

こんにちは、羽柴です。
今週はre:inventに参加してまして、その中の1つのトラックであるDelivering Results with Amazon Redshift, One Petabyte at a Timeをレポートしたいと思います。
re:inventはセッションにもよりますが日本語トラックも用意されています。やはり日本語は何も考えなくても頭に入ってくるのでいいすね。とはいえ普段あまりRedshiftを触らない私にとってはなかなか濃い内容で楽しめました。
今週はre:inventに参加してまして、その中の1つのトラックであるDelivering Results with Amazon Redshift, One Petabyte at a Timeをレポートしたいと思います。
re:inventはセッションにもよりますが日本語トラックも用意されています。やはり日本語は何も考えなくても頭に入ってくるのでいいすね。とはいえ普段あまりRedshiftを触らない私にとってはなかなか濃い内容で楽しめました。
Amazon Data Warehouse Overview
Amazon Data Warehouse は Amazon の全てのデータを管理し、それを元に事業を行っている
ミッションはそのデータを使って最適な価値をお客様に提供することである
Web Logs on Amazon Redshift
・Web Logsはアマゾンのキーとなるものでオンラインでのユーザーの活動状況などのログのこと
・ユーザーの行動だけでなく、その後のバックエンドで行われているログも併せて取得している
→いわゆるサプライチェーンマネジメントってやつですよね、たぶん
・前年対比67%で増加している
→いわゆるサプライチェーンマネジメントってやつですよね、たぶん
・前年対比67%で増加している
Web Logsのゴール
・デイリーデータを1時間以内に集計する
・1日で1ヶ月分のの正確なデータを集計する
・1日で1ヶ月分のの正確なデータを集計する
・自動的に古いデータをドロップしデータを最適化する
・ゼロインパクトメンテナンスを実現する
Web Logs の現在の構成
・Oracle RAC
・EMR
・EMR
ADW Web Log/ Amazon Redshift
・101-node 8XL クラスター
・1PBの容量
・3 clusters - 2つは本番、1つはテストおよび開発
・1PBの容量
・3 clusters - 2つは本番、1つはテストおよび開発
Design considerations
・ラージストテーブルが400TBある
・Redshiftへのチャレンジ項目
・削除に負荷がかかる
・削除に負荷がかかる
データ挿入でソートしないため、数千のクエリが毎日遅くなる
→バキュームが遅い、物理パーテションが存在しない
・同じテーブルに対してパラレルなロードが許されない
・15の同時クエリ
・同じテーブルに対してパラレルなロードが許されない
・15の同時クエリ
アーキテクチャレベルでのベストプラクティス
・250MBの圧縮チャンクにする
・テーブルレベルでベンチマークする必要はある
・ディストリビューションキーとしてセッションIDを使って分散した
・テーブルレベルでベンチマークする必要はある
・ディストリビューションキーとしてセッションIDを使って分散した
・カラムコンプレッションは使うべき
私達は ANALYZE COMPRESSIONを使っている
その他にもありますが、正確に書くのが難しそうなのでそのまま画像貼り付けますね



パフォーマンスーローディングデータ
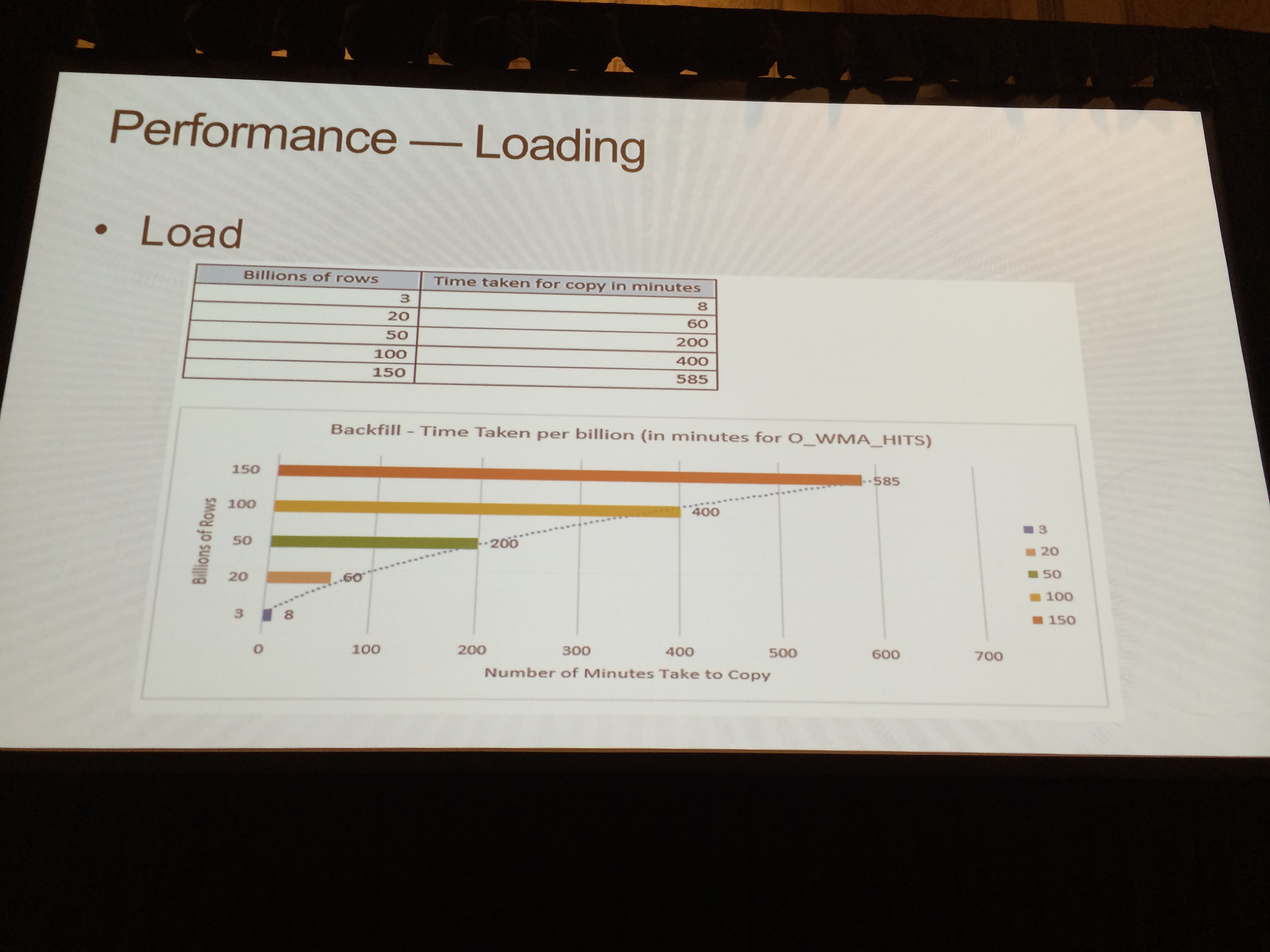
15億レコードで10時間切るくらいですかね
パフォーマンスーロングクエリ

ロングクエリでは Amazon Redshift の方が86%速くなったとのこと
パフォーマンスーショートクエリ

逆にショートクエリではOracleの方が66%速いみたいですね
パフォーマンス メンテナンス

やはりリストアには時間がかかりますね
改善されたパフォーマンス

・Pig から redshift: 2日から1時間に短縮
・Hiveからredshift: 3日間から2時間に短縮
・Oracleから Redshift: 90時間から8時間に短縮
・Hiveからredshift: 3日間から2時間に短縮
・Oracleから Redshift: 90時間から8時間に短縮
質疑応答
Q, どうやって最適化するのか
A, カーディナリティが重要、ローカルジョインは問題が出てくる
A, カーディナリティが重要、ローカルジョインは問題が出てくる
Q, どういうふうにロードするのか
A, S3で分割配置してロードしている
A, S3で分割配置してロードしている
まとめ
規模がとんでもないので正直イメージが湧きづらいのですが、ペタバイトクラスのデータであっても工夫をすればRedshiftは高いパフォーマンスを発揮し、業務改善に大きく繋がることは理解できました。来年はうちのRedshiftマスターにぜひ行って欲しいですね。
このクラスの事例を日本でも早くほしいですね。実はもうあったりしてw
ではでは。