

SRE2課の島村です。 梅雨の時期になりました。
皆さんは雨の日はどうやって過ごしていますか。 私はアウトドアの趣味が多く、インドアの趣味と言えるものがないことに気がつきました。 なので、もっぱら自重筋トレをしています。目指せロック様。
さて、今回はSystems Manager(以下SSMと略します。)のインベントリデータを QuickSightで視覚化するところまでやってみたいと思います。
まずは本ブログのターゲットとゴールを記載します。
ターゲット
・SSM インベントリの大体の機能を知りたい ・インベントリデータをQuickSightで可視化できるのは知ってるけど具体的な手順がわからない
ゴール
・Inventoryデータを視覚化できるまでの手順を知る
ターゲットとゴールが確認できたら作成する環境を確認していきます。
構成
今回作成する構成は以下の通りです。
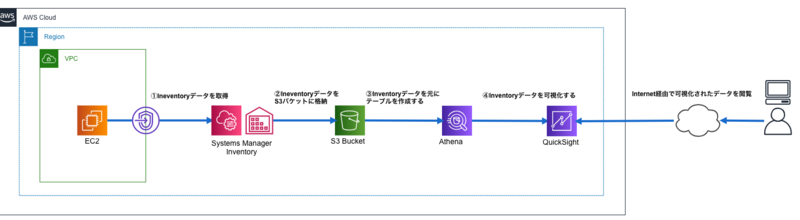
余談となりますが、マルチアカウント構成の場合は、全てのアカウントのインベントリデータを特定アカウントのS3バケットへ集約することで一元管理をすることが可能です。
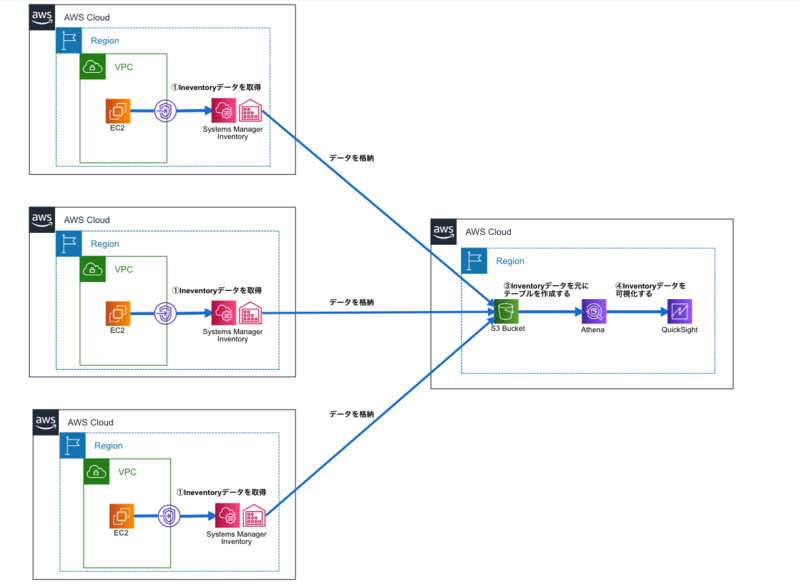
前提
また、前提として以下の作業は実施済みの状態で進めます。 ・AWS SystemsManagerのインベントリ情報が取得できている状態 ・S3バケットを作成しておくこと(バケットポリシー含む) ・AWS CLIを使用して自身の環境へアクセスが可能なこと(今回IAM権限の解説は含んでいません。)
目次
本ブログの構成は以下の通りです。 1.概要 2.SSM Inventoryデータの同期設定 3.Athenaでテーブル作成 4.QuickSightでInventoryデータの可視化
それでは進めていきましょう。
1.概要
さて、早速ですが、SSMインベントリという機能はどのようなものでしょうか。
公式ドキュメントを見てみましょう。
SSM インベントリはマネージドインスタンスからメタデータを取得し、 可視化することでソフトウェアの更新が必要なインスタンスなどを特定できると記載があります。
補足するとマネージドインスタンスとはSSMを使用できるよう設定されているマシンのことです。 AWS上のインスタンス(Linux,Windowsどちらも対応)だけでなく、オンプレミス環境のサーバや、Raspberry Piデバイスなども対応できます。
マネージドインスタンスの詳細については以下をご参照ください。 https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/managed_instances.html
ちなみに前述の説明では"メタデータの取得”とありましたが、実際にどのようなデータが メタデータとして取得できるのでしょうか。表にまとめてみました。
| メタデータ | 取得できるデータ |
|---|---|
| アプリケーション | アプリケーション名、発行元、バージョンなど |
| AWS コンポーネント | EC2 ドライバ、エージェント、バージョンなど |
| ファイル | 名前、サイズ、バージョン、インストール日、変更および最新アクセス時間など |
| ネットワーク設定の詳細 | IP アドレス、MAC アドレス、DNS、ゲートウェイ、サブネットマスクなど |
| Windows Update | Hotfix ID、インストール者、インストール日など |
| インスタンスの詳細 | システム名、オペレーティングシステム (OS) 名、OS バージョン、最終起動、DNS、ドメイン、ワークグループ、OS アーキテクチャなど |
| サービス | 名前、表示名、ステータス、依存サービス、サービスのタイプ、起動タイプなど |
| タグ | インスタンスに割り当てられるタグ |
| Windows レジストリ | レジストリキーのパス、値の名前、値タイプ |
| Windows ロール | 名前、表示名、パス、機能タイプ、インストール日など |
加えて、カスタムインベントリ機能を使用してユーザで定義した情報をメタデータに含ませることができる機能も存在しています。 今回はブログでは取りあげませんが、興味があるかたは以下のドキュメントを参照ください。 https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/sysman-inventory-custom.html
ちなみに、マネージドインスタンスからインベントリデータが正しく情報を取得できていると以下のように可視化されます。
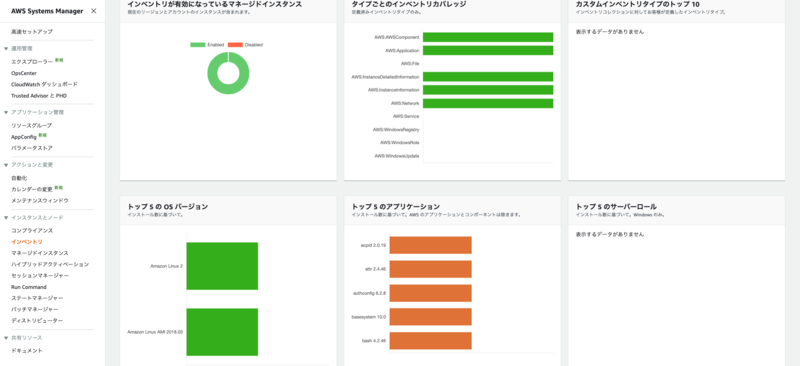
様々な種類のデータが取得できることができますね。 特にアプリケーションのメタデータはセキュリティポリシー上インストール済みであるべきソフトウェアのバージョンが最新か、EC2にインストールできているか、確認する場合など使用するケースは多そうです。
なお、今回はご紹介しませんが、AWS ConfigのConfig Rulesと連携して特定のアプリケーションがインストールされていないインスタンスを検知することが可能です。
2.SSM インベントリデータの同期設定
ここからは実際に設定を行っていきます。
まず、インベントリデータをS3へ格納するために同期設定を行います。 マネージドコンソール、AWS CLIどちらでも設定可能ですので、どちらも手順を記載します。
マネージドコンソールの場合
SSM マネージドコンソールを開いたら、左ペインにある[インベントリ]を選択し、[リソースデータの同期の作成]を押します。
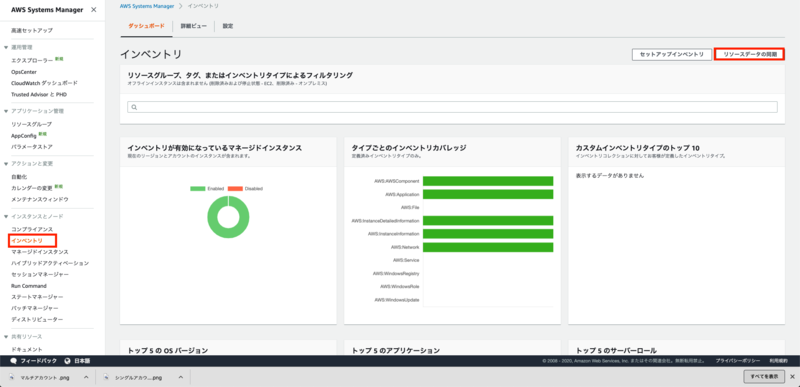
入力画面が出てきます。 以下の通り入力してみてください。
同期名 = 任意の値 S3バケット名 = インベントリデータを格納するS3バケットを指定します。 バケットのリージョン = バケットが存在しているリージョンを選択してください。
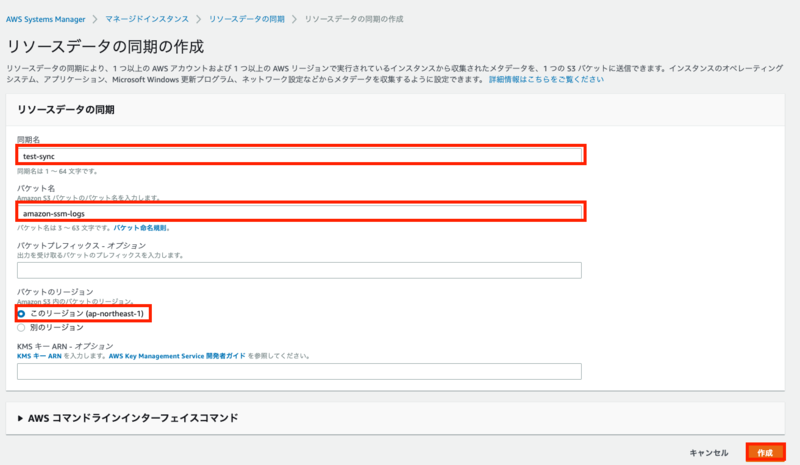
入力を終えたら、[作成]を押してください。

画面が遷移して作成されていることが確認できました。 マネージドコンソールからの設定画面は以上です。
AWS CLIの場合
以下のコマンドで同期設定が作成可能です。 ただし、"sync-name"と"BucketName"は自身の環境のものに置き換えて実行してください。
aws ssm create-resource-data-sync --sync-name "任意の名前" --s3-destination '{"BucketName":"S3バケット名","Prefix":"undefined(あれば入力なければ"undefined"のまま)","Region":"ap-northeast-1","SyncFormat":"JsonSerDe"}' --region ap-northeast-1
同期設定が完了したので、次のステップに進みます。
3.Amazon Athenaでデータベース/テーブルの作成
S3に格納されたインベントリデータを使用して、Amazon Athenaでデータベースとテーブル作成を行っていきます。
まずは、Athenaのマネージドコンソールへ移動します。 移動したらクエリエディターが右ペインに表示されていると思います。
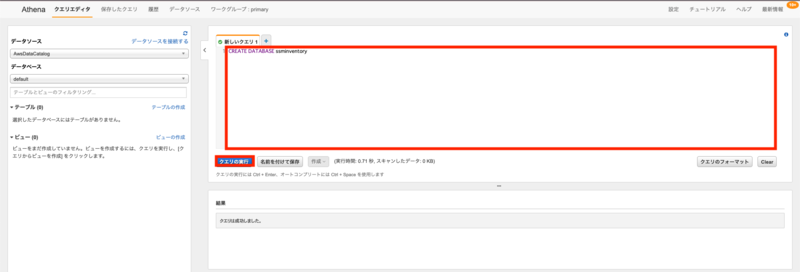
データベースの作成
クエリエディターに以下の通り、データベースを作成するクエリを実行します。 データベース名は任意で構いません。
CREATE DATABASE ssminventory
外部テーブルの作成
次に、外部テーブルを作成します。 データベース名と、S3ロケーションはご自身の環境に置き換えてください。
CREATE EXTERNAL TABLE IF NOT EXISTS データベース名.AWS_Application (
Name string,
ApplicationType string,
Publisher string,
Version string,
InstalledTime string,
Architecture string,
URL string,
Summary string,
PackageId string
)
PARTITIONED BY (AccountId string, Region string, ResourceType string)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1'
) LOCATION 's3://bucket-name/bucket-prefix/AWS:Application/'
このクエリで作られたテーブルはパーティション化されています。 パーティション化されているテーブルの場合、カタログ内のメタデータとファイルシステムのデータレイアウトの整合性が取れなくなります。 これを防ぐために新しいパーティションに関する情報をカタログに追加するクエリを実行します。
MSCK REPAIR TABLE データベース名.AWS_Application
次のステップに進みます。
4.Amazon QuickSightでInventoryデータの可視化
最後のステップです。
QuickSightアカウントの作成
Amazon QuickSightでインベントリデータの可視化していきます。 マネージドコンソールからQuickSightにアクセスします。
アクセスして、QuickSightをまだサブスクライブ していないアカウントである場合は次のような画面に遷移します。 すかさず、[sign up for Quicksight]を押しましょう。
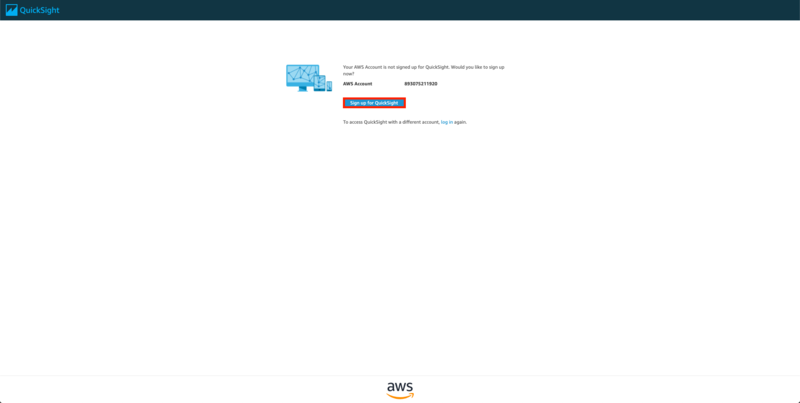
画面が遷移しました。 QuickSightのプラン選択の画面が表示されていると思います。 今回は[Standard]を選択しましょう。

アカウント作成画面に遷移しました。 以下の項目を入力していきましょう。 指定がないものはデフォルトの値で問題ありません。
リージョン = 東京
QuickSightアカウント名 = 任意
通知先のEメールアドレス = 任意
Amazon Athena = チェックを入れる
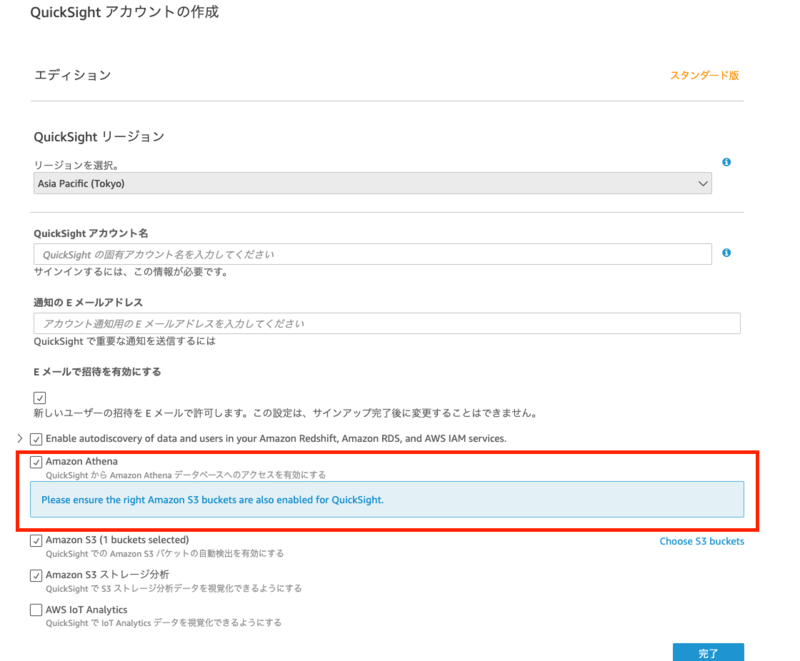
値を入れたらアカウントを作成します。 無事完了すると、アカウント作成画面が表示されます。
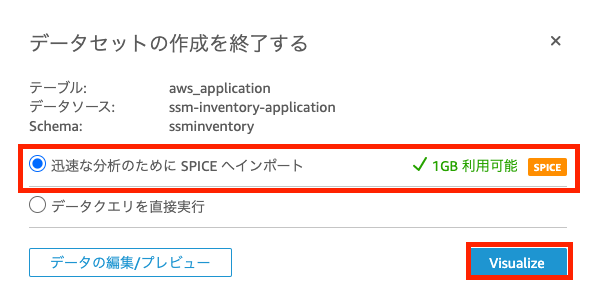
データセットの作成
 サインインすると表示可能な分析がありませんと表示されていますが正しい状態です。安心しましょう。
右上にある[データの管理]を選択します。
サインインすると表示可能な分析がありませんと表示されていますが正しい状態です。安心しましょう。
右上にある[データの管理]を選択します。

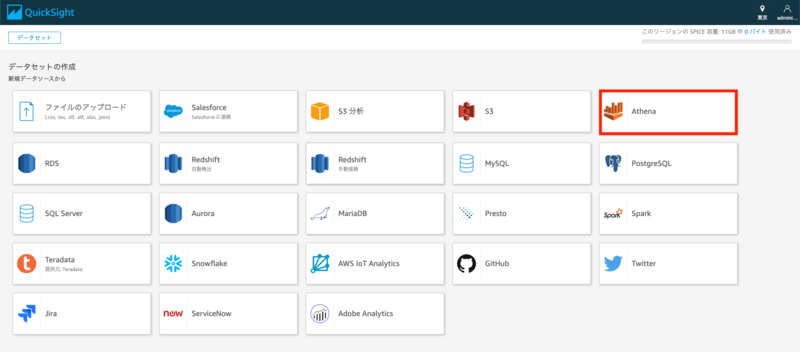
選択後、左上にある[新しいデータセット]を選択してください。

様々なデータソースが表示されます。今回はAthenaを選択しましょう。
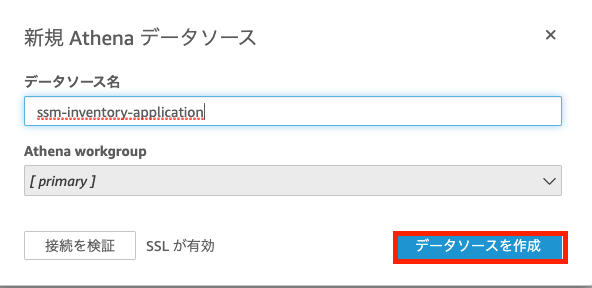
データソース名を入力します。この値は任意の値で問題ありません。
次にデータソースとなるAthenaのデータベースとテーブルを選択する画面が表示されます。 今回作成したAthenaのデータベースとテーブルを選択しましょう。
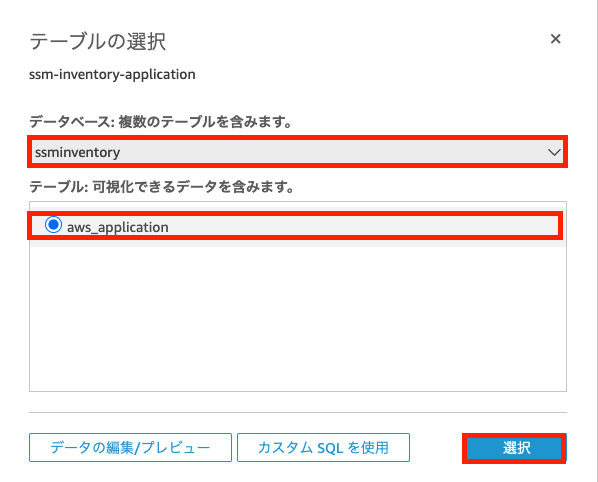
データセットから可視化する
QuickSightのSPICEという機能を使用するか、自前でクエリを書いて データを取得してくることが可能です。
今回はSPICEへデータをインポートしましょう。
ちなみに、SPICEは略称で正式名称は以下の通りです。 Super-fast, Parallel, In-memory Calculation Engine(超高速並列インメモリ計算エンジン)
ネイティブな英語の発音で聞いてみたいですね。(絶対かっこいい) 私は香辛料のSPICEかと思いました。全くの見当違いです。
このSPICEにデータをインポートするとデータソースに直接クエリを実行するわけではないので 可視化の時間を短縮することができます。
SPICEの詳細をより知りたいという方は以下のドキュメントご参照ください。 https://docs.aws.amazon.com/ja_jp/quicksight/latest/user/managing-spice-capacity.html
[Vizualize]を押すとインベントリデータが可視化することができました!
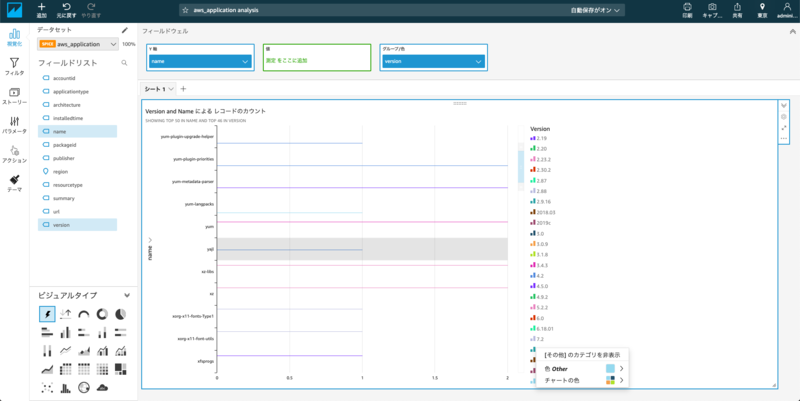
見にくいですが、アプリケーションのインストール日時やバージョン情報などなど表示することが可能です。
最後に
いかがでしたでしょうか。 今回は簡単にインベントリデータのアプリケーションのみを可視化してみました。
マルチアカウント環境やインスタンス台数が多い環境で全インスタンス状態の 必要な情報をサマリーする必要がある際に有効的だと感じました。
島村 輝 (Shimamura Hikaru) 記事一覧はコチラ
最近ECS周りをキャッチアップ中。趣味は車・バイク全般。
一応、AWS12冠です。