

はじめに
4月は花見で酒が飲めるぞ、5月は何で酒が飲めるんだっけ・・・? 技術1課の原です。
昨年発表されたAWS Glue。どんな内容の機能かというと・・・
ということで、サーバーレスでデータの加工ができるというのが肝のようですね。
論より証拠、とりあえず使ってみるばい、と早速使ってみることにしました。
作業その1 抽出
まず、こんな感じの、JSON形式のサンプルデータを大量に用意しました。
{"device": "ExampleDevice", "timestamp": "2018-03-30 08:42:52.420998", "heartrate": 114, "latitude": 35.701783, "longitude": 139.743184, "temperature": 19, "humidity": 63}
device:デバイス名、timestamp:記録時間、heartrate:心拍数、latitude:緯度、longitude:経度、temperature:温度、humidity:湿度、を持った、センサーから送られてきたデータ、という想定です。
これをあらかじめS3に入れておきます。
こんな感じのテキストデータが大量に入っているイメージです。 まずはこのデータを、 AWS Glueの機能のひとつである「クローラー Crawler」を使って、「データを抽出」してやります。
まずはこのデータを、 AWS Glueの機能のひとつである「クローラー Crawler」を使って、「データを抽出」してやります。
具体的には、データベースとテーブルを作成します。
マネジメントコンソールからAWS Glueを開きましょう。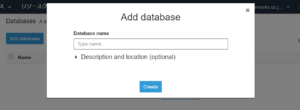 まず、Databasesタブから「Add Database」をクリックし、データベース名を入力してデータベースを作成します。
まず、Databasesタブから「Add Database」をクリックし、データベース名を入力してデータベースを作成します。
次に、 Crawlersタブから「Add Crawler」をクリックし、クローラーの作成に入ります。
まずクローラーの名前を入力します。 先ほどのデータが入っているS3バケットを選択します。パスの最後にスラッシュを入れないと機能しないので気をつけて・・・
先ほどのデータが入っているS3バケットを選択します。パスの最後にスラッシュを入れないと機能しないので気をつけて・・・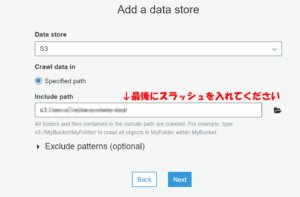 IAMロールを作成します。(以前作成したものがあれば、「choose an existing IAM role」から選択します。)
IAMロールを作成します。(以前作成したものがあれば、「choose an existing IAM role」から選択します。)
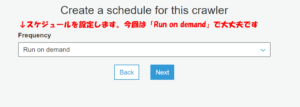 最後に、先ほど作成したデータベースを選択します。
最後に、先ほど作成したデータベースを選択します。
これでS3から自動でデータを取り込むこと = 抽出(Extract)ができました。
確認してみましょう。先ほどのJSON形式のデータは、どうなったでしょうか。
それぞれのパラメータの型は特段設定しなかったのですが、Crawlerの機能で、自動で検知して判断してくれています。
ただ、たとえば今回のだと"timestamp" のパラメータはtimestamp型を想定していましたが、ここではstring型として判定されてしまっていますね。
もし手動で想定通りの型を指定したい場合は、Databases→Tables→Add Tablesから、「Add Table Manually」を選択すると、ひとつひとつのカラムの型を手動で指定することができます。
作業その2 加工
次に、ETLのT、データのTransform=加工をやってみましょう。
ここでは、次の2つの加工をやってみることにします。
1・データの項目を、7つから"humidity"と"temperature"の2つに削減する
2・"humidity"の各値ごとに、"temperature"の平均値を取る
さらに、こうやって加工したデータを、ETLのL、ロードしてみましょう。
今回は簡便に、別のS3にデータを吐き出すだけにしておきます。
さて、まず、AWS Glueのコンソールから、Jobsタブの「Add job」をクリックし、ジョブの作成を始めます。
Job名を適当に設定し、IAM roleには先ほど作成したIAMロールを設定、
「S3 path where the script is stored」には実行スクリプトを入れるS3のバケットを、
「Temporary directory」には実行ログを入れるS3のバケットを入力します。 data sourcesには先ほど作成したテーブルを入力します。
data sourcesには先ほど作成したテーブルを入力します。 今回は加工したデータをS3バケットに入れるので、Data storeには、S3を選択。
今回は加工したデータをS3バケットに入れるので、Data storeには、S3を選択。
今回のデータはFormatがJSONですのでそれを入力し、Target Pathには加工したデータを入れる方のS3バケットのパスを入力します。 するとこのような画面が出て来ますので、使わないデータのところを削除します。
するとこのような画面が出て来ますので、使わないデータのところを削除します。 今回は、"humidity"と"temperature"だけを残しましょう。
今回は、"humidity"と"temperature"だけを残しましょう。 このあとの確認ページでFinishをクリックすると、Glueの方である程度自動でコード生成をしてくれます。
このあとの確認ページでFinishをクリックすると、Glueの方である程度自動でコード生成をしてくれます。
今回は、平均を取るという加工を行いたいので、Glueが自動で作成してくれたコードを元に、一部改変して使おうと思います。
自動生成コードに、データ加工のコードを加えて書いたコードが以下になります。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame, DynamicFrameWriter
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [database = "データベース名", table_name = "テーブル名", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "データベース名", table_name = "テーブル名", transformation_ctx = "datasource0")
## @type: ApplyMapping
## @args: [mapping = [("temperature", "int", "temperature", "int"), ("humidity", "int", "humidity", "int")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("temperature", "int", "temperature", "int"), ("humidity", "int", "humidity", "int")], transformation_ctx = "applymapping1")
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://データ送信先のS3バケット名"}, format = "json", transformation_ctx = "datasink2"]
## @return: datasink2
## @inputs: [frame = applymapping1]
df = applymapping1.toDF()
df = df.groupBy(df['humidity']).avg('temperature')
dyf = DynamicFrame.fromDF(df, glueContext, 'テーブル名')
datasink2 = glueContext.write_dynamic_frame.from_options(frame = dyf, connection_type = "s3", connection_options = {"path": "s3://データ送信先のS3バケット名"}, format = "json", transformation_ctx = "datasink2")
job.commit()
あとは、Run Jobをクリックして、ジョブを実行します。
実行結果
さて、どのようになったでしょうか。
保存先のS3を覗いてみましょう。 なんか空ファイルが大量に生成されている・・・
なんか空ファイルが大量に生成されている・・・
けど、ちゃんと中身が入ってるファイルもありますね、開いてみましょう。 お、ちゃんと加工されている!
お、ちゃんと加工されている!
湿度43%のときの平均気温が22度、というデータになっていますね。
他も確認してみたところ、バラバラのファイルになってはいますが、それぞれの湿度のときの平均気温がちゃんとデータとして出力されていました。
おわりに
ということで、ETLサービスであるAWS Glueを使ってE→T→Lの行程を一通り行うことができました。
データを加工するのには色々使えそうですね!
また他の作業でも試してみたいと思います。
以上でしたー。