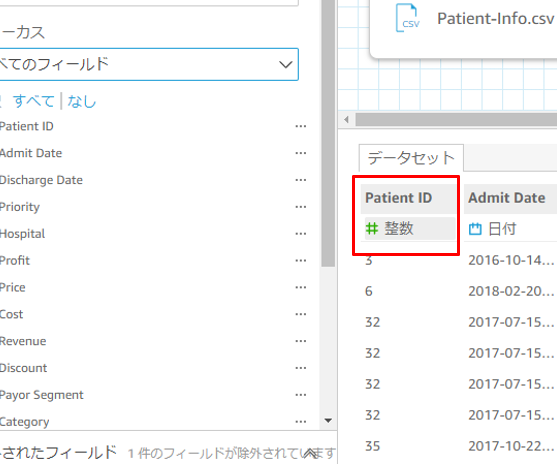 右側の Patient ID フィールドの下にある「整数」と書いた部分を押下し、文字列を選択
右側の Patient ID フィールドの下にある「整数」と書いた部分を押下し、文字列を選択

変更後

データセットの名前を変更したい
画面最上部にある枠に任意の文字を入力することで、データセットの名前をつけることが可能です。

分析画面に移動する
「公開して視覚化」を押下すると、SPICE にデータが取り込まれます。

右上の表示が「インポートの完了」となったらデータの取り込み完了です。

分析作成画面
フィールドを選択し、必要なビジュアルタイプ(グラフの種類)を押下
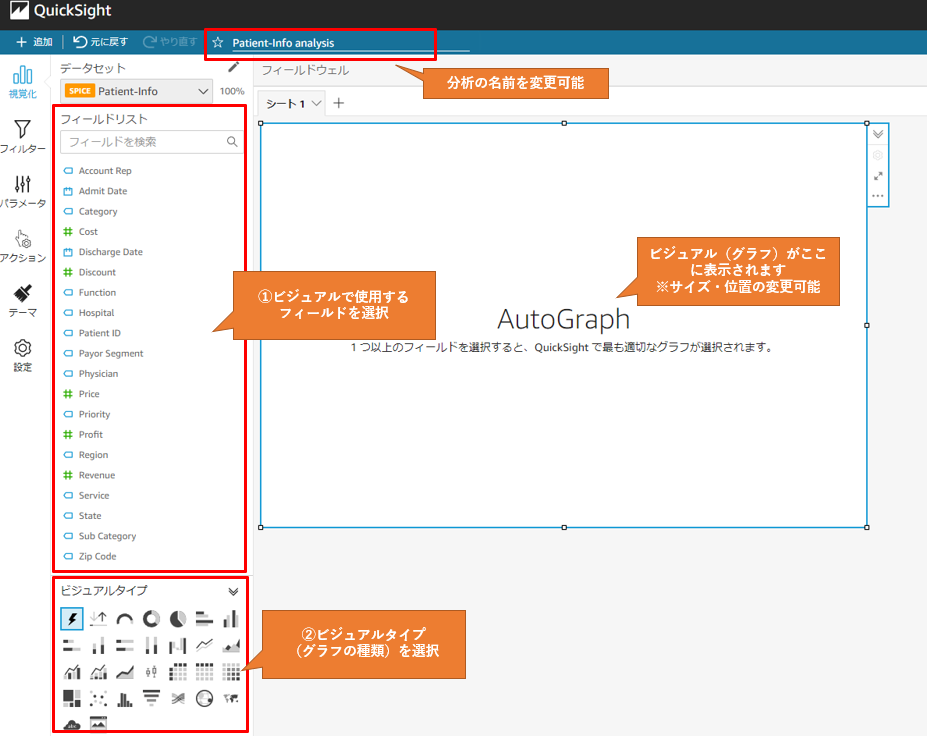
操作は自動的にセーブされます。 ビジュアルは左上の「+」を押すことで複数追加可能、サイズや位置を変更することが可能です。
以降、必要に応じてデータの可視化作業が可能です。