

カメラマン兼プログラマー(ぶちょお兼取締役談)の竹永です。
カメラのレンズを購入していなかったら、洗濯機が買えていたことに最近気がつきましたが、反省も後悔もしていません。良い子は真似しないでください。
さて、僕の近頃の業務はビッグデータやBIなど、レイヤーが上であっち方向の検証業務が多めです。
検証するためにはあっち系ツールの他に、日頃から発生しているデータをたくさんかき集めないといけませんが、そんなデータをローカルに持っているわけがありません。
ということで、社内と雲の上に転がっている色々なものから、色々なデータをかき集めることにしました。
前提条件
相変わらずEC2上のAmazon Linuxで検証しています。 それぞれのバージョンは以下のとおりです。
- amzn-ami-hvm-2015.09.0.x86_64-gp2 (ami-9a2fb89a)
- Fluentd v2.2.1 (td-agent v0.12.12)
Fluentdと出会うまでの流れ
「Webサーバーからなんかとってこれそう」とあたりが付いたところまでは良かったのですが、自分でスクリプトを書いたりして集めるのは面倒です。ほんとうに。とっても。
なので、どこかで聞いたことがある「つくらないSI」を思い出して、既成品を使うのが一番です。ちょうどFluentdの事を思い出したので、Fluentdと戯れます。
きょうのレシピ
下図のようなイメージで遊び場を作ります。
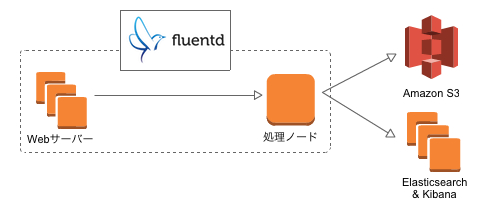
Fluentdだけじゃないのか…
なにやら色々居ますね。
とりあえずそれぞれのサービス(とサーバー)を何に使うのかをご説明します。
なお、今回はFluentdの記事なので、Fluentd以外の中身については扱いません。
Fluentd多くない?
気分で台数が決まります。気まぐれとも言います。
ぶちょおには「Fluentdを突っ込んだEC2 x 2台で色々やりたいんですけど良いですか?」としか言っていませんが、たぶん大丈夫です。たぶん。
今回のFluentd構成は2層(エージェント -> 集約/処理)ですが、本当は3層(送信 -> 集約 -> 処理)まで行くと、スケーリングしやすくなるついでに設定変更しやすくなります。
Fluentdクラスターの設定変更も自動化すれば良い感じに本番環境で使えそうな気がします。
S3
ログ収集ついでにバックアップできたら便利そうだなぁと思って追加してみました。
新しいストレージクラスが追加されていましたが、今回は使いません。
余談ですが、新クラスで自宅のNASをフルバックアップするとお安いです。
もしHDDが全台吹き飛んだ時はデータ取り出し料金がかかります($0.01/GB)が、普段がお安いので大丈夫です。
Elasticsearch + Kibana
なんかかっこいいダッシュボードで、ほぼリアルタイムでグラフが動いてたらかっこいいな、と思って入れました。本当にそれだけです。
クラスタリングし放題なので、利用料金もうなぎのぼりし放題です。
「Amazon Elasticsearch Serviceを使え」という声が聞こえる気がしますが、このブログの検証途中にリリースされたのです。
Elasticsearchをインストールして、Kibanaもインストールして、ついでだからMarvelも入れちゃったぜヒャッハーッ!というところに、全部入りのサービスがポコーンとリリースされました。ありがとうございますこのやろう。
今回はFluentd記事なので特に触れませんが、東京リージョンでも使えますのでお試しあれ。
Fluentdのインストール
さて、ログをぶっこ抜けそうなWebサーバーを探したところ、結局みつからなかったのでAmazon Linux上に自分で立てました。下記のコマンドでインストールできます。
$ sudo yum install httpd -yコーポレートサイトにいきなり仕込む勇気は出ませんでした。こわいこわい。
次に公式提供のワンライナーでFluentdをインストールします。
最後に、データを投げ込む処理ノードにプラグインを入れます。 今回はElasticsearchを使うので、下記コマンドでプラグインをインストールします。
$ sudo td-agent-gem install fluent-plugin-elasticsearchインストールはすぐ終わります。かんたん。
Fluentdの設定
あとは設定ファイル(/etc/td-agent/td-agent.conf)をちょちょいといじくります。 記法自体は簡単ですが、使っているプラグインのドキュメントなどを読まないとさっぱり分かりません。
なので、下記にいじくった結果と簡単な解説を記載します。
Webサーバー側の設定
データを投げ込む側のFluentdの設定は下記のようにしました。
type tail
format apache2
path /var/log/httpd/access_log
tag test.apache.access
pos_file /tmp/fluent/logpos/access_log.pos
types code:integer,size:integer
type forward
name fluent01
host 172.31.6.241
port 24224
| キー名 | 項目の説明 |
|---|---|
| type | ログを読み込む方法を指定します。今回はファイルを tail -f で読む感じの tail を指定します。 |
| format |
読み込んだファイルのフォーマットを指定します。 普段は正規表現で指定しますが、Apache2標準形式のテンプレート的なものがデフォルトで用意されているので apache2 を指定します。 |
| path | ログファイルの場所を指定します。今回は /var/log/httpd/access_log です。 |
| tag | Fluentd内でルーティングを行う際に使うタグを指定します。適当で大丈夫です。 |
| pos_file |
ファイルの最終読み込み位置を記録するファイルのパスを指定します。 必須ではないのですが、指定しないとFluentdが起動していない間のログが丸々欠落します。 記録先のディレクトリは事前に作ってあげてください。 |
| types | 書かなくても動きますが、HTTPステータスコードとコンテンツサイズがStringなのが気に食わなかったので数値にしました。 |
| キー名 | 項目の説明 |
|---|---|
| type | 条件に一致したログをどう扱うかを指定します。今回はforwardを指定して、別のFluentdサーバーに転送するようにします。 |
| キー名 | 項目の説明 |
|---|---|
| name | サーバーの名前を指定します。省略可能ですが、ログに出てくる名前になるので一応つけておきましょう。 |
| host | サーバーのIPアドレスかホスト名を指定します。 |
| port |
サーバーのポート番号を指定します。 省略できますがなんとなく書きました。デフォルトは24224です。 TCPとUDPを使うので、FWに穴を開ける時に気をつけましょう。 |
ちなみに
処理ノード側の設定
次はデータを投げ込まれる側です。
type forward
port 24224
bind 0.0.0.0
type copy
type elasticsearch
host 172.31.6.111
port 9200
type_name access_log
logstash_format true
logstash_prefix test-apache-access
flush_interval 10
type s3
aws_key_id AKIAHOGEEEEEEEE
aws_sec_key SecretkeyHogehogefugafuga
s3_bucket hogehoge-logbucket
s3_region ap-northeast-1
s3_object_key_format %{path}%{time_slice}/%{index}.%{hostname}.%{file_extension}
path access-logs/
buffer_path /tmp/fluent/s3
time_slice_format %Y%m%d-%H
time_slice_wait 10m
utc
format json
include_time_key true
| キー名 | 項目の説明 |
|---|---|
| type | forward と書くだけで転送されたデータを受け取れます。 |
| port | ポート番号は省略できます。番号をよく忘れるので書きました。 |
| bind |
バインドするアドレスも省略できます。 「0.0.0.0って書いておけばいいかな」という軽い感じで書いてます。 |
今回は test.apache.* と一致するタグがくっついていた場合に処理を行うようにします。
| キー名 | 項目の説明 |
|---|---|
| type |
copy を指定することで、その先に続く全部の 標準出力も追加しておくと動作確認に便利かもしれません |
それぞれの
Elasticsearchへのログ転送は type elasticsearch を指定します。
| キー名 | 項目の説明 |
|---|---|
| type |
elasticsearch と指定するとElasticsearchに投げます。 Fluentdのデフォルト状態だとElasticsearchプラグインがインストールされていないので、Elasticsearchにデータを転送したい時はプラグインをインストールしておきましょう。 |
|
host port |
そのまんまです。Elasticsearchに接続するために必要な情報を入れてあげてください。 |
| type_name | RDBMSのテーブル名みたいなものです。他のものと被らない程度に適当につけます。 |
| logstash_format | Logstashっぽい形式でElasticsearchにデータを突っ込むオプションです。データの扱いがちょこっと楽になります。 |
| logstash_prefix |
Elasticsearchに入れる時のIndex名の頭にくっつく名前を設定します。 他のデータとかぶらなければ何をつけても大丈夫です。 |
| flush_interval |
Elasticsearchに書き込む頻度です。 10秒くらいに設定しておけば「リアルタイムで何かみたーい!」という時でも大丈夫です。たぶん。 |
S3への書き込みは type s3 で行えます。
| キー名 | 項目の説明 |
|---|---|
| type |
s3を指定するとS3にログを転送できます。 S3プラグインは同梱されているので特にインストールの必要はありません |
|
aws_key_id aws_sec_key |
いつものやつです。AWS APIの認証情報を記入してください。 インスタンスにIAMロールが設定してある場合は不要です。 |
|
s3_bucket s3_region |
こちらもいつものやつです。 バケット名とリージョンを設定してください。 |
| s3_object_key_format |
保存するパスとファイル名を指定します。 プレースホルダーについては、プラグインのREADMEや、プレースホルダーを使えるようにするプラグインのREADMEを参照してください。 |
| path | プレースホルダーの%{path}に入る文字列を指定します。 |
| buffer_path | S3に上がるファイルを一時格納するパスを入力します。 |
| time_slice_format |
S3にアップロードする区切りを設定します。 今回の設定は1時間毎に1ファイルです。 |
| time_slice_wait |
遅れて届いてきたログ達を待ってあげる時間です。 区切りのいい時間が来て、10分経ってからS3へアップロードします。 |
| utc | ローカルタイムゾーンを無視してUTCで時間を扱う指定です。 |
| format |
出力フォーマットを指定します。 JSONを指定していますが、デフォルト形式は某DWHへのインサートが面倒くさかったのでこれにしています。 |
| include_time_key | 出力形式をJSONにすると時間が記録されないので、時間を含めるようにする設定です。 |
動かしてみる
あとはFluentdを下記のコマンドで起動すれば動き始めます。
$ sudo service td-agent startS3にログが保存され、
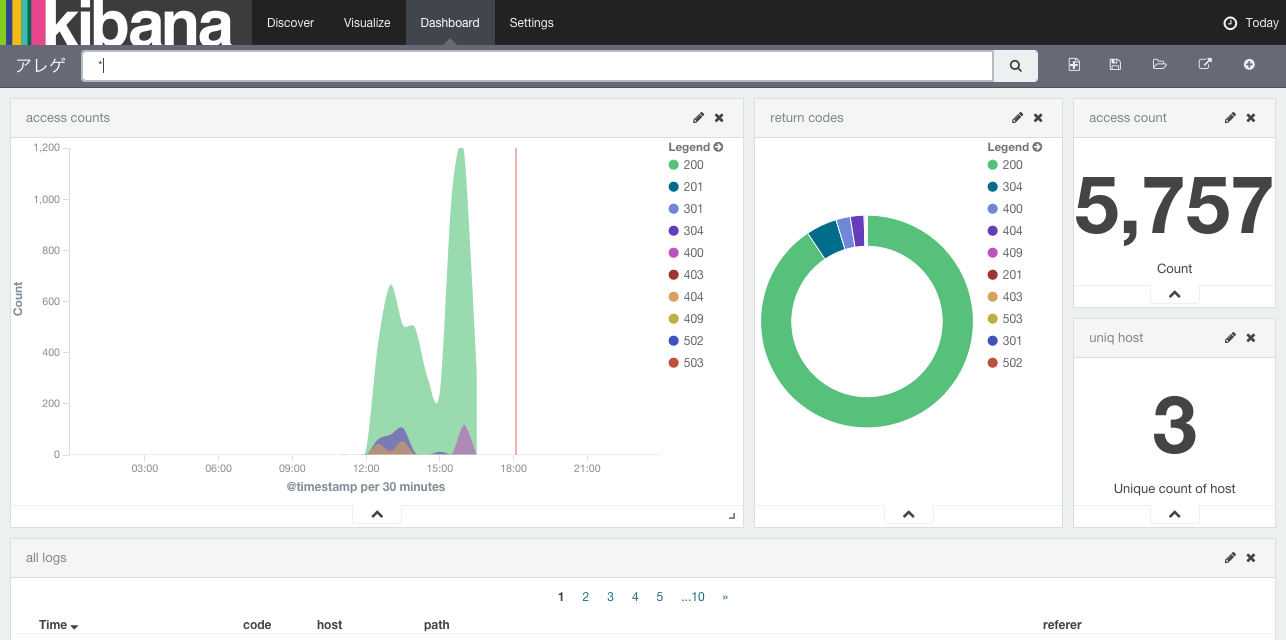
Elasticsearchと一緒にのっけたKibanaで可視化ができます。
おわり。
あら簡単
…これで終わるのも味気がないので、Tipsを書いてみます。
実行ユーザーの変更方法
/etc/init.d/td-agent を見ると分かるのですが、 /etc/sysconfig/td-agent というファイルを作って中身を書くと、サービスの設定をいじれます。
セキュリティ的にダメな例ですが、rootで実行する場合の例はこちら。
TD_AGENT_USER=rootあとは下記のコマンドでFluentdを再起動すれば反映されます。
$ sudo service td-agent restartログ is どこ
ログファイルの出力場所はデフォルトだと /var/log/td-agent/td-agent.log です。
「なんかうごかなーい」という時は大体エラーメッセージが出てるので、ログを元にゴリゴリといじってみましょう。
とはいえ、私の環境でよく出てくるエラーは「ファイル開けねぇぞオラァ(意訳)」と「Elasticsearch繋がらねぇぞオラァ(意訳)」です。
大体は、ファイルパスを間違えていたり、権限が足りていなかったり、インスタンスの起動を忘れていたり、サービスの起動を忘れていたり、セキュリティグループ設定を間違えていたりしています。
設定ファイルの文法を間違えてるときも起動しませんのでご注意を。
次回予告
Amazon Elasticsearch ServiceとFluentdで遊ぶ