

みなさん、こんにちは。
新規開発チームの小田切です。
最近は、仕事の合間にいろいろ検証を行ったりしているのですが、その中で見つけた「SSD Hot S3 Coldパターン」という物があり、気になったので、検証を行ってみました。
「SSD Hot S3 Coldパターン」は簡単にいうと、『SSD(DynamoDB)はストレージ料金がそれなりに高いから、使わないデータは価格の安いS3に移動させちゃいましょう』というパターンです。
イメージは以下のような感じになると思います。
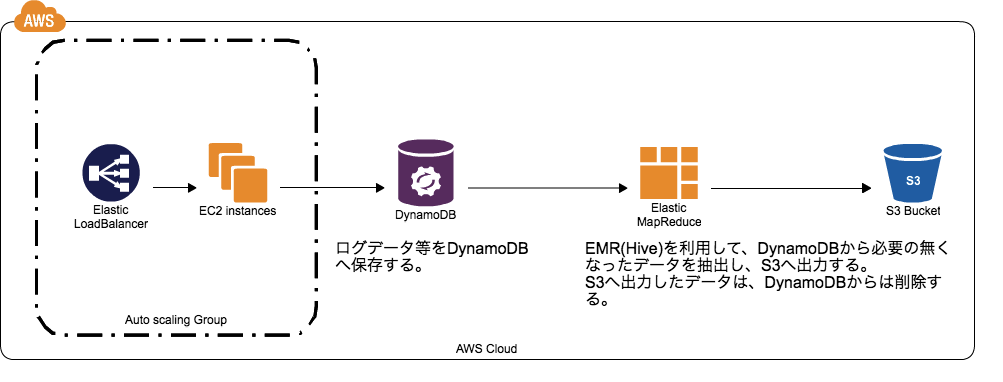
ここで活躍するのが、DynamoDBとS3をつなぐ事の出来るEMR(Hive)です。
Dynamoには、すでにデータが入っている状態として話を進めて行きます。
EMRのJobFlowを作成する
まずは、EMRのJobFlowを作成し、HadoopとHiveのインストールされているインスタンスを作成する必要があります。
AWSのManagementConsoleから「Elastic MapReduce」を選択します。
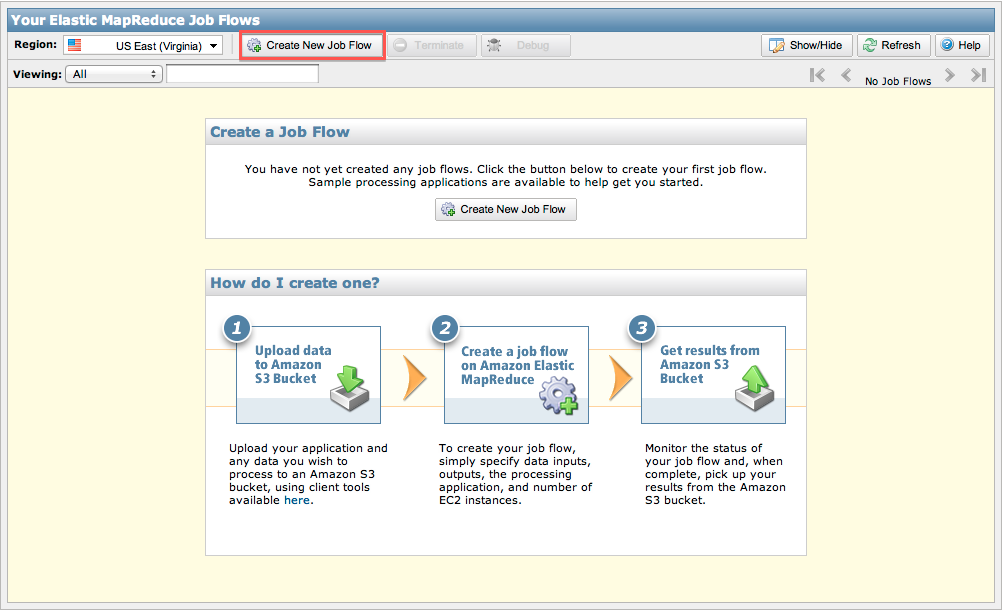
上記の画面が表示されますので、「Create New Job Flow」をクリックします。リージョンは適宜選択してください。
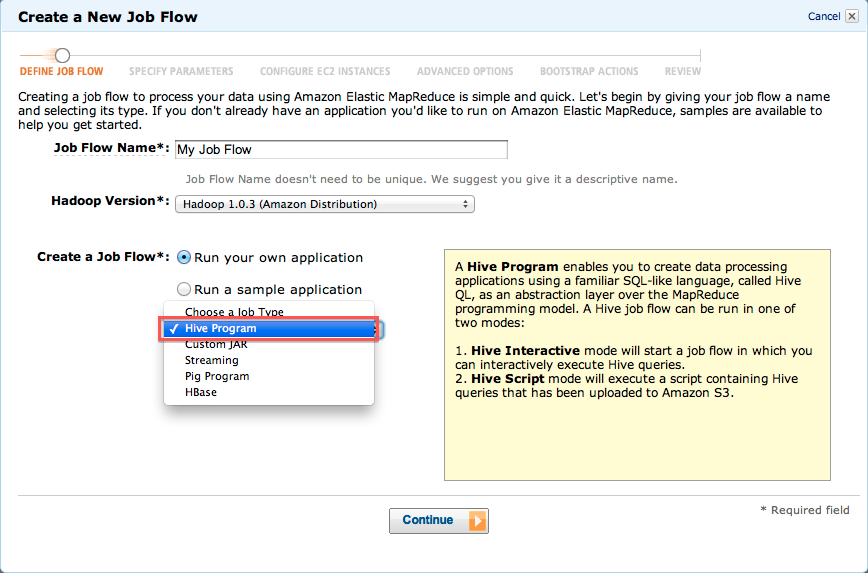
EMRのJob Flowを作成するウィザードが表示されます。
ここでは、ジョブフローの名前と、Hadoopのバージョン、ジョブフローの種類を入力します。
ジョブフロー名は適当な名前をつけて頂き、「Choose a Job Type」のドロップダウンボックスで"Hive Program"を選択します。
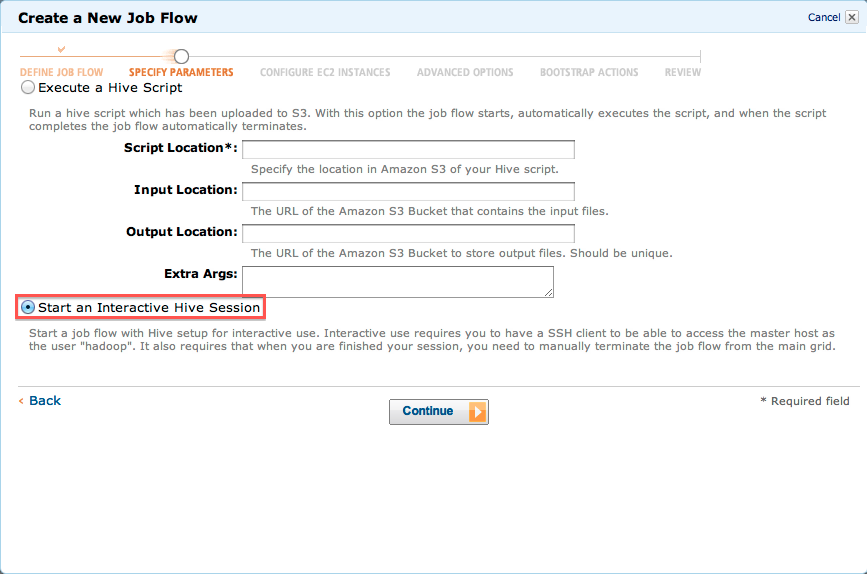
次の画面では、「Start an Interactive Hive Session」にチェックをします。これで、Hiveに対して対話形式でSQLを実行する事が出来るようになります。
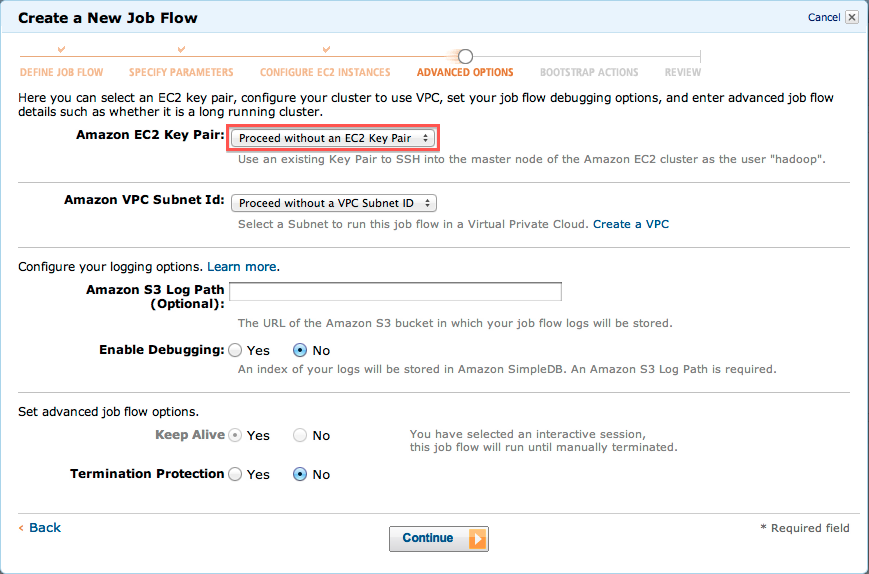
次の画面では、HadoopのMasterサーバへSSHでログインする際に私用するキーペアを指定します。
キーペアを作成されていない方は、先にキーペアを作成しておいてください。
あとは、デフォルトのまま「Continue」をクリックして行き、JobFlowの作成を完了します。
MasterサーバへSSHでログインする。
Job Flowの作成が完了し、少し待ちますと、Master・Slaveサーバのインスタンスが起動します。
ManagementConsoleで先ほど作成したJobを選択しますと、画面下に各設定内容が表示されます。
その中から「Description」より「Master Public DNS Name」を確認します。
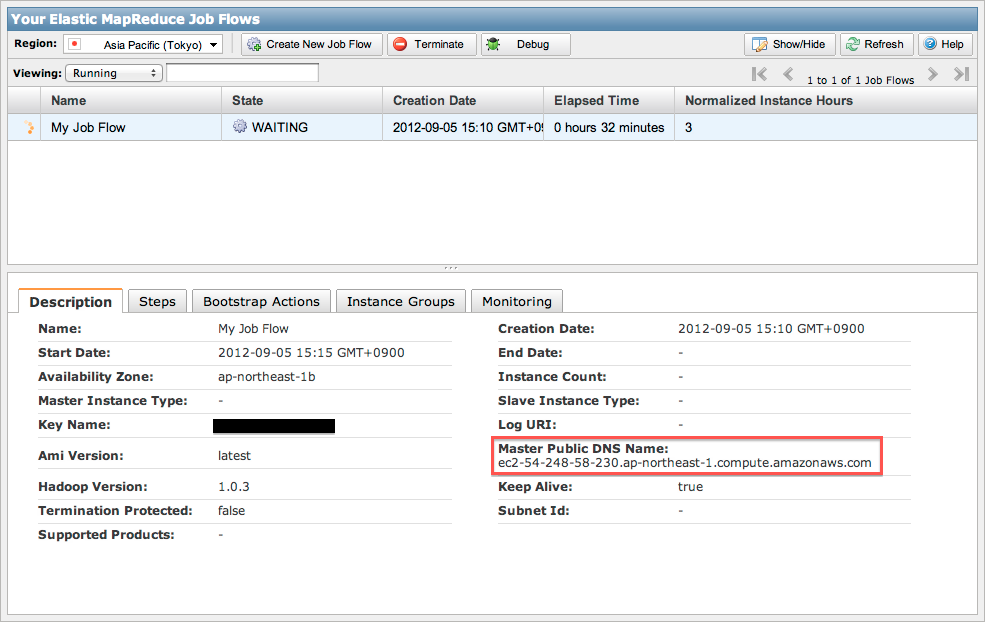
ここで表示されたサーバへ、SSHでログインを行います。その際使用するキーはJob Flow作成時に指定した鍵を使用します。
また、ログインする際のユーザはhadoopユーザとなります。
各種コンソールから以下コマンドにて、サーバへログインします。(サーバ名、使用する鍵は各自の設定に合わせてください。)
ssh hadoop@ec2-54-248-58-230.ap-northeast-1.compute.amazonaws.com -i ~/foo.pem
Hiveを使用して、DynamoDBからS3へデータをエクスポートする
まずは、Hiveを起動します。
コンソールから
hive
と入力し、enterしますと、Hiveとの対話式のコンソールが起動します。(なお、ここで実行するコマンドはHiveQLと呼ばれるSQLライクな言語です。)
おそらく、みなさん東京リージョンを使っていると思われますので、以下コマンドでDynamoDBのEndPointを設定します。
SET dynamodb.endpoint=dynamodb.ap-northeast-1.amazonaws.com;
次からいよいよDynamoDBとHiveのテーブルの連携を行います。
CREATE EXTERNAL TABLE hiveTableName (col1 string, col2 bigint)
STORED BY 'org.apache.hadoop.hive.dynamodb.DynamoDBStorageHandler'
TBLPROPERTIES ("dynamodb.table.name" = "DynamoDBTableName",
"dynamodb.column.mapping" = "col1:name,col2:year");
上記コマンドは、Hiveのテーブルを作成するコマンドです。
1行目では、"hiveTableName"というテーブルを作成し、カラムはcol1とcol2があるという事を宣言しています。
2行目で、このテーブルはDynamoDBからデータを取得する事を宣言しています。
3行目では、データの取得するDynamoDBのテーブル名を指定しています。
4行目で、Hiveのテーブルのカラムと、DynamoDBのカラムのマッピングを設定しています。
これで、DynamoDBとHiveの連携が出来ましたので、後は、データをS3へ出力します。
S3への出力は以下のコマンドを実行します。
INSERT OVERWRITE DIRECTORY 's3://[バケット名]/fromHive/' SELECT * FROM hiveTableName;
コマンドを実行しますと、Map&Reduce処理が実行されて行きます。処理が完了しますと指定したS3のバケットのディレクトリへ、TSV形式でファイルが出力されています。
ここでは、全件をS3へ出力するようにしていますが、実際には何かしらに条件を付けてHiveQLを実行する事になると思います。
後は、必要の無くなったデータをDynamoDBから削除すれば『SSD Hot S3 Coldパターン』は完了です。
DynamoDBのデータはHiveからは削除できませんので、他の方法(JavaのAWS SDKを利用して削除する等)で削除します。
また、S3に置いてあるファイルをHiveのテーブルと関連づける事も可能です。そうする事で、DynamoDBのデータとS3に移動したデータの両方を利用して解析を行う事も可能です。
最後に
『SSD Hot S3 Coldパターン』は、DynamoDBから、よりコストの低いS3へ、必要の無いデータは移動し、AWS使用料を抑えましょうというパターンで、このパターン自体も非常に参考になったのですが、それ以上に、DynamoDBとEMR(Hive)、S3とEMR(Hive)の親和性の高さが面白いなと感じました。
これを利用すれば、DynamoDBのテーブルをHive上でJoinしたり、DynamoDBのテーブルとS3のデータをJoinしたりする事も出来てしまいます。
今まで仕事でEMRを使用する事が無かったので、そこまでEMR関連のドキュメントとかもしっかり見てなかったのですが、最近EMRはまってきています。
今後もEMRは追いかけて行こうと思っていますので、何か面白い使い方とかありましたらここで紹介して行きます。