

はじめに
本稿はAmazon OpenSearch Serviceを利用する上でのindexの運用の基本知識を紹介していく連載の第二弾です。
前稿ではOpenSearchのindexをめぐる基本概念・基本知識について説明しました。
特に1shardあたりで管理するデータ容量を適切に保つことが必要であることをお話ししましたが
本稿では日々増えゆくデータに対してOpenSearchで用意されている運用の自動化・効率化機構についてご紹介したいと思います。
なお、本稿はサーバーワークスアドベントカレンダー18日目の投稿でもあります。
※ 上記章立ての「4.小括」の「図によるまとめ」をご覧いただくと、本稿でお話しする機能の大まかな全体像が掴めます。
Index State Managementについて
概要
OpenSearchでは1 shardあたりで管理するデータ容量が肥大化しすぎないように注意したり、ストレージが溢れてしまわないように注意したりする必要がある・・・と述べました。
実際の運用で、閾値を定期的に人力でチェックして調整作業を実施するのはあまり現実的なオペレーションではありません。
幸いOpenSearch ServiceではIndex State Management (以下ISM)と呼ばれる機構があります。
「あるindex」が「特定の状態に達したこと」に起因して「特定のアクション」を自動でトリガーするように規定できる自動制御のためのプラグイン機能です。
Amazon OpenSearch Serviceについてはデフォルトで組み込まれているプラグインとなっています。
より厳密に言えば以下のような仕組みです。
- 特定の命名規則のindexに対してstateを必要個数分定義しておく。「ある種別のindexに関して想定されるライフサイクル」の各ステップを示す役割を持つ
- 各state内ではさらに以下のような項目を定義することで、indexが意図したタイミングで別のstateに遷移して適切な処置が自動で施されるように構成することができる
- action:そのstateに遷移した際にどのような処理を行うかを定義する。
- 失敗時のリトライの諸条件等についても規定可能
- transition:次のstateに遷移するための条件を定義する。あるstateについて仮に本項目が定義されていない場合、 ISMは一通りの遷移が完了したとみなしてindexの管理を停止する
- 遷移の条件についてはindexの容量・作成されてからの経過日時・documentの数量等が規定可能
- action:そのstateに遷移した際にどのような処理を行うかを定義する。
例えば、以下のような具合に用いることができます。
- current・old・deleteという3つのstatusを定義
- indexは作成当初はcurrentというstatusに置かれようにする
- 30日を経過したタイミングでは検索対象にされることが減るためそのタイミングでoldというstatusに遷移させてreplica shardの個数を2から1に変更して読み込みキャパシティの低下と引き換えに容量を節約する
- さらに半年を経過したタイミングでdeleteに移行させてindex自体を削除してしまう
具体定義例
ISMは実際にはjson形式で定義されます。ここで、先ほど例示したようなライフサイクルをjsonに落とし込むとどのような形になるか以下に具体例をお示ししましょう。
{
"policy": {
"description": "Changes replica count and deletes.",
"schema_version": 1,
"default_state": "current",
"states": [{
"name": "current",
"actions": [],
"transitions": [{
"state_name": "old",
"conditions": {
"min_index_age": "30d"
}
}]
},
{
"name": "old",
"actions": [{
"replica_count": {
"number_of_replicas": 1
}
}],
"transitions": [{
"state_name": "delete",
"conditions": {
"min_index_age": "90d"
}
}]
},
{
"name": "delete",
"actions": [{
"delete": {}
}],
"transitions": []
}
],
"ism_template": [
{
"index_patterns": [
"index-*"
],
"priority": 100
}
]
}
}
これらの遷移についてはindex_patternsに示されている通り「index-*」の条件に当てはまるindex、すなわちindex-000001・index-typeA-000001等の名称のindexが適用の対象となることを示しています。
また、あるindexについて、各ISMポリシーのindex_patternsの定義内容次第では、複数のISMポリシーが適用対象になることがありえます。
その場合は複数のISMポリシーが当該indexに適用されることはなく、単一のISMポリシーが選択されます。
その際の選択の判定基準となるのがpriorityであり、今回の例の場合、priorityが100より高いISMポリシーが他になかった場合は本ポリシーがindexに適用されることとなります。
より詳細な設定内容を学びたい方については以下のドキュメントをお時間がある時に読んでみてください。
Index State Management - OpenSearch documentation
Amazon OpenSearch Service でのインデックスステート管理 - Amazon OpenSearch Service
rollover・alias・index template
さて、先ほどの説明である種別・ある命名規則のindexがISMポリシーの適用対象になると述べました。
初学者の方からするとAOSでは異なる種別のindex・似たような命名規則のindexが複数併存するのか?というところがいまいちピンとこないかもしれません。
結論としては併存することはあります。
この点を理解するためにISMで定義できるactionの中でも最も重要なactionの一つであるrolloverと、rolloverの運用ととても密接な関係を持つ機能であるaliasとindex templateについて触れて
本稿を終えることにしましょう(連載自体はまだ続きます)
rolloverについて(粗々)
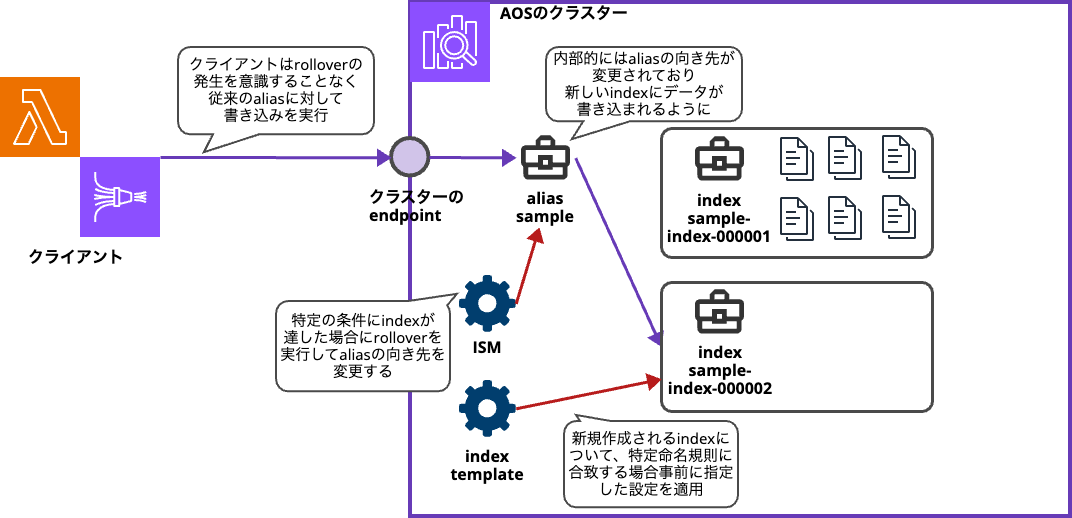
まず、rolloverとはざっくり言うと「あるindexがデータを受け入れ続けて肥大化しすぎないように、新しい空のindexを発行して新規にデータを受け付けるようにする」機能です。
aliasについて
ここで鋭い方は「新しい空のindexを作ったのはいいけれども、今までデータを投入してきたプログラム側でindex名の切り替えが必要になってしまうのでは?」と思ったかもしれません。
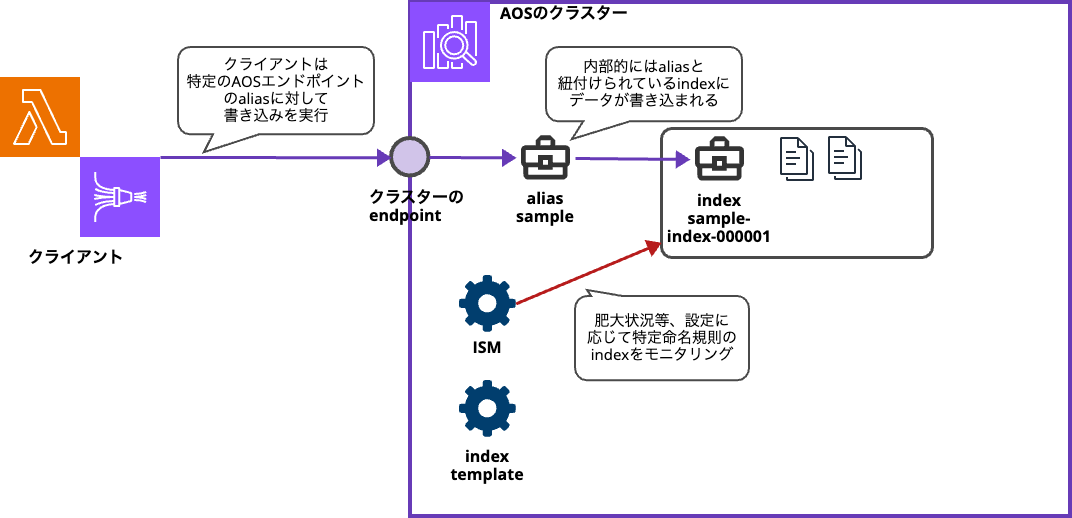
そのような手間を省くためにOpenSearchのindexにはaliasという機構があります。
alias( = 別名)とはその名の通り、例えばsample-index-000001というindexについてsampleという別名をつけておいて
別名(今回の例でいえばsample)の指定でもって目当てのindex(sample-index-000001)にアクセスさせることができる機能です。
rolloverについて(詳細)
rolloverの挙動について、より厳密にその内容を説明すると以下のようなオペレーションを実施してくれています。
- 対象のindexについて「aliasが付与されていること」と「index名のサフィックスに連番がついていること」を前提として
-「サフィックスをインクリメントしたindexを新規作成」しつつ
- sample-index-000001がrolloverの対象となった場合は、sample-index-000002というindexが新規作成されます -「aliasの向き先を新規作成したindexに切り替える」処理を実施
つまりデータを投入するプログラム側からすれば、普段はaliasのsampleという名称のindexに対してdocumentを投入するようにしておきさえすれば
rolloverにより裏側ではsample-index-000001から新規作成のsample-index-000002にaliasの向き先が切り替わっていたとしても特に意識することなく投入処理を継続できるということになるわけです。
rolloverを実施するためのISMポリシーの例
ここで、rolloverを扱うISMポリシーの例を見てみましょう
{
"policy": {
"policy_id": "Roll_over_policy",
"description": "A test policy. DO NOT USE FOR PRODUCTION!",
"schema_version": 1,
"error_notification": null,
"default_state": "hot",
"states": [
{
"name": "hot",
"actions": [
{
"rollover": {
"min_size": "30gb"
}
}
],
"transitions": [
{
"state_name": "warm"
}
]
},
{
"name": "warm",
"actions": [
{
"replica_count": {
"number_of_replicas": 2
}
}
],
"transitions": []
}
]
}
}
対象のindexの容量(min_size)が30GBに達した場合にrolloverを実施させるようなポリシーです。
ここでいう対象のindexの容量 = primary shardの合計容量です(replica shardの容量は考慮されません)。
仮に「1 shardあたりの管理容量が30GBに達した段階でrolloverを発生させたい」ケースを考えた場合、primary shard数が1のindexの場合では今回の例の設定でOKですが
primary shard数が3のindexであった場合は、min_sizeには90gbを指定するのが妥当ということになります。
rolloverを自動実行するには対象のaliasを明示的に把握できなければいけない
上述のrollover実行用のポリシー例についてはindex_patterns(どのindexにISMのポリシーを適用するか)という設定項目を追記してやりさえすれば問題なく動作するはずですが
特にrollover時に切り替えを行うaliasについては条件が記されていません。
1つのindexには複数のaliasがつきうるので、仮に複数あった場合は判断に困ってしまいそうです。
実はrollover時に切り替えるaliasについては、ISMポリシーで管理するindexに対して事前に指定・定義しておく必要があります。
index templateについて
では、rolloverで新規作成されたindexには都度手動でaliasに関する定義を付け足す手間が生じるのでしょうか・・・?
そのようなことはなく新規作成されたindexについては、諸々の設定を自動で適用するための機構がOpenSearchには備わっています。その機構がindex templateです。
以下がindex templateの作成例です。
PUT _template/sample_template
{
"index_patterns": "sample-*",
"priority": 100,
"template": {
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"index.opendistro.index_state_management.rollover_alias": "sample"
},
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"temperature": {
"type": "float"
},
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd'T'HH:mm:ss"
}
}
}
}
}
ISMポリシーと同じような形で「適用の対象とするindexのパターン(index_patterns)」と「適用ポリシー候補が複数あった場合の優先度(priority)」を規定しておき
実際に対象となったindexに対して各fieldのデータ型(template.mappings)やその他諸々の設定(template.settings)を自動適用することができます。
上記の例でいうところのtemplate.settings.index.opendistro.index_state_management.rollover_aliasがrollover用のaliasを指定するための設定です。
index templateの設定はrolloverの準備以外の様々な観点でも重要な役割を持っており
primary・replicaのshard数やrefresh(書き込みデータについてバッファメモリから実際にストレージに反映する処理)のintervalなど多様な設定を指定可能です。
これらの設定項目のいくつかについては後続の記事でもいくらか触れることになるとは思いますが
現時点でtemplate.settingsやtempate.mappingsの設定の幅について気になる方は適宜以下のドキュメントも参照してみてください。
Index settings - OpenSearch documentation
Mapping - OpenSearch documentation
小括
改めてindex templateやISMポリシーの必要性について
どのようなデータをどのような期間保存する必要があり、どのような書き込み・読み込み処理がどの程度の頻度発生するか。・・・こうした性質は保管するデータの種別によって異なるはずです。
そこでOpenSearchでは性質が異なるデータを別々のindexで管理しておき、それぞれに個別のindex templateやISMポリシーを適用して最適な運用を実現する必要があるのです。
もっとも、例えば会社のナレッジベースをOpenSearchのindexで管理するというような場合には短期間に極端にデータが増えることはなく
1つのindexで賄えてしまうことも多いでしょうから込み入ったISMポリシーは必要ではないかもしれません。
しかし、各種ログデータやセンサーデータのような時系列を扱うようなindexの場合である程度の期間の保存が必要な場合は
あらかじめ「-000001」というようなサフィックスの作ったindexを初期構築しておき
ISMポリシーのrolloverをはじめとした各種actionでindexを適正に管理するとともに、rolloverにより新規作成されたindexに対しても自動で設定が適用されるように
index templateも事前に考えて整備しておくことが必要と言えるでしょう。
図によるまとめ
今日のブログの内容を粗々で示した概念図を以下に添付しておきます。理解の補助にご利用ください。
おわりに
本稿では自動運用の肝となるISMポリシーと、その主要なactionの一つであるrolloverについて説明しました。
次項ではその他のISMポリシーのactionについてもかいつまんで説明したいと思います。