

こんにちは。技術1課@大阪オフィスの柏尾です。
今回はre:Inventで発表された「Amazon Athena」について書いてみようと思います。(re:Inventの動画はこちら)
Amazon Athena とは
Amazon Athenaはまとめると、下記のようなサービスです。
- Athenaは新しいサーバーレスのクエリサービスで、分散SQLエンジンのためのクラスタ構築・運用が不要
- Amazon S3に保存された膨大な量のデータを、標準SQLを使って簡単に分析できる(分散SQLエンジンPrestoベース)
- 利用者はS3に保存したデータに対して、テーブルやフィールドを定義、クエリを実行するだけ
- 実行クエリがスキャンしたデータ量に対してのみの課金($5/TB)
- JSON、CSV、ログファイル、カスタム区切りのテキスト、Apache Parquet、Apache ORC等を含む様々なフォーマットに対応
- AWS Management Console、Amazon QuickSightからのクエリ発行、Athena JDBCドライバを使うことで各種SQLクライアントからも接続可能
Amazon Athena を試してみる
サンプルのログ(ELBのログ)を集計するチュートリアルが用意されていますので、すぐにその機能を試すことができるようになっています。
チュートリアルの開始
右上にチュートリアルを開始するリンクがありますのでこれをクリックします。
※2016年12月時点で、Athenaのサービスを利用できるリージョンはバージニア、オレゴンです。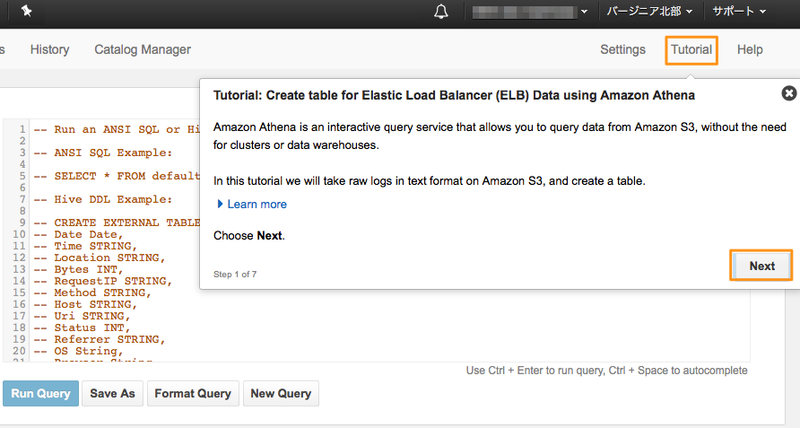
S3に保存されたデータに対してテーブルを定義するためのウィザードを実行していきます。「Next」で次に進みます。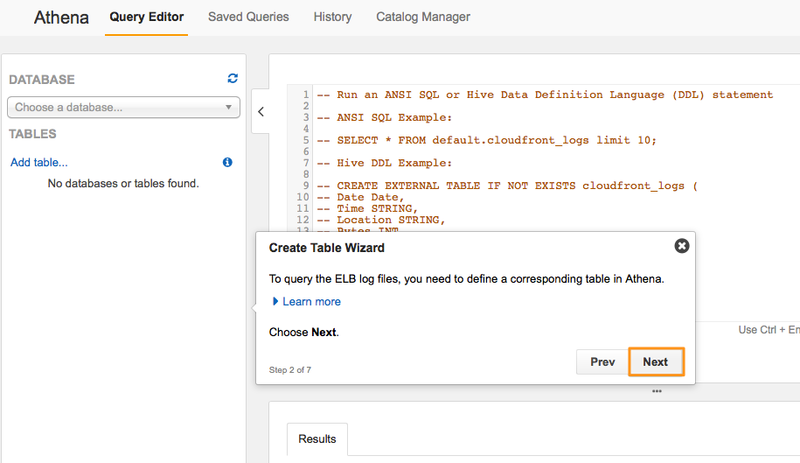
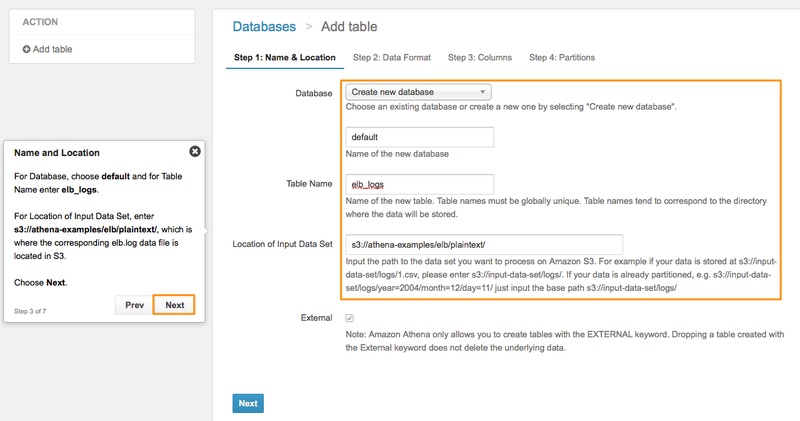
Step1. データベース名・テーブル名・ログ場所の指定
データベース名、テーブル名、ログの場所などを指定します。
| Database | 「Create new Database」を選択 |
| Name of new database | default |
| Table Name | elb_logs |
| Location of Iput Data | s3://athena-examples/elb/plaintext/ |
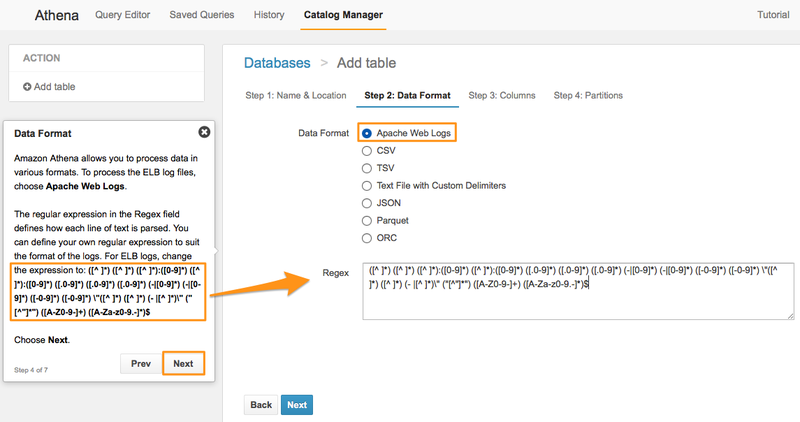
Step2. データフォーマット
データフォーマットは「Apache Web Logs」を指定します。
Regexの部分は、正規表現を使ってログのマッチする部分を抽出し、それをテーブルのフィールドとみなすための定義になります。 今回はELBのログが対象となります。チュートリアルのウィンドウ部分にELB用の正規表現が表示されていますので、それをそのままコピペします。
| Data Format | 「Apache Web Logs」を選択 |
| Regex | ※チュートリアルのウィンドウの正規表現をコピペ |
Step3. カラム定義
次のステップではカラム定義を行います。カラム名とカラムタイプを指定していきます。 チュートリアルでは左に表示されるウィンドウの「here」というリンクをクリックするとすべてのカラムが自動的に入力されます。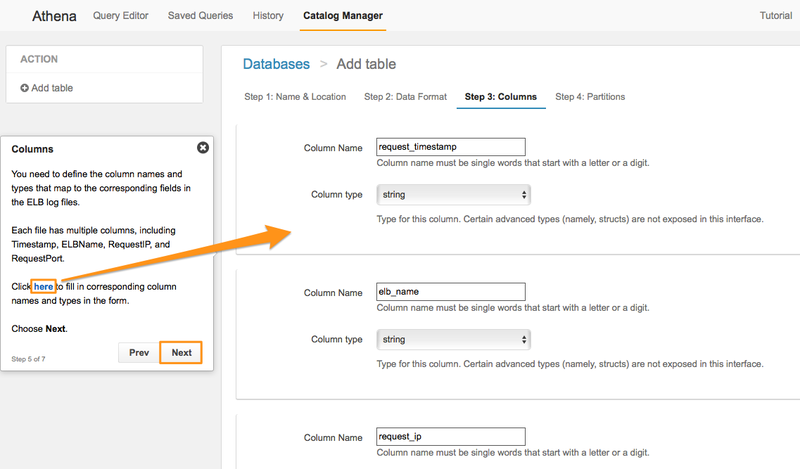
Step4. パーティション設定(オプション)
オプションとしてパーティション設定をすることができます。パーティションが利用可能な場合、クエリ実行時のデータスキャン範囲を限定できるため、コストの抑制・パフォーマンスの向上が可能になります。尚、今回のチュートリアルではスキップします。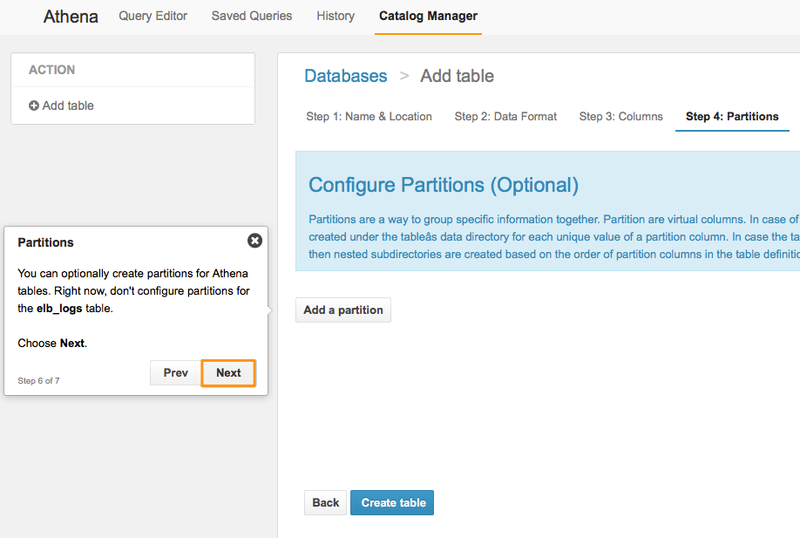
テーブル作成のクエリを実行
ウィザードが完了すると、テーブル作成用のクエリが構成されますので、「Run Query」をクリックし、テーブルの作成を実行します。
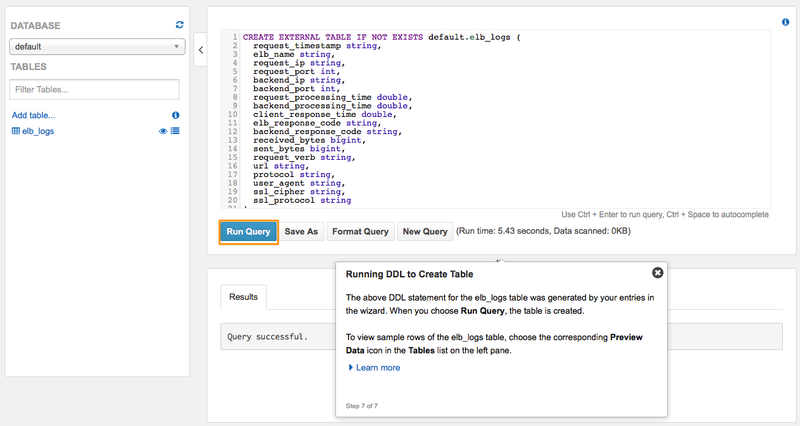
クエリの実行が完了すると、左部分に作成されたテーブル「elb_logs」が表示されます。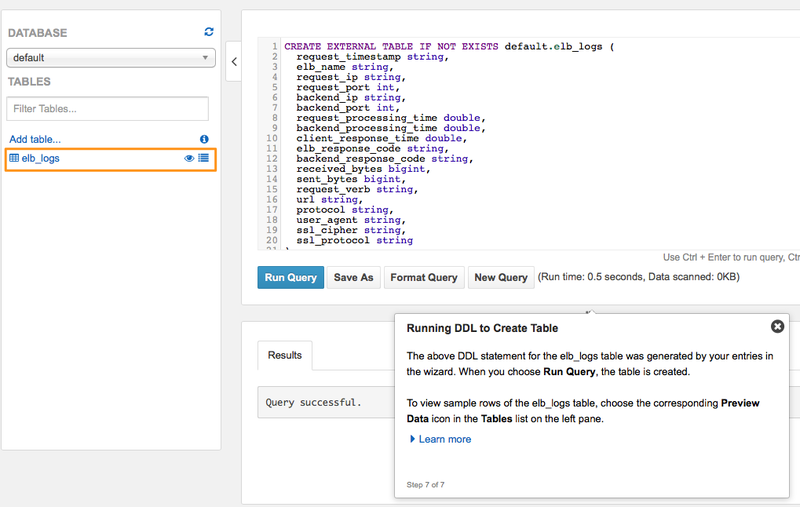
集計クエリを実行
作成したテーブルに対してクエリを実行します。
「Saved Queries」タブをクリックし、保存されているクエリを表示します。 デフォルトで「ELB Select Query」というクエリが保存されていますので、リンクをクリックします。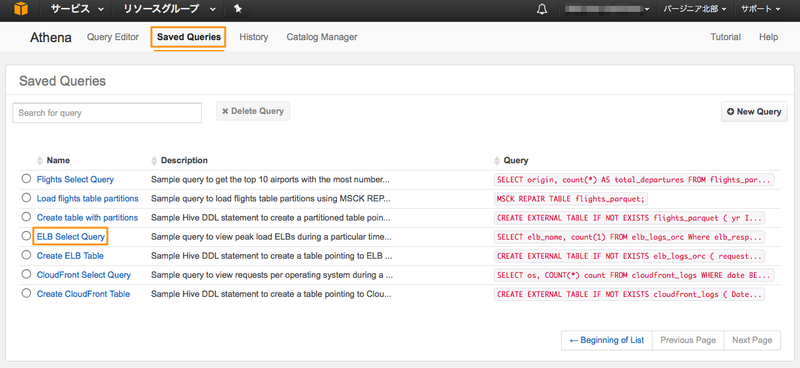
保存されているクエリが表示されます。
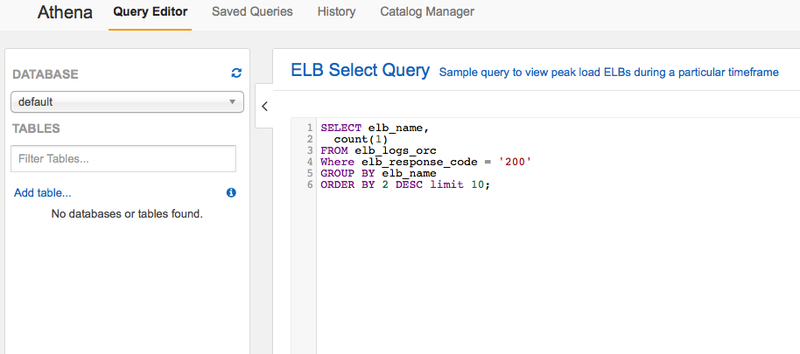
テーブル名が「elb_logs_orc」となっていますので、これを「elb_logs」に修正し、「Run Query」ボタンを押します。 ページ下部に結果が表示されれば成功です。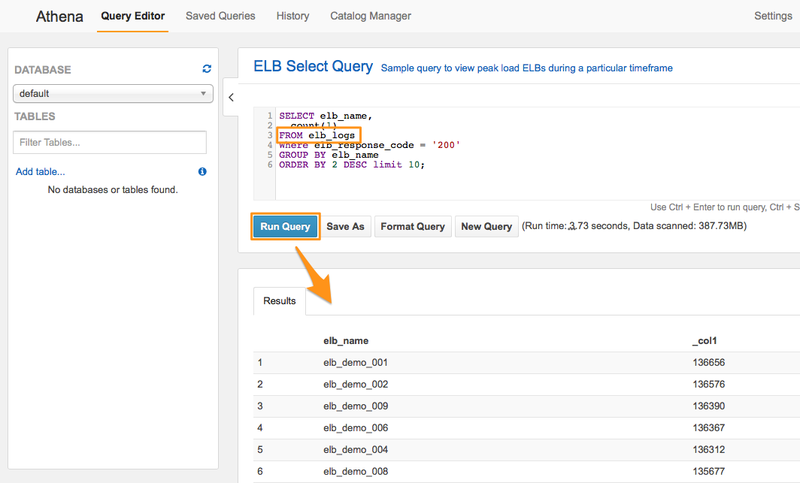
クエリの履歴を表示
「History」タブをクリックすると、過去に実行されたクエリの一覧が表示されます。 今回実行したクエリも表示されています。
実行ステータスや、スキャンしたデータのサイズが表示されています。 今回のクエリは3.73秒、スキャンしたデータは387.73MBになっています。
実行結果はS3上に保存されており、「Download results」から結果をダウンロードすることもできます。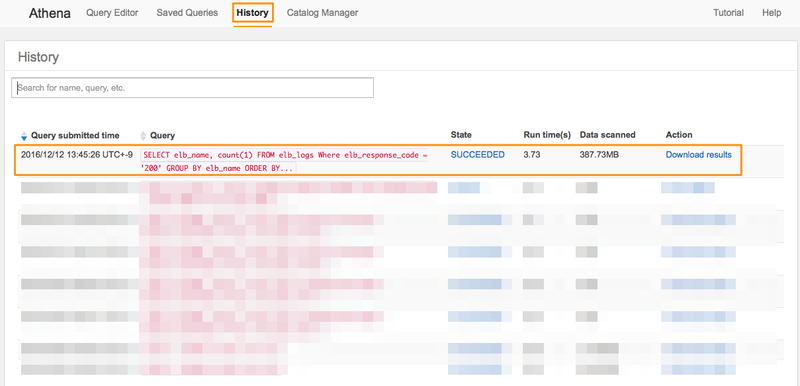
クエリ実行結果の保存先
「Setting」からは、クエリ実行結果の保存先の変更が可能になっています。
デフォルトでは、「s3://aws-athena-query-results-<アカウントID>-<リージョン>/」というバケットが指定されていました。 S3上にはバケットが作成されており、その配下には下記のようなパスで実行結果のcsvが保存されています。
S3上にはバケットが作成されており、その配下には下記のようなパスで実行結果のcsvが保存されています。
実行結果のCSVをダウンロードして中身を確認します。
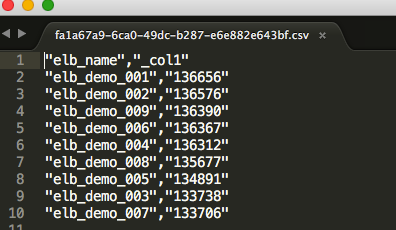
データのプレビュー・テーブルの詳細情報
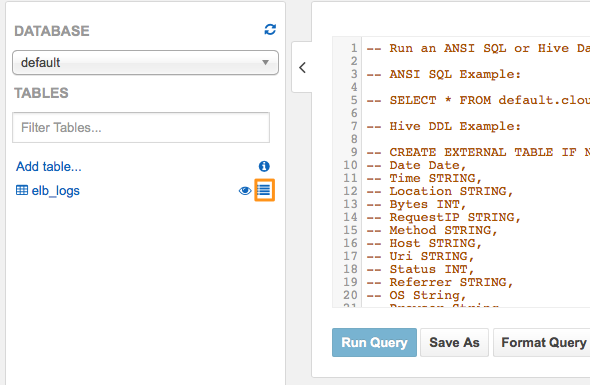
テーブル横にある目のマークをクリックすると、そのテーブルに入っているデータのプレビューを見ることができます。
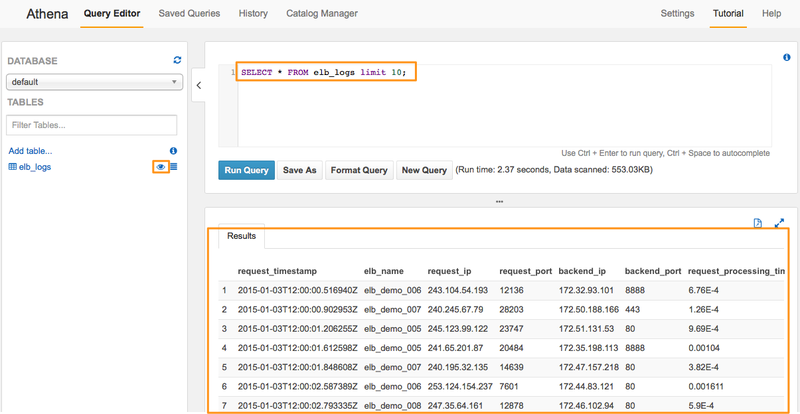
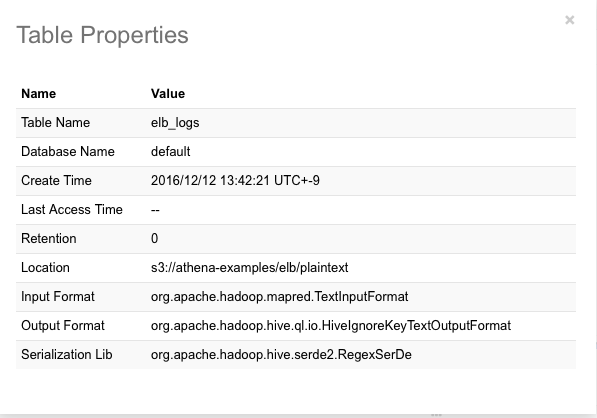
また、テーブル名の横にあるテーブルアイコンをクリックするとテーブルのプロパティが表示されます。 データの入出力フォーマット、データSerialize/Deserialize用ライブラリの情報も表示されます。
まとめ
これまでは、S3に保存した大量データの集計には、
- EMRでクラスタを立ち上げ、HiveやPrestoを使ってS3上のデータに対してクエリ発行
- RedshiftなどのDWH用データベースにデータ整形して保存後、クエリにて集計
- Query-as-a-Service(BigQueryやTreasure Dataなど)にデータを取り込み、クエリ実行
などの方法がありましたが、Athenaは新たな選択肢の一つになるのではないかと思います。