

こちらは後半の「NewRelicの設定とまとめ」部分です。
前半の「概要とDocker設定」部分は【初心者】NewRelicでDockerコンテナの数を監視してみた【1/2:Docker設定編】をご参照ください。
NewRelic
先ほどのトピックでは、EC2インスタンス上でWebサーバの機能を持つDockerコンテナを実行しました。
ここからはコンテナの数を監視するためのNewRelic設定をしていきます。
監視設定ファイルの作成準備
NewRelicエージェントはデフォルトでCPUやメモリの使用率を取得することができます。
デフォルト項目にない設定はコンフィグファイルを作成し、監視します。
例:ポートの死活監視、Webサービスの死活監視
以下のコマンドで設定ファイルを格納するディレクトリへ移動します。
cd /etc/newrelic-infra/integrations.d/
この内に、1つの監視設定に対してコンフィグファイルを2種類作成します。
1つは監視設定の本体となるYAMLファイル、
もう1つはYAMLファイル内で変数として利用できるJSONファイルです。
以下のようにファイルを作成します。
今回はコンテナ数のチェックを行うため、container_checkという名称にします。
/etc/newrelic-infra/integrations.d/:作業用ディレクトリ ┗━ container_check.yml:コンテナ数の監視設定を記述するファイル ┗━ container_check.json:今回はコンテナのイメージ名をここに記述
YAMLファイルの作成
以下のようにcontainer_check.ymlに書き込みます。
integrations:
- name: nri-flex
config:
name: ContainerCheck
lookup_file: /etc/newrelic-infra/integrations.d/container_check.json
apis:
- event_type: ContainerCheck
commands:
- run: echo ${lf:image_name}~$(docker ps --filter "ancestor=${lf:image_name}" --filter "status=running" --format "ImageID:{{.Image}} STATE:{{.State}}" | wc -l)
split_by: "~"
split: horizontal
set_header: [container_check.targetImage,container_check.running]
integrations
nameパラメータは監視形式の種類を記述します。NewRelicでは、多くのアプリケーションの監視設定をサポートしており、nameで指定することができます。今回設定したnri-flexは、サポートしているアプリケーションが存在しない場合や独自の監視設定を行いたい場合に利用します。
New Relic Flex:独自のインテグレーションを構築 | New Relic Documentation
config
nameパラメータは監視設定名を記述します。
lookup_fileパラメータはYAML内で参照するファイルを表しています。後述するパラメータで変数を利用する際にjson形式で記述します。
apis
event_typeパラメータはNewRelicダッシュボード上で表示されるイベント名を記述します。
commands
runパラメータでは、監視の際に実行するコマンドを記述します。コマンドの内容については後述します。
split_byパラメータでは、コマンドのレスポンスを分割する区切り文字を指定することができます。今回は~記号を使っているため、runコマンド内の~の位置で分割されます。
splitパラメータでは、レスポンスデータの分割方向を指定します。今回はholizontalを指定しているため、水平方向に分割します。
set_headerパラメータでは、分割したレスポンスを格納する変数を指定することができます。今回はcontainer_check.targetImageとcontainer_check.runningという二つの変数を用意しています。
JSONファイルの作成
以下のようにcontainer_check.jsonに書き込みます。
[
{
"image_name":"my_apache"
}
]
ここで記述したパラメータを変数として、YAMLファイル内で利用することができます。また、NewRelicは監視コマンド実行時にすべての変数に対して実行します。
監視コマンドの詳細
今回設定した実行コマンドは以下となっています。
echo ${lf:image_name}~$(docker ps --filter "ancestor=${lf:image_name}" --filter "status=running" --format "ImageID:{{.Image}} STATE:{{.State}}" | wc -l)
このコマンドは~記号で分割できます。
以下の前半部分のコマンドでは、どのイメージを監視対象としているか取得するため、echoコマンドで出力を行っています。
echo ${lf:image_name}
ここで${lf:image_name}部分には前述したJSONファイルに記述されたパラメータが埋め込まれます。
そのため、このコマンドの実行結果はmy_apacheとなります。
そして以下の後半部分のコマンドでは、起動しているDockerコンテナ数をカウントしています。
$(docker ps --filter "ancestor=${lf:image_name}" --filter "status=running" --format "ImageID:{{.Image}} STATE:{{.State}}" | wc -l)
ここではDockerの解説部分で触れたdocker psコマンドを使用しています。
--filterパラメータを用いて、表示するコンテナのフィルタリングを行っています。ancestor=${lf:image_name}では、先ほどと同様にJSONに記述されたパラメータを絞り込み、"status=running"では、現在起動中であるコンテナを絞り込んでいます。
さらに、--formatパラメータを加えることで、結果にヘッダ情報を含めずに出力することができます。
docker ps — Docker-docs-ja 24.0 ドキュメント
Dockerコンテナが2つ起動している状態で、パイプ文字(|)までのコマンドを実行した結果が以下になります。
# Dockerコンテナの状態を確認
docker ps
# 確認コマンドの実行結果
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a75ecedb4b08 my_apache "/usr/sbin/httpd -DF…" 22 minutes ago Up 22 minutes 0.0.0.0:58080->80/tcp, :::58080->80/tcp sad_cerf
8dfc7e7b77fe my_apache "/usr/sbin/httpd -DF…" 23 minutes ago Up 23 minutes 0.0.0.0:8080->80/tcp, :::8080->80/tcp vigorous_lamarr
# 監視コマンド
docker ps --filter "ancestor=my_apache" --filter "status=running" --format "ImageID:{{.Image}} STATE:{{.State}}"
# 監視コマンドの実行結果
ImageID:my_apache STATE:running
ImageID:my_apache STATE:running
実行されているコンテナ数の行が出力されるため、wc -lで行数をカウントします。
# 監視コマンド
docker ps --filter "ancestor=my_apache" --filter "status=running" --format "ImageID:{{.Image}} STATE:{{.State}}" | wc -l
# 監視コマンドの実行結果
2
監視設定のファイルが作成できたら、以下のコマンドでNewRelicエージェントを再起動しましょう。
sudo systemctl restart newrelic-infra.service
監視の可視化
監視対象サーバ内部の設定が完了したので、NewRelicダッシュボードから、取得した値を評価する設定を行います。
まずは、値が取得できている様子を確認してみましょう。画面左のペインからQuery Your Dataを選択すると、Query builder画面が開きます(図1)。
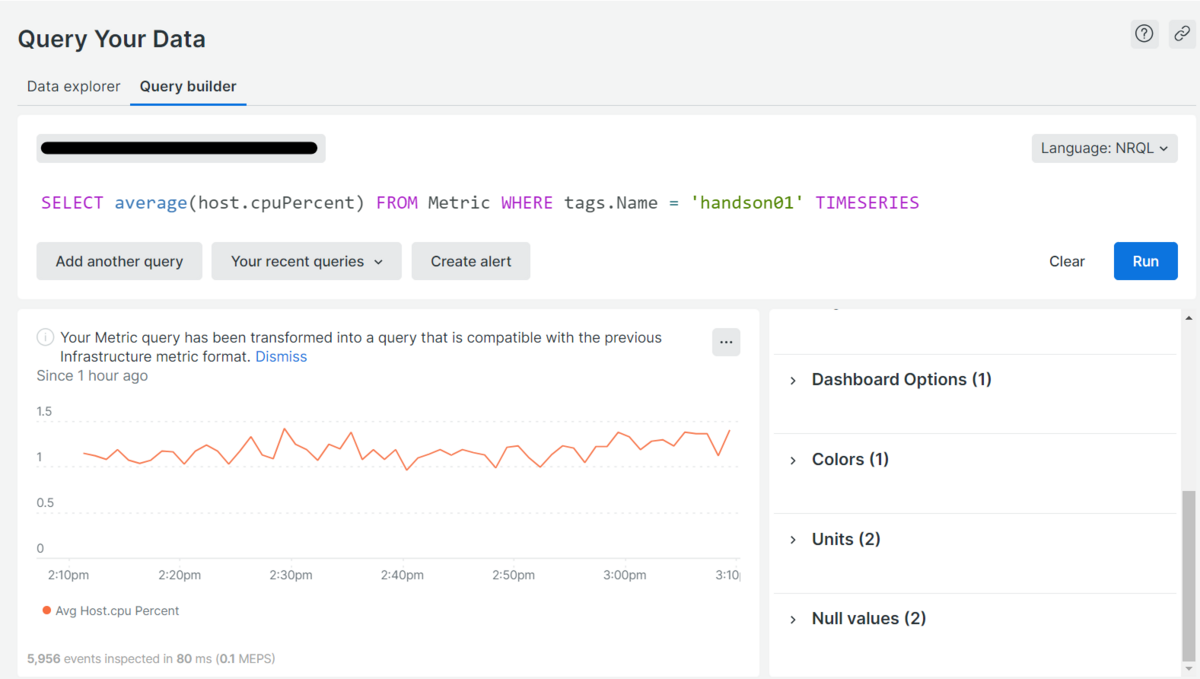
NewRelicではデータの取得にNew Relic Query Language(NRQL)というクエリ言語を利用します。実際に、エージェントをインストールした段階で取得される、CPU使用率を監視するクエリを記述してみましょう。以下のようにクエリを記述します。
SELECT average(host.cpuPercent) FROM Metric WHERE tags.Name = 'handson01' TIMESERIES
SELECT句では、取得したい値を指定します。host.cpuPercentは名の通り、サーバのCPU稼働率を取得します。average(*)のように値の加工も可能です。
FROM句では、データの取得元を指定します。今回のCPU使用率はデフォルトで存在するMetricから取得しています。
WHERE句では、取得するデータの条件を指定できます。tags.Nameを用いることで、EC2インスタンス名で絞り込みできます。
クエリの最後にTIMESERIESをつけることで、時系列データとして可視化できます(図2)。
NRQLについて:New Relicクエリ言語 | New Relic Documentation
それでは、今回自作した監視設定を可視化してみましょう。現在のコンテナの起動状況は以下のように、2台起動している状態です。
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 258b464d5c6b my_apache "/usr/sbin/httpd -DF…" 5 seconds ago Up 4 seconds 0.0.0.0:80->80/tcp, :::80->80/tcp mystifying_bartik f5135512ffbd my_apache "/usr/sbin/httpd -DF…" 19 seconds ago Up 18 seconds 0.0.0.0:8080->80/tcp, :::8080->80/tcp dazzling_rhodes
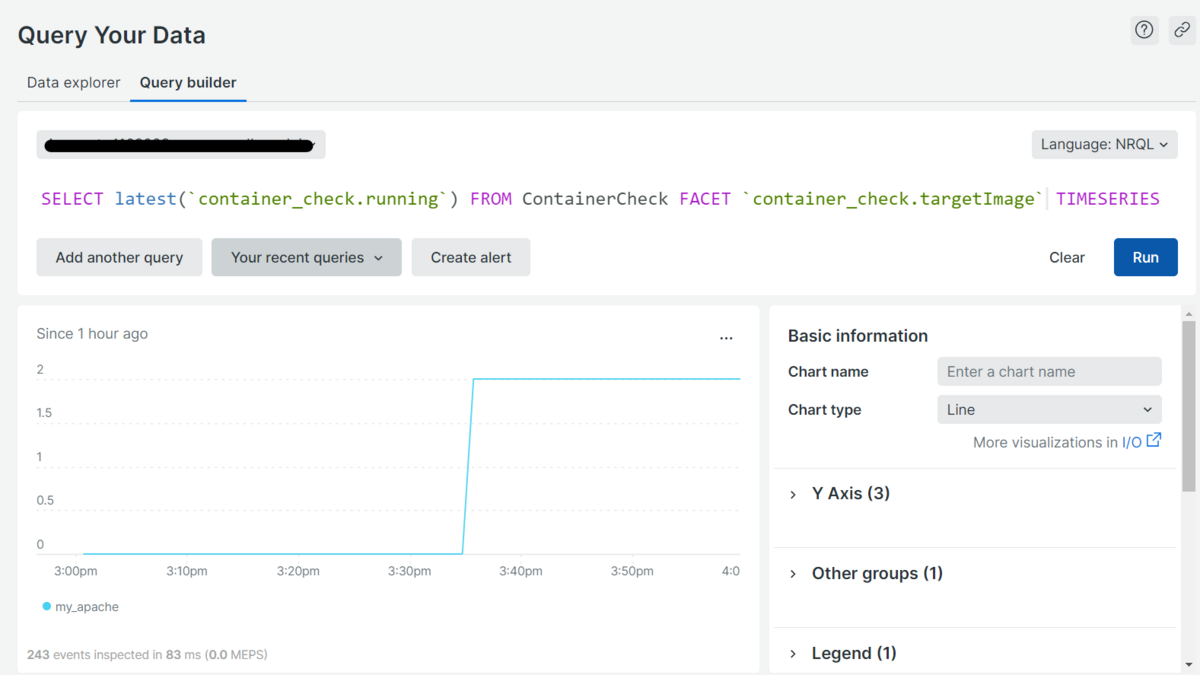
コンテナ数の監視には、以下のようにクエリを記述します。
SELECT latest(`container_check.running`) FROM ContainerCheck FACET `container_check.targetImage` SINCE 30 MINUTES AGO TIMESERIES
YAMLファイルで指定したイベント名event_type: ContainerCheckをFROM句で指定します。
このイベントから送信される変数名はcontainer_check.targetImageとcontainer_check.runningとしています。
SELECT句に、起動されているコンテナ数を格納しているcontainer_check.runningをlatest(*)で最新値を取得しています。
FACET句を利用することで、特定のパラメータでグルーピングをすることができます。今回は実行中のイメージ名を格納しているcontainer_check.targetImageを指定しています。
RUNボタンでクエリ文をもとにデータを取得して可視化します。docker psコマンドで確認した通り、2つコンテナが起動していることがわかります(図3)。
アラート設定
監視対象のサーバから値が取得できていることがわかりました。それでは、起動中のコンテナの数が0になった際にアラートメールを送信するように設定しましょう。
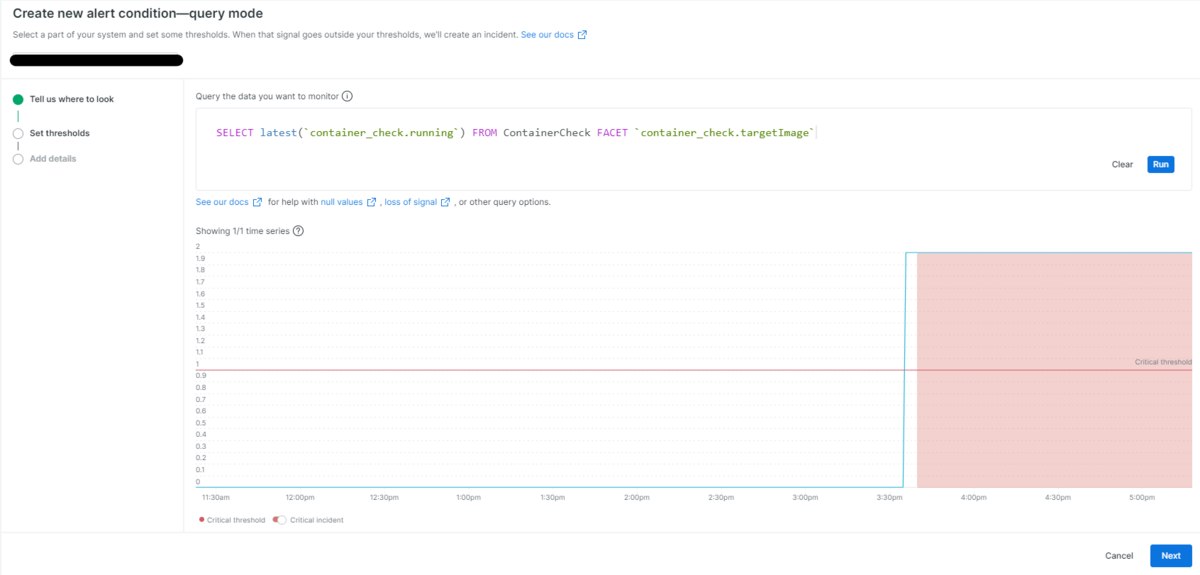
Query builder画面からCreate Alertボタンを選択すると、監視条件の設定を行うCreate new alert condition画面に遷移します(図4)。
監視条件を設定するためには
- 監視対象クエリの設定
- アラートを発報する閾値の設定
- アラート名とポリシー(アラート通知方法)の設定
の3種の設定を行います。
監視対象クエリの設定
監視データの取得元を設定します。先ほどの手順のようにQuery builder画面から遷移した場合、図4のようにクエリ文が引き継がれます。Nextボタンより次の設定項目に移動します。
アラートを発報する閾値を指定
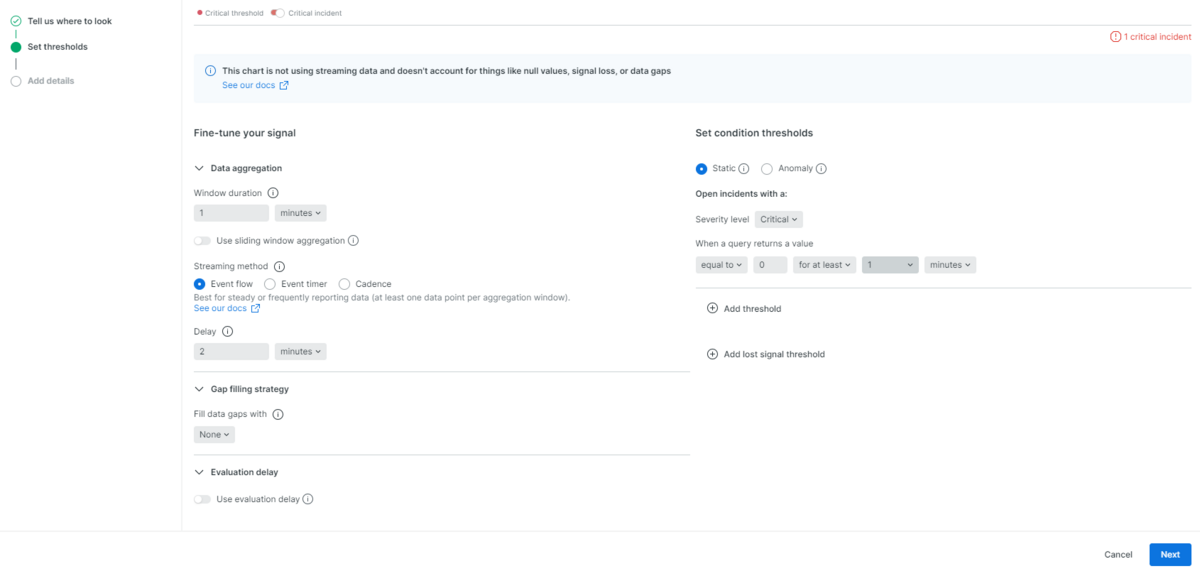
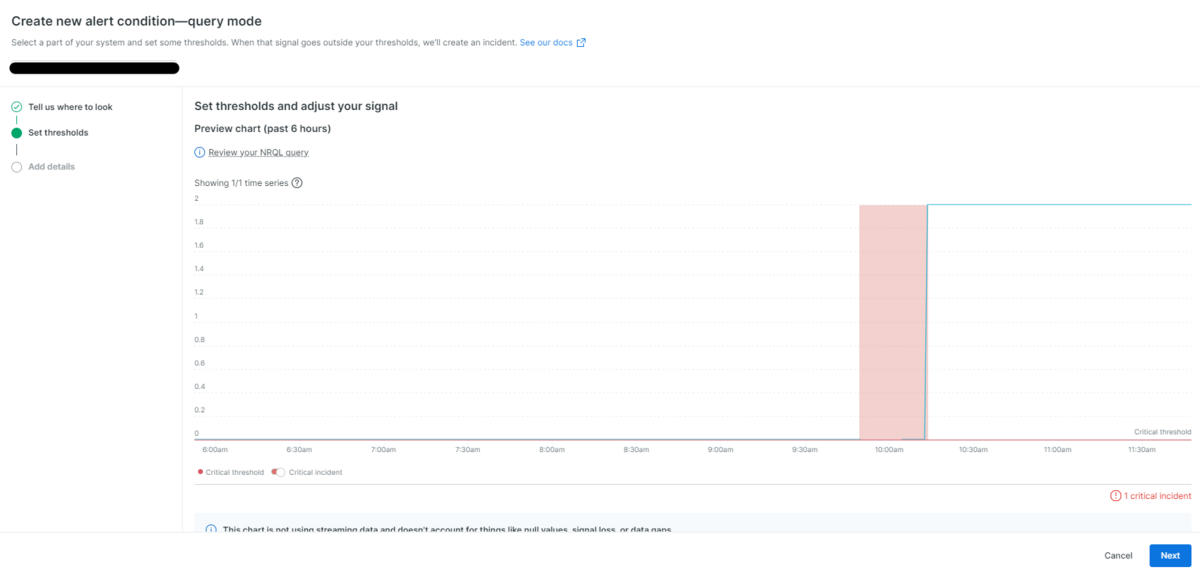
アラートとする状態の閾値を設定します。クエリ文から生成された値とデフォルト閾値のグラフを下にスクロールすることで設定項目が現れます。主な設定項目として以下を設定します。
Window duration: 1 minutes
Delay: 1 minutes
Severity level: Critical
When a query return a value:
equal to 0 for at least 1 minutes
Window durationパラメータでは、設定した窓幅でデータを集約することで、頻繁に上下する値を平滑化することができます。
Delayパラメータでは、データを集約するタイミングに遅延を入れることができます。
Severity levelパラメータでは、次に設定する閾値の重要度を設定できます。
When a query return a valueパラメータでは、実際の閾値を設定できます。
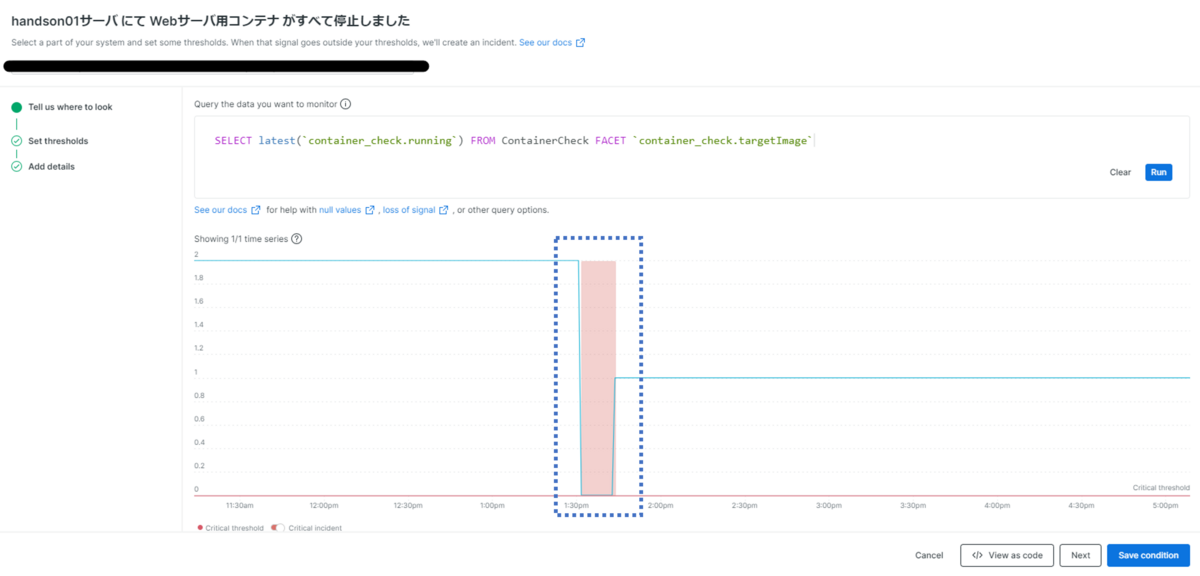
今回は、コンテナ数が0になった状態が1分間続いた場合、致命的な障害として評価するように設定しています(図5)。
NRQLアラート条件に追加された新しい集計方法とどれを選ぶべきかの指針 | New Relic
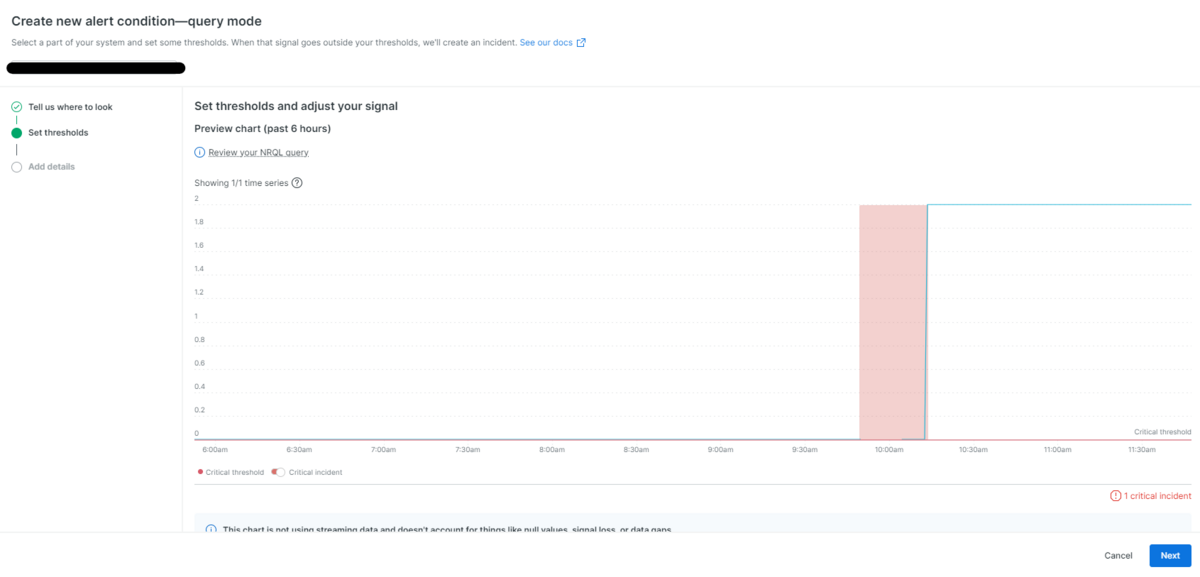
再度上にスクロールすると、設定した閾値が確認できます。赤の網掛けとなっている範囲がアラート発生期間となっています(図6)。
Nextボタンからポリシーの設定に遷移します。
アラート名とポリシー(アラート通知方法)の設定
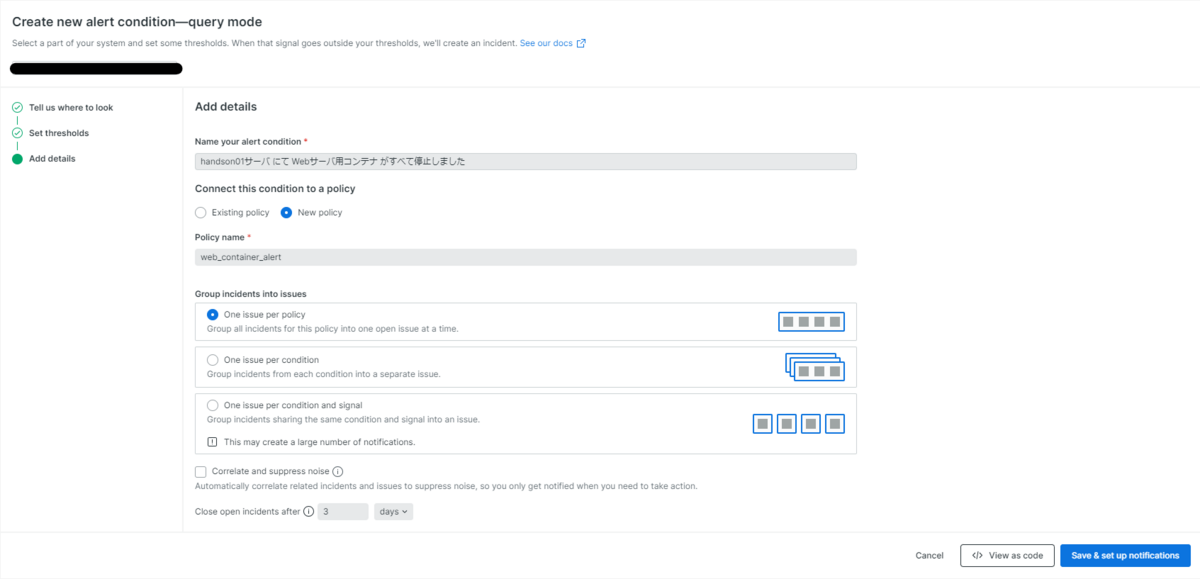
アラートが発報したさいに表示される名前と、通知方法を管理するポリシーを設定します。主な設定項目として以下を設定します(図7)。
Name your alert condition:
handson01サーバ にて Webサーバ用コンテナ がすべて停止しました
Connect this condition to a policy:
New policy
Policy name:
web_container_alert
Save & set up notificationsボタンよりアラート条件の設定を完了します。設定完了後に通知の方法を聞かれるので、Emailを選択します(図8)。
通知してほしいメールアドレスや必要であれば付加情報を入力します(図9)。
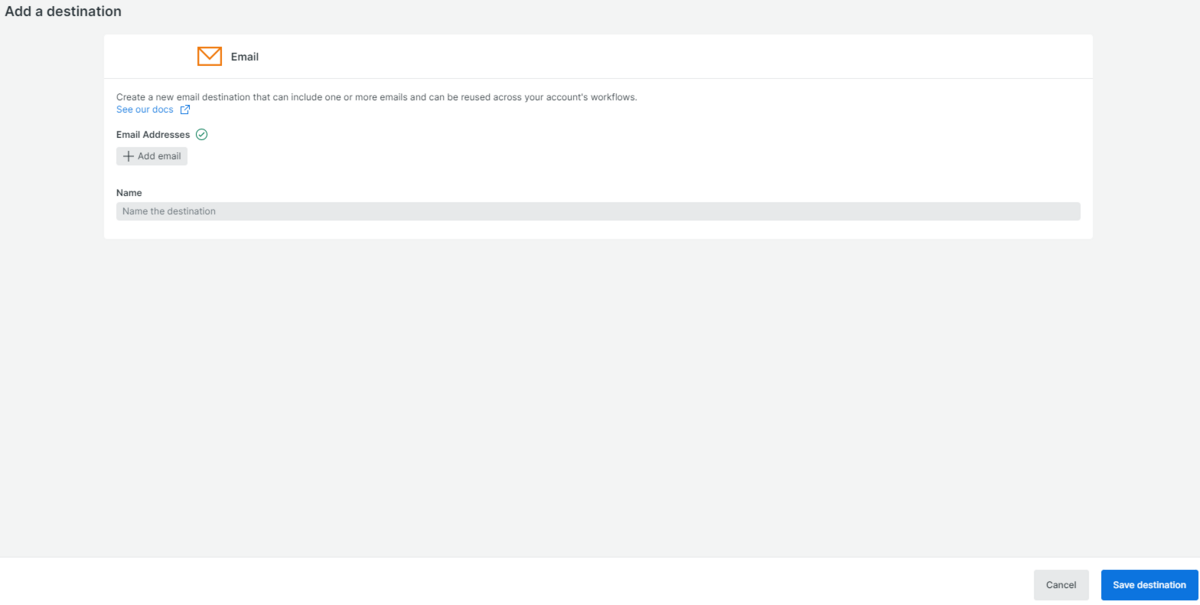
通知先を新規作成する場合は、Email destination欄からCreate new destiationを選択し、Email Addlesses欄からアドレスを追加します。Save disticationボタンより作成します(図10)。
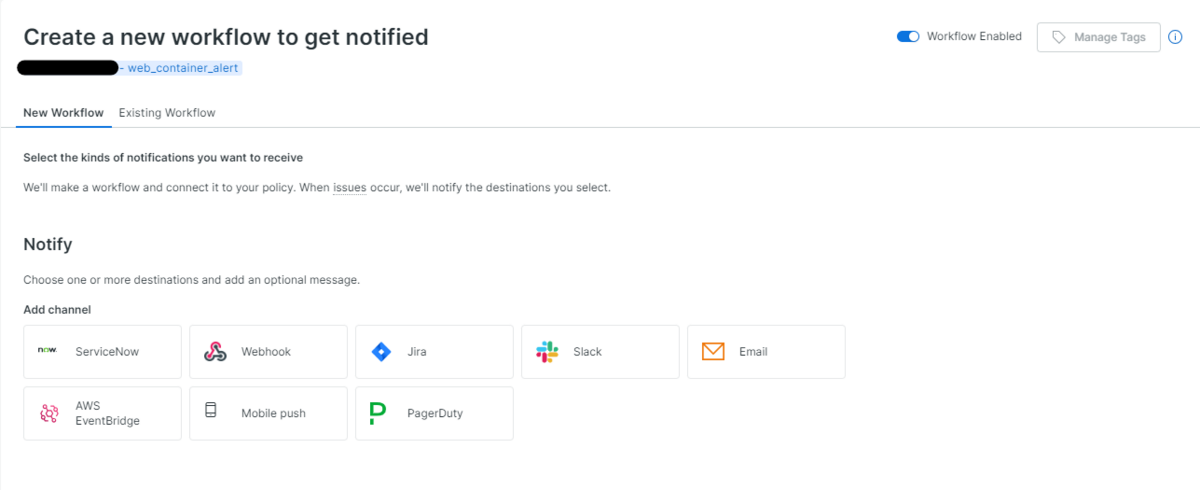
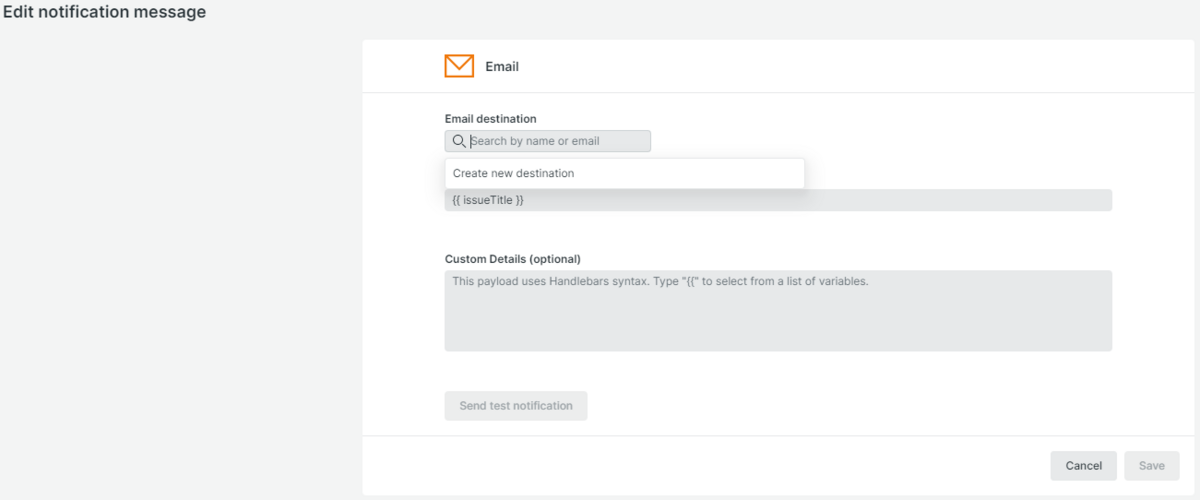
最後に、図8の画面からActivate workflowボタンより、通知先の設定が完了します。
テストと結果
長い道のりを経て、監視設定をすることができましたので、実際にアラートが発報する様子をテストしてみましょう。
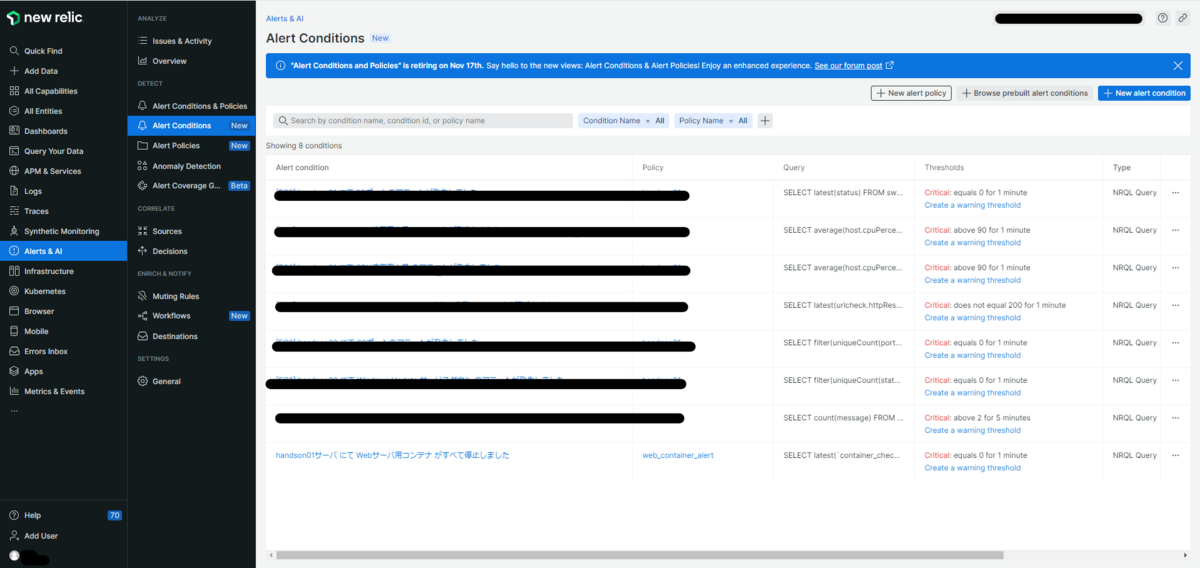
画面左のペインからAlerts&AIからAlert Contidionsを選択すると、作成したアラート設定の一覧を確認できます(図11)。設定をクリックすることで、現在の状態を確認できます。(図12)。
それではここからサーバ上のコンテナを停止して、アラートが発報されるか確かめます。Dockerを実行しているEC2インスタンスにアクセスし、以下のコマンドでDockerを停止します。
# 停止するためにコンテナのID(CONTAINER ID)を確認 docker ps # IDを使って停止(2台分行う) docker stop XXXXXXXXXXXX # 起動中のコンテナが無いか確認 docker ps
ここでコーヒーなど準備しながらしばらく待つと、先ほどの図10の画面のグラフが変化し赤の網掛け表示となり、致命的なアラートとなっていることがわかります(図13 青四角部)。
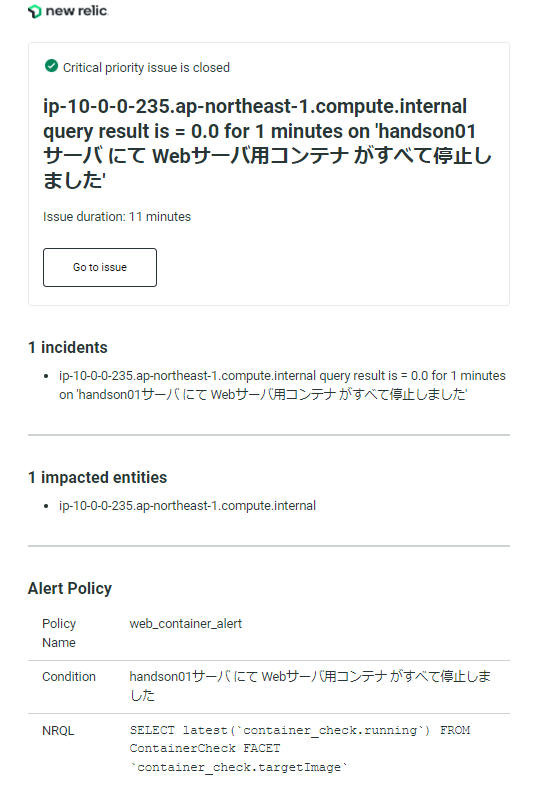
次に、メールも確認してみましょう。通知設定を行ったメールアドレスを確認すると、タイトルに対象のインスタンスと条件、アラート名でメールが届いています(図14)。
アラートが上がることを確認出来たら再度コンテナを起動するなどして、図13のように復旧させましょう。
感想
とても長くなりましたが、以上で今回の検証は終わりです。
これまで、個人で「作る」「動かす」「直す」というサイクルはたくさん経験してきましたが、MS部のOJTでは作ったものを「見守る」という部分を学ぶことができました。作られたシステムをたくさんの人に長く使ってもらうためには、様々なトラブルに対応する必要があります。プログラム上で起こった不具合でも、ユーザ側の操作が停止したりなど、目に見える不具合だと、迅速に修正などの対処が可能です。しかし最適化不足などで、目に見えないところでシステムリソースを消費していく不具合は、実際の動作の上ではなかなか気づきにくいものです。そこで監視ツールなどを導入して、システムが正常な状態を理解することで、違和感をいち早く察知し、対処できるのだなと感じました。
今回の検証では、サーバのCPUやコンテナなどインフラストラクチャ部分の監視でしたが、NewRelicではアプリケーションに特化した監視(Application Performance Monitoring)も可能となっています。まだまだ改善できる部分もあるので、日々試行錯誤を続けていきたいですね。
ここまで読んでいただきありがとうございました。
圡井一磨(執筆記事の一覧)
23年度新卒入社しました。最近は自炊にはまっています。アパートのキッチンが狭くて困ってます。