

技術課の森です。
今回は、2つのCSVに対して、クエリを発行して、一覧を表示したいと思い、やったことを書いてみます。
はじめに
今回使うAWSリソースはS3とAthenaの2つ。
S3にあるファイルを基に、Athenaでテーブルを作成して、クエリを発行する感じです。
準備編
S3バケットを作る
Athenaでテーブルを作成する際に、S3のバケットを指定することができます。
そのバケット配下にCSVファイルを配置します。
S3の画面からバケットを作成してください。
ここでは、「swx-daikimori-csv」とします。
S3バケットにファイルをアップロードする
クエリを投げたいCSVファイルを作成したバケットにアップロードします。 今回は例として、以下の2つのCSVファイルを使います。
ユーザ情報
"Id","Name","CreatedDate" "ABC001","森 大樹","2017/07/05 12:00:00" "ABC002","もり だいき","2017/07/06 13:00:01"
利用金額データ
"Id","UsedDate","Cost" "ABC001","2018/07/01 09:00:00","2000" "ABC001","2018/07/02 13:00:00","1500" "ABC001","2018/07/03 16:00:00","310" "ABC001","2018/07/04 11:00:00","5000" "ABC002","2018/07/02 09:00:00","2200" "ABC002","2018/07/04 13:00:00","1920" "ABC002","2018/07/05 16:00:00","150" "ABC002","2018/07/07 11:00:00","30000"
Athenaでテーブルを作成
次に、Athenaでテーブルを作成します。
今回は直接クエリを発行してテーブルを作成するようにします。
以下の図の「+」マークをクリックしてください。
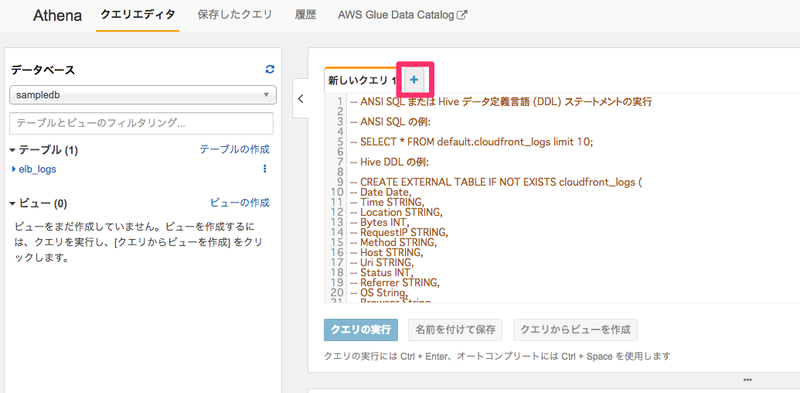
すると以下のようになります。
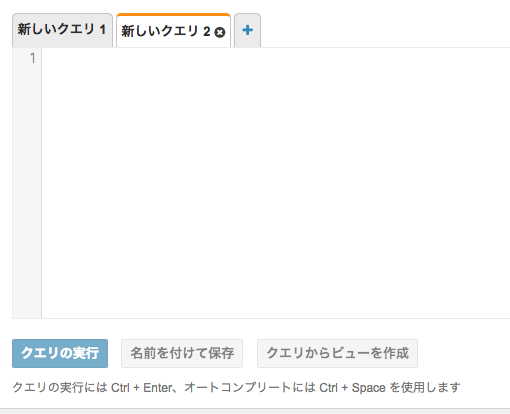 ここにDDLを書いていきます。このDDLを実行すれば準備は完了です。
まずはユーザ情報
ここにDDLを書いていきます。このDDLを実行すれば準備は完了です。
まずはユーザ情報
CREATE EXTERNAL TABLE IF NOT EXISTS default.UserInfo ( `Id` string, `Name` string, `CreateDate` string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( 'escapeChar'='\\', 'quoteChar'='\"', 'serialization.format' = ',', 'field.delim' = ',' ) LOCATION 's3://swx-daikimori-csv/UserInfo' TBLPROPERTIES ( 'has_encrypted_data'='false', 'skip.header.line.count'='1' );
次に利用金額データ
CREATE EXTERNAL TABLE IF NOT EXISTS default.UsedMoneyData ( `UserId` string, `UsedDate` string, `Cost` int ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( 'escapeChar'='\\', 'quoteChar'='\"', 'serialization.format' = ',', 'field.delim' = ',' ) LOCATION 's3://swx-daikimori-csv/UsedMoneyData' TBLPROPERTIES ( 'has_encrypted_data'='false', 'skip.header.line.count'='1' );
DDLの説明
CREATE EXTERNAL TABLE のところは、こういう名前のテーブルを作成しますという意味です。
ROW FORMAT SERDE のところは、テーブルに対してデータを読み書きする方法を記載するところです。
WITH SERDEPROPERTIES のところは、テーブルに対してデータを読み書きするときにどういうタイプのものかを明示するところです。
LOCATION のところは、今回だとS3のパスを指定するところです。
TBLPROPERTIES のところは、メタデータプロパティを指定するところで、今回だとCSVファイルの1行目はスキップするようにしています。(ヘッダ行のため)
クエリ実行
では、クエリを実行します。先程と同じく、「+」をクリックして、新たにクエリを書けるところを作成します。
今回は、人ごと+日付ごとの金額データを抽出するクエリを作成しました。これを実行します。
select user.Name, CAST(data.UsedDate AS timestamp) date, data.Cost from default.UserInfo user inner join default.UsedMoneyData data on user.id = data.UserId
実行結果
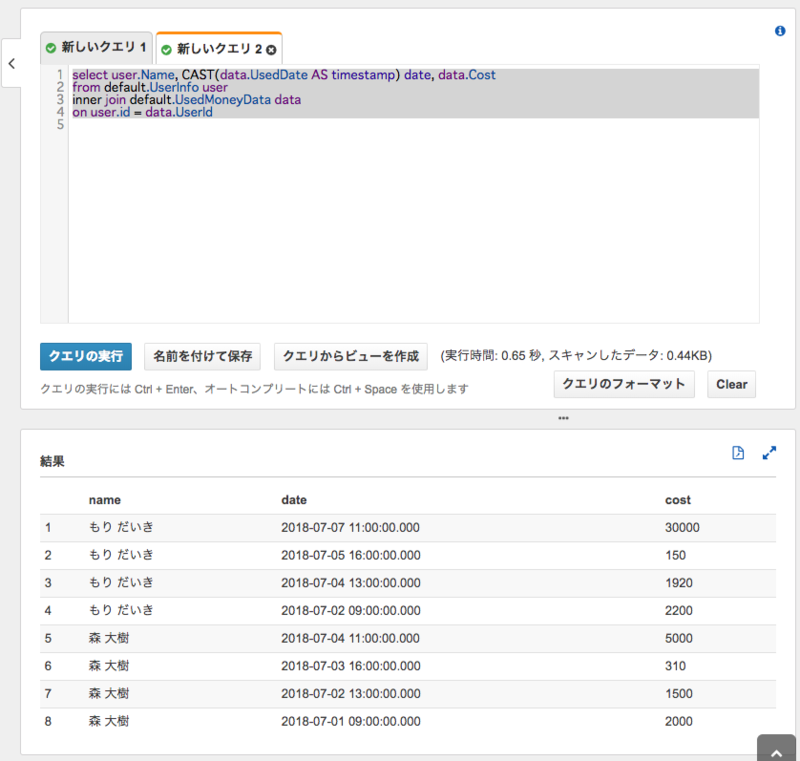
最後に
意外と簡単にできましたが、いくつか課題も見つかりました。
課題
- クエリを実行すると別ファイルのデータが取得される
- timestamp型で定義したデータが取得できない
1. クエリを実行すると別ファイルのデータが取得される
S3のバケットもしくは指定したフォルダ配下に2つ以上のファイルを配置した場合に発生します。
今回の例のファイルを同じフォルダに置きました。
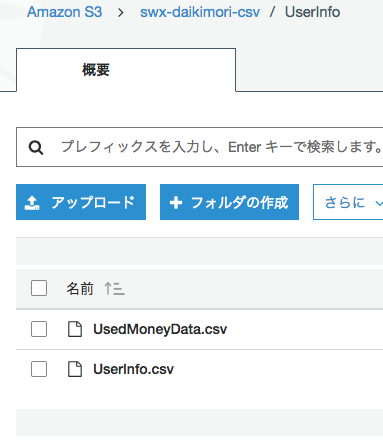 SELECT文を発行すると両方の情報が取得できました。
SELECT文を発行すると両方の情報が取得できました。
 ちょっと考えるとDDLでテーブル作成したときにS3バケット配下のフォルダを指定しただけなので、配下のファイルすべて同じデータと見られるのかと。
ちょっと考えるとDDLでテーブル作成したときにS3バケット配下のフォルダを指定しただけなので、配下のファイルすべて同じデータと見られるのかと。
これはちょっと焦りましたが、JOINする場合はバケットを分けるもしくはフォルダを分けておくといいかもです。
また、同じデータ形式で日毎にCSVが分かれていれば、同じフォルダに置くとクエリで全データを使った処理ができます。
ただ、データをパーティション分割することでパフォーマンス向上したり、コスト削減ができたりするので、そこはケースバイケースになるかと思います。
2. timestamp型で定義したデータが取得できない
これは、解決方法が見つかってないのですが、DDLを作成する際に日付型のところをtimestampに置き換えてクエリを実行するとエラーが発生します。
DDLはこれ
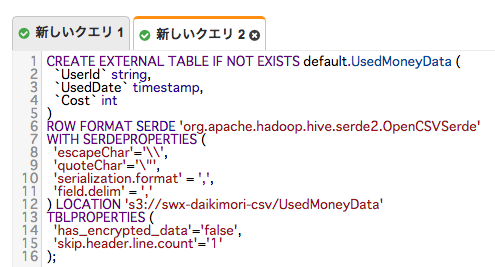 エラー情報はこちら
エラー情報はこちら
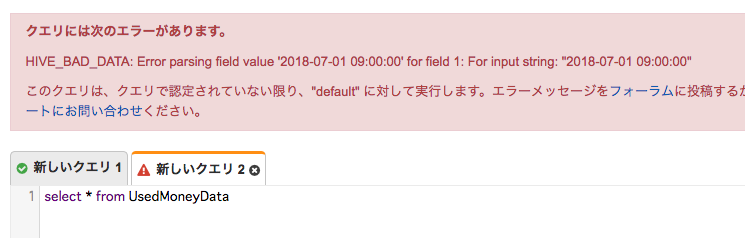 こちらは別途調査していこうと思います。
こちらは別途調査していこうと思います。
今回は一旦 string にしておいて、キャストして日付型にしてます。
キャストしておけば、日付で条件句をつけてクエリを発行すれば、データ範囲も絞ることも可能ですね。
参考URL
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/serde-about.html https://docs.aws.amazon.com/ja_jp/athena/latest/ug/csv.html https://docs.aws.amazon.com/ja_jp/athena/latest/ug/creating-tables.html https://docs.aws.amazon.com/ja_jp/athena/latest/ug/partitions.html