

こんにちは😺
カスタマーサクセス部の山本です。
本記事の前提
Amazon Managed Grafana を利用している環境のお話です。
また、ご利用中の Amazon Managed Grafanaのデータソースに CloudWatch を追加していることも、前提となります。
CloudWatch を追加する方法については、以下の公式ドキュメントをご参照ください。
加えて、対象となる ECS クラスター で ECS Container Insights を有効にしている必要があります。
ECS Container Insights を有効にする方法については、以下の公式ドキュメントをご参照ください。
本記事を書く背景
ECS Container Insights を有効にしているときには、ECS サービスの様々なメトリクスを CloudWatch Metrics に自動的に記録します。
例として、CpuUtilized という CPU に関するメトリクスがあります。
このメトリクスは、タスク定義 (TaskDefinitionFamily)、クラスター(ClusterName)、クラスター内のサービス (ServiceName) という単位で生成します。

参考: Amazon ECS Container Insights メトリクス - Amazon CloudWatch
Grafana のデータソースに CloudWatch を追加しているときには、このメトリクスを元に、Grafana のダッシュボードにパネルを作成することができます。
クラスター毎の CPU 使用率や、サービス毎の CPU 使用率を表示するパネルを作成することが出来ます。
パネルの作成例:

メモリ使用率も同様に、クラスター毎やサービス毎の使用率を表示するパネルを作成することが出来ます。

パネルの作成例:

ECS サービスを構成する最小単位であるコンテナやタスク毎のメトリクスは提供されていません。
そのため、「特定のタスクに偏って CPU 使用率やメモリ使用率が上昇している」といった情報は、メトリクスからは分かりません。
例として、特定の WEB コンテナにセッションが偏ってしまうような場合に、検出できないということです。
CloudWatch Logs Insights のクエリから、タスク毎の CPU 使用率、メモリ使用率を可視化する
ECS Container Insights を有効にしているときには、タスク毎、コンテナ毎の CPU / メモリ使用率がパフォーマンスログに記録されます。
参考:Amazon ECS の Container Insights パフォーマンスログイベント - Amazon CloudWatch
パフォーマンスログは、CloudWatch Logs に /aws/ecs/containerinsights/<クラスター名>/performance というロググループ名で記録されます。

タスク毎、コンテナ毎のログは、 ロググループ内に FargateTelemetry-NNNN というログストリーム名で記録されます。

ログストリーム内のログのうち、"Type":"Task" のものがタスク毎のログです。1 分に 1 回記録しているようです。

タスク毎の CPU 使用率、メモリ使用率が、このログには記録されています。

CloudWatch Logs Insights のクエリを使用すると、このログを元にCPU 使用率、メモリ使用率を抽出することが出来ます。
参考:CloudWatch Logs Insights のクエリから、タスク毎の CPU 使用率、メモリ使用率を可視化する
CPU 使用率を抽出した例:

このクエリを応用し、Grafana にタスク毎の CPU 使用率、メモリ使用率を表示するパネルを作成することができます。
Grafana のパネルに CloudWatch Logs Insights のクエリを記述する
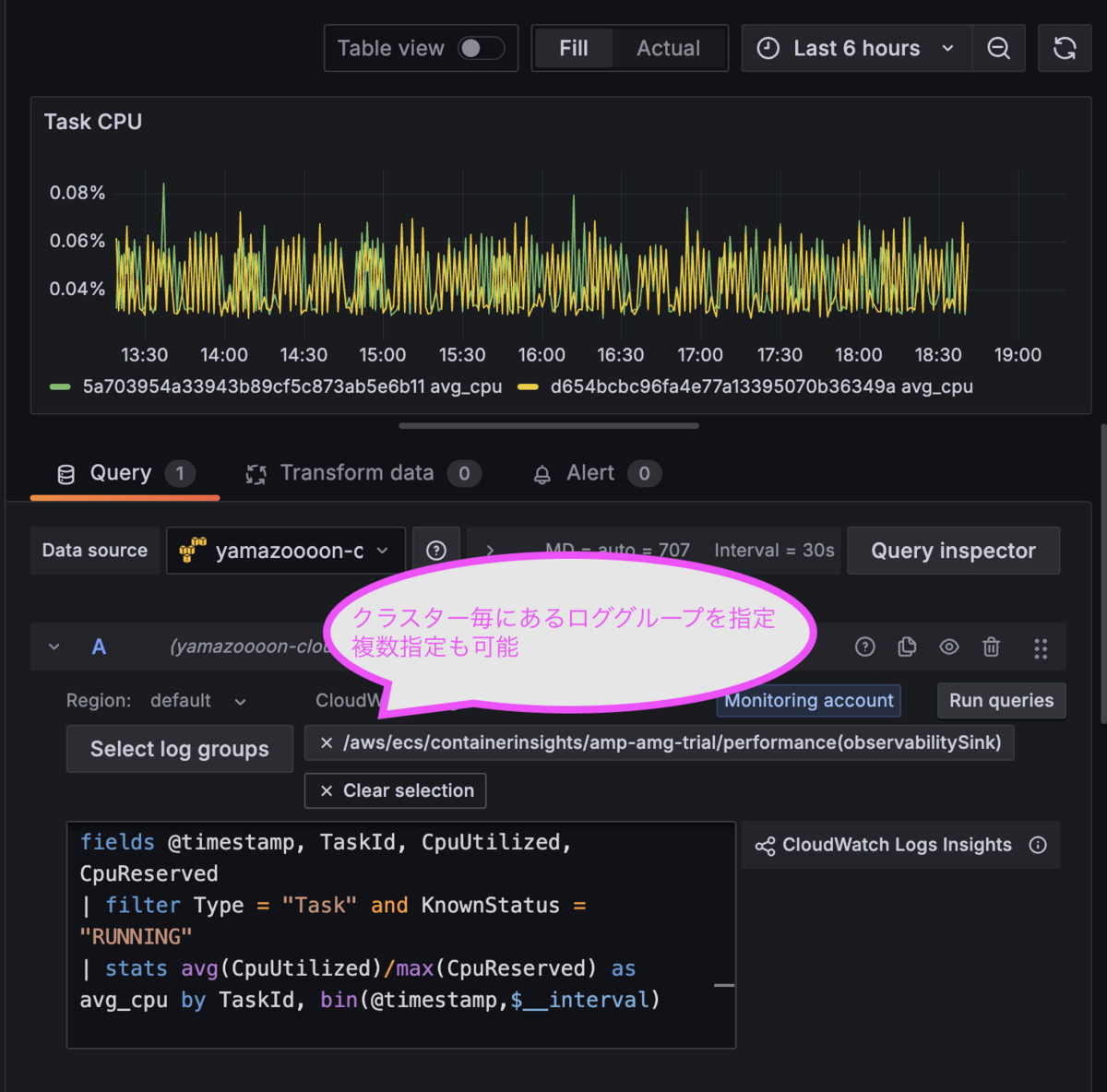
ECS サービスのタスク毎の CPU 使用率、メモリ使用率を表示するパネルを作成します。
Grafana のパネルに CloudWatch Logs Insights のクエリを記述します。
パネルの編集画面で、CloudWatch Logs を選択し、ロググループを選択し、クエリを記述します。

作成した CloudWatch Logs Insights のクエリ
以下のクエリを作成しました。
- CPU 使用率
fields @timestamp, TaskId, CpuUtilized, CpuReserved | filter Type = "Task" and KnownStatus = "RUNNING" | stats avg(CpuUtilized)/max(CpuReserved) as avg_cpu by TaskId, bin(@timestamp,$__interval)
- メモリ 使用率
fields @timestamp, TaskId, MemoryUtilized, MemoryReserved | filter Type = "Task" and KnownStatus = "RUNNING" | stats avg(MemoryUtilized)/max(MemoryReserved) as avg_memory by TaskId, bin(@timestamp, $__interval)
クエリの説明
上の2つのクエリを利用すると、 ダッシュボードで指定した時間間隔における、起動中の ECS タスク毎の CPU / メモリの使用率 を確認することができます。
例として CPU 使用率のクエリを引用して説明します。
ECS の Container Insights パフォーマンスログについては、 以下のログフォーマットになっています。
Amazon ECS の Container Insights パフォーマンスログイベント
フィールド (fields) は、パフォーマンスログからタスク ID(TaskId) 、 CPUユニット数(CpuUtilized)、予約している CPU ユニット数(CpuReserved)を利用します。
また、CloudWatch Logs Insights でログイベントのタイムスタンプ(日時)を表す特別なフィールドである @timestamp を利用します。
補足:Grafana では CloudWatch Logs Insights のクエリ実行時に自動的に フィールド (fields) を追加しているので、実際は@timestamp のみでも動作します。
fields @timestamp, TaskId, CpuUtilized, CpuReserved
フィルター(filter)では、状態(KnownStatus)が RUNNING となっており、種別が Task となっているログのみを抽出します。
これにより、起動中(RUNNING )であるタスク(Task)のCPU 使用率の平均を出力します。
| filter Type = "Task" and KnownStatus = "RUNNING"
集計(stats)では、 CPU 使用率を計算するために、予約している CPU ユニット数である CpuReserved を用いて CPU ユニット数(CpuUtilized)を除算しています。
また、タスク ID (TaskId) と 時間間隔(bin(@timestamp, $__interval)) ごとに CPU / メモリ使用率の平均を計算します。
bin(@timestamp, $__interval) は時間間隔でデータを集計するためのもので、$__interval はダッシュボードの設定に応じて動的に設定される時間間隔を意味します。
Grafana が提供している特別な変数です。
例を挙げると、もし、$__interval内での @timestamp ごとの CpuUtilized の値が [50, 60, 70, 80] であれば、avg(CpuUtilized) は (50 + 60 + 70 + 80) / 4 = 65 となります。
ダッシュボードの設定に応じて動的に設定される時間間隔($__interval) での CPU 使用率の平均値を確認できるということです。
| stats avg(CpuUtilized)/max(CpuReserved) as avg_cpu by TaskId, bin(@timestamp,$__interval)
6/14 訂正
6/13 にブログを公開した際に、CpuUtilized や MemoryUtilized を CPU 使用率、メモリ使用率と誤って認識し記載していました。
正しくは、CpuUtilized については利用中の CPU ユニット数を表し、 MemoryUtilized についてはメモリ利用量(単位:メガバイト)を表します。
CPU 使用率を計算する際には、予約している CPU ユニット数である CpuReserved を用いて CPU ユニット数(CpuUtilized)を除算する必要があります。
また、メモリ使用率を計算する際には、予約している メモリ利用量(単位:メガバイト)である MemoryUtilized を用いて、メモリ利用量(MemoryUtilized) を除算する必要があります。
- 修正前:CPU 使用率
| stats avg(CpuUtilized) as avg_cpu by TaskId, bin(@timestamp, $__interval)
- 修正後:CPU 使用率
| stats avg(CpuUtilized)/max(CpuReserved) as avg_cpu by TaskId, bin(@timestamp,$__interval)
- 修正前:メモリ 使用率
| stats avg(MemoryUtilized) as avg_memory by TaskId, bin(@timestamp, $__interval)
- 修正後:メモリ 使用率
| stats avg(MemoryUtilized)/max(MemoryReserved) as avg_memory by TaskId, bin(@timestamp, $__interval)
Grafana のダッシュボードに表示するために行うパネル設定
パネル内では、対象にする CloudWatch のロググループを指定することができます。
パフォーマンスログの CloudWatch ロググループは、ECS クラスター毎に分かれています。
そのため、パネルもクラスター毎に作成することが出来ます。
1つのパネルの中に、1つのクラスター内にある各 ECS サービスのタスク毎の情報( CPU /メモリ 使用率の平均)を記録するようにできます。
表示単位(unit) の設定をします。Percent (0.0-1.0) を設定すると、% 表示に出来ます。Max に 1 を指定すると、グラフの上限値が 100% になります。

Grafana のダッシュボードの表示間隔・自動更新頻度の設定
表示間隔・自動更新頻度を設定する場所です。
この設定で利用料金が変わってきます。詳細は後述します。
表示間隔

自動更新頻度

ダッシュボードの例(画面)
実際にダッシュボードを作成してみました。
グラフに表示する値を確認してみます。
グラフには 1 分毎のデータが表示されています。
2024-06-14 18:00:00
ある1つのタスクの CPU 使用率の値:0.0687 %

2024-06-14 18:01:00
ある1つのタスクの CPU 使用率の値:0.0464 %

ダッシュボードの表示間隔や自動更新頻度を変えてみました。
変えた後もグラフには 1 分毎のデータが表示されています。

ダッシュボードの設定に応じて動的に設定される時間間隔(
$__interval)
と上で説明した部分はログの出力単位である1分毎でした。1分毎のメトリクスがグラフに出ています。
avg 関数で平均を出しているものの、1つのログが対象になるので、1分毎の CpuUtilized をそのまま表示しているのと変わりません。
Grafana のダッシュボードに表示する際の料金
ダッシュボードを作成した後には、CloudTrail に StartQuery と GetQueryResults のイベントが出るようになります。
このうち、GetQueryResults については、ダッシュボードの画面をユーザーが参照したり、リロードする際に発生します。これは、スキャンした後のデータを参照する API であるため無料になります。
料金がかかるのは、StartQuery での CloudWatch Logs Insights によるパフォーマンスログのスキャンです。
CloudWatch Logs Insights では、スキャンしたログの量に応じて料金が発生します。
StartQuery でのログのスキャン量は、ダッシュボードの表示間隔、ダッシュボードの自動更新頻度、スキャンするログの量(タスクの数によって増減)によって変わります。
料金は以下です。
スキャンしたデータ 1 GB あたり USD 0.0076
パネルを1つ用意し、以下の条件で検証を行いました。
- ダッシュボードの表示間隔:30 分間の情報を表示
- ダッシュボードの自動更新頻度: 1 分
- ECS サービス数: 3
- ECS タスク数:4
この場合、StartQuery でのログのスキャンは、1 分に 1 回実行され、直前の 30 分間のログをスキャンします。
対象は 4 つの ECS タスクです。
1 回の実行では、約 400 KBがスキャンされていました。
同一の CloudWatch Logs Insights のクエリを手動実行し確認しました。

1ヶ月分の料金試算
1 時間に 60 回実行されるので、 1日分は 400 KB * 60 min * 24 hours = 576,000 KB です。 GB 表記に直すと、スキャンしたログの量は 0.55 GB になります。
1 ヶ月を 30 日とすると、0.55 GB * 30 days = 16.5 GB になります。
1 GB あたり 0.0076 USD なので、0.0076 * 16.5 GB と仮置きすると、0.1254 USD です。
1 USD 150 円として、1つのパネルの月額は 18 円ということになります。
まとめ
Grafana のダッシュボードに ECS サービスのタスク毎の CPU 使用率、メモリ使用率を表示するパネルを作成してみました。
CloudWatch Logs Insights のクエリを、Grafana 用に少しカスタマイズすることで、パネルを作成することが出来ました。
余談
同僚と山梨県の七面山に登ってきました。
南アルプスの特有の崩れが美しかったです。
下山後の身延の温泉にも癒やされました。

