

クラウドインテグレーション部の村上です。
今回は「SageMaker Data Wranglerとはどのようなサービスかさわって学ぶ」というテーマで書いていきます。
- 機械学習におけるSageMaker Data Wranglerの位置づけ
- データの前処理って大事
- SageMaker Data Wranglerの機能
- SageMaker Data Wranglerをさわってみよう
- まとめ
機械学習におけるSageMaker Data Wranglerの位置づけ
まず、機械学習ではどんな作業があり、SageMaker Data Wranglerはどの部分を担うのか把握しておきます。
以下は2022年のAWS Summitの「クイックスタート機械学習 Amazon SageMaker 編」のセッション資料です。

https://pages.awscloud.com/rs/112-TZM-766/images/AWS-41_ml_quick_start_KMD02-KMD03-KMD06.pdf
絵に描いてあるとおり、SageMaker Data Wranglerはデータの準備や前処理を便利にしてくれるサービスです。
データの前処理って大事
機械学習といえば、「学習してモデルつくって推論する」なイメージですよね。少なくとも私はそうです。
しかし現実はそうではなく、2016年の調査では「エンジニアの時間の約 80% がデータの準備に費やされている」という結果だったそうです。実際のデータは欠損値や誤入力、異なるスケールなどがいっぱいで、きちんと整形する必要があるのは何となく想像できます。
汚いデータで学習しても良い精度が出るはずもありません。前処理って大事なんだなと思い知ったところで、いざ実際に学んでいきます。
SageMaker Data Wranglerの機能
SageMaker Data Wranglerには以下に例示したような、データの理解から特徴量エンジニアリングまで、幅広い用途に使える選択肢が300以上用意されています。
- 探索的データ分析(EDA)
- 欠損値の処理
- エンコーディング
- 正規化 など
SageMaker Data Wranglerをさわってみよう
それでは実際にSageMaker Data Wranglerをさわってみます。参考にしているのは公式ドキュメントのチュートリアルです。
使用するデータセットはタイタニック
機械学習におけるHello Worldって色々あるかもしれませんが、私にとってはタイタニックです。
このデータセットには、タイタニック号に乗船した乗客の年齢や性別、客室の等級などの情報があり、これらの情報から生存状況を予測します。
データをS3にアップロード
まずは公式ドキュメントからデータセットをダウンロードして、任意のS3バケットにアップロードします。
SageMaker Data Wranglerを起動する
SageMaker Studio を開き、New data flowを選択します。

起動すると、以下のような画面になりますので、Import dataを選択します。

インスタンスタイプはm5.4xlargeがデフォルト
デフォルトではml.m5.4xlargeが起動します。
デフォルトでは、Data Wrangler は m5.4xlarge インスタンスを使用します。
大きなデータセットを扱わないときは、インスタンスタイプを小さいものに変更したいと思うかもしれませんが、SageMaker Data Wranglerではm5.4xlargeが最小のインスタンスタイプです。起動しっぱなしに注意しましょう。
データをS3からインポート
インポート元はS3だけでなくAmazon Athena、Amazon Redshiftなど対応しているようです。今回はS3を選びます。

データセットの一部だけインポートすることもできる
最初のk行だけインポートする、ランダムにインポートする、などデータセットの一部だけインポートすることも可能です。
stratified(階層化された)とは、選択したカラムに存在にする値の比率を保ったままランダムにインポートするという意味です。例えば、データセットに「性別」というカラムがあり、男女比の比率を保ったままデータセットの一部をランダムにインポートしたい場合は、ここで「性別」のカラムを選択します。
機械学習の知識がある人はscikit-learnのStratifiedKFoldを想像すると分かりやすいかと思います。

とはいえ、タイタニックのデータセットは小さいので全部インポートします。
SageMaker Data Wranglerの画面
こんな感じの画面です。+ボタンを押してデータの変換や分析をします。

データ分析
インサイトを得る
2022年のアップデートでデータに関するインサイトを簡単に得られるようになりました。
インサイトを見るにはData typesの横の+をクリックして、Get data insghtsを選択します。

すると下記のような画面に遷移します。Target columnには予測したいカラムを選択します。今回は生存予測をするのでsurvivedです。
Problem typeでは回帰または分類を選択します。今回は「0 = No(死亡), 1 = Yes(生存)」の二値分類なのでClassificationを選択します。

インサイトでは主に以下のような情報を見ることができます。
- 統計情報(Summary)
- ターゲット列のインサイト(Target column)
- クイックモデル(Quick model)
- 特徴量の概要(Feature summary)
統計情報(Summary)
特徴量の数や行数、欠損値の比率などを見ることができます。

ターゲット列のインサイト(Target column)
ターゲットに設定したカラムの欠損値の比率などを見ることができます。
タイタニックのデータセットでは0が死亡を意味しているので、乗客の61.8%が死亡したことが分かります(実際の事故の生存率とは若干違います)。いかに大きな海難事故だったのかが分かりますね...。

クイックモデル(Quick model)
クイックモデルではデータセットを学習データ(80%)、検証データ(20%)に分割して、トレーニングを行ってくれます。
使用されるのはXGBoostというアルゴリズムで、こちらの結果から「現状のデータセットからモデルをつくったらどれくらいの精度が出るか」を見ることができます。
タイタニックのデータセットの場合は、97.7%の正解率(accuracy)が出ていることが分かります。

特徴量の概要(Feature summary)
特徴量の重要度(Prediction power)などを見ることができます。
Prediction powerは0から1の間をとる数値で、1に近いほどターゲット列を予測するのに有用なカラムであることを意味しています。
タイタニック号で生死を分けたのは何だったのか、Feature summaryから結構分かりますね!
- 第1位の
boatは救命ボート番号のことです。 - 第2位は
nameです。親族は同じ名字で、かつ一緒に避難(もしくは死亡)したのかなと思いました(違ったらごめんなさい) - 第3位は
sexです。Wikipediaには女性や子どもが優先的に救命ボートに乗ったと書いてありました。 - 第4位の
fareは運賃です。客室の等級が高いほど生存率が高かったようです、怖いですね。

上記のように、ポチポチとインサイトを表示してみるだけで色々なことが分かります。SageMaker Data Wrangler便利ですね。
年齢と生存状況の関連をしらべる
インサイトの機能以外でも、データを分析することはできます。
個人的に「若い方が生存率高そう」って思っていたので、年齢と生存率をヒストグラムで表示してみます。
必要な手順はインサイトを得た時と同様の手順でAdd analysisから簡単に表示できます。必要なことは画面右側のところで、「ageとsurvivedのヒストグラムを表示して」と選択するのみです。
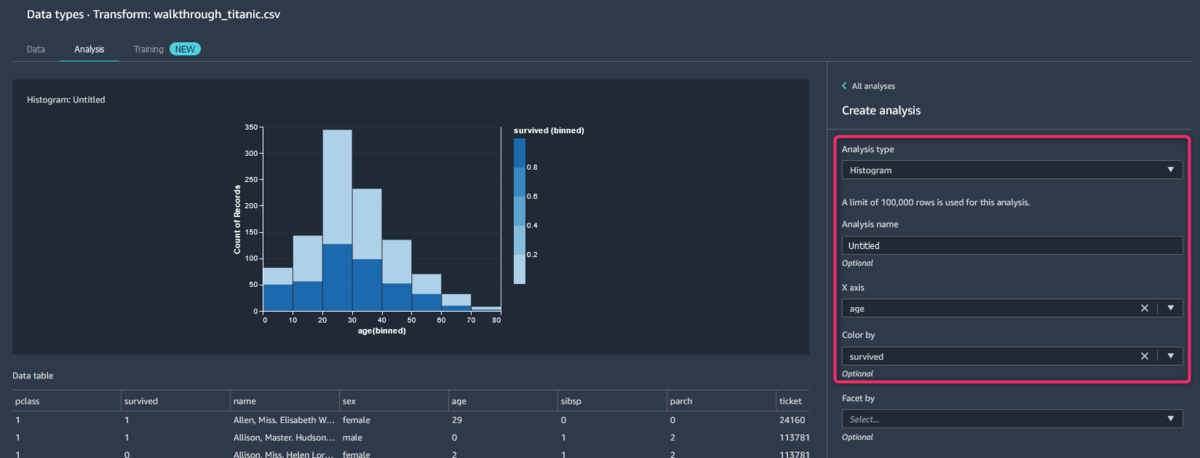
見てのとおり、年齢はあまり生存率に関係ないようですね(濃い青が生存、薄い青が死亡を表しています)。
データ分析のまとめ
上記で見てきたデータの分析や可視化は、例えばPythonであればPandasやMatplotlib、seabornなどのライブラリを使って行うかと思います。
Amazon SageMaker Data Wranglerを使えば、このようにポチポチするだけでできるので便利ですね。
データ変換
データ分析はこのへんにして、データの変換(Add transform)をやっていきます。

学習に使用しない列をドロップする
Add transform → Add steps → Manage columnsの順番で選択します。
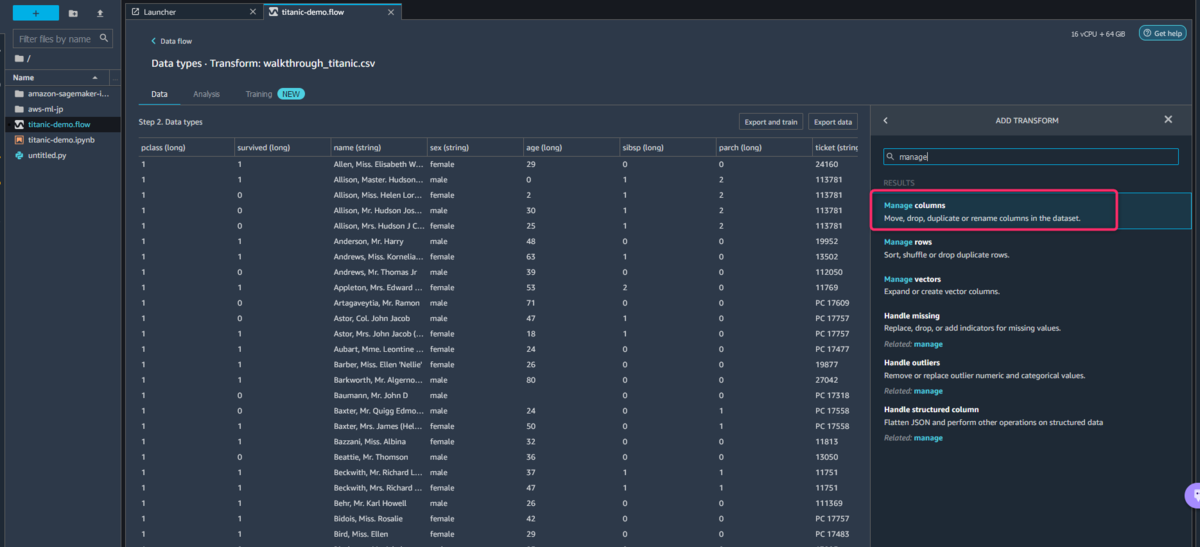
次にドロップしたいカラムをチェックすれば完了です。これだけでカラムを削除することができます。

欠損値の処理
Add transform → Add steps → Handle missingの順番で選択します。

欠損値のある行を削除する場合は、以下のようにDrop missingを選択し、次にどのカラムの欠損値を見るかリストから選択します。ほかにも、静的な値を欠損値に代入したり、平均値や中央値を代入したりすることもできます。

エンコーディング
カテゴリ変数のエンコーディングもできます。チュートリアルの方ではPandasを使ってワンホットエンコーディングしていましたが、Add transform → Add steps → Encode categoricalのメニューからでも可能です。

エンコーディング方法と対象のカラムを指定するだけです。

データ変換のまとめ
データ分析の時と同じ感想ですが、PythonのPandasやscikit-learnなどのライブラリを使って行う処理をポチポチするだけでできるので便利ですね。
まとめ
- Amazon SageMaker Data WranglerはS3などのデータソースをサポートしている。
- Amazon SageMaker Data Wranglerを使うとデータの分析や変換など、前処理が簡単にできる。
- タイタニック号の事故では、客室等級の高い人の生存率が高かった。切ない。
今回はAmazon SageMaker Data Wranglerのデータ分析・変換をメインに紹介しました。
Amazon SageMaker Data Wranglerは、処理のエクスポートや他のSageMakerの機能との連携など、本記事で紹介した以外のこともできます。そのあたりのことはまた別の機会にブログにしたいと思います。