

こんにちは、技術4課の多田です。
私事ですが、サーバーワークスに入社して1年が経ちました。本当にあっという間でしたが、入社前後での自分のスキルアップを実感した1年でした。
2年目も引き続き頑張っていこうと思います。
さて、今回は、Application Load Balancer(以下、ALB)に関する豆知識情報になります。
ターゲットヘルスステータス
ALBでは、トラフィックを振り分ける対象をターゲットグループという形でグルーピングし、コンテンツパスベースでのルーティングを行います。
ターゲットグループでは、配下のEC2のステータスをチェックして管理しているのですが、各ステータスについては以下の通りです。
| ステータス名 | 説明 |
| initial | ターゲットを登録中か、ターゲットで最初のヘルスチェックを実行中という状態 |
| healthy | ターゲットは正常という状態 |
| unhealthy | ターゲットはヘルスチェックに応答しなかったか、ヘルスチェックに合格しなかった状態 |
| unused | ターゲットがターゲットグループに登録されていないか、ロードバランサーのリスナールールで使用されない。または、ロードバランサーに対して有効ではないアベイラビリティーゾーンにターゲットがある状態 |
| draining | ターゲットは登録解除中で、接続のストリーミング |
今回、注目するのは、「unhealthy」と「unused」になります。
「unhealthy」と「unused」について
両者の挙動の違いについて理解するために以下のような環境を準備して確認を行います。
シンプルなALBとEC2のみの構造で、EC2にApacheがインストールされています。ALBの構成方法については、寺田のこちらのブログを参照ください。

初期の状態は、ターゲットグループのEC2が正常な判定の「healthy」です。インスタンスにもヘルスチェックも来ている状態です。
[root@ip-10-200-1-135 ec2-user]# tail -f /var/log/httpd/access_log 10.200.3.134 - - [01/Feb/2017:08:11:07 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.0.172 - - [01/Feb/2017:08:11:09 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.3.134 - - [01/Feb/2017:08:11:37 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.0.172 - - [01/Feb/2017:08:11:39 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.3.134 - - [01/Feb/2017:08:12:07 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.0.172 - - [01/Feb/2017:08:12:09 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.3.134 - - [01/Feb/2017:08:12:37 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.0.172 - - [01/Feb/2017:08:12:39 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0"
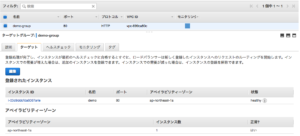
それではこの状態から「unhealthy」ステータスに遷移させるために、意図的にApacheを停止させます。
停止後は、ヘルスチェックも受け付けられない状態になり、「unhealthy」ステータスに遷移しています。
[root@ip-10-200-1-135 ~]# service httpd stop Stopping httpd: [ OK ] [root@ip-10-200-1-135 ~]# date 2017年 2月 1日 水曜日 08:20:55 UTC [root@ip-10-200-1-135 ~]# tail -f /var/log/httpd/access_log 10.200.3.134 - - [01/Feb/2017:08:16:37 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.0.172 - - [01/Feb/2017:08:16:39 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.3.134 - - [01/Feb/2017:08:17:07 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.0.172 - - [01/Feb/2017:08:17:09 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.3.134 - - [01/Feb/2017:08:17:37 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.0.172 - - [01/Feb/2017:08:17:39 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.3.134 - - [01/Feb/2017:08:18:07 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.0.172 - - [01/Feb/2017:08:18:09 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.3.134 - - [01/Feb/2017:08:20:38 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.0.172 - - [01/Feb/2017:08:20:39 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0"
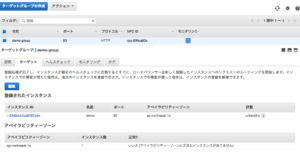
次に、ヘルスチェックのパスに指定しているヘルスチェックコンテンツのファイル名をリネームしてみましょう。尚、今回指定しているのは、ドキュメントルート直下の「index.html」です。
ファイル名を変更後、ヘルスチェックのHTTPステータスが403となり、ステータスは「unhealthy」扱いになりました。
[root@ip-10-200-1-135 html]# mv index.html index-bk.html [root@ip-10-200-1-135 html]# date 2017年 2月 1日 水曜日 08:44:33 UTC [root@ip-10-200-1-135 html]# tail -f /var/log/httpd/access_log 10.200.0.172 - - [01/Feb/2017:08:42:35 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.3.134 - - [01/Feb/2017:08:42:35 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.0.172 - - [01/Feb/2017:08:43:05 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.3.134 - - [01/Feb/2017:08:43:05 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.0.172 - - [01/Feb/2017:08:43:35 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.3.134 - - [01/Feb/2017:08:43:35 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.3.134 - - [01/Feb/2017:08:44:05 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.0.172 - - [01/Feb/2017:08:44:05 +0000] "GET / HTTP/1.1" 200 8 "-" "ELB-HealthChecker/2.0" 10.200.3.134 - - [01/Feb/2017:08:44:35 +0000] "GET / HTTP/1.1" 403 4891 "-" "ELB-HealthChecker/2.0" 10.200.0.172 - - [01/Feb/2017:08:44:35 +0000] "GET / HTTP/1.1" 403 4891 "-" "ELB-HealthChecker/2.0"
最後に、EC2を停止しても同じように「unhealthy」となるかを確認してみましょう。
ターゲットグループのステータスを確認してみますと、ステータスは「unused」という扱いになりました。
[root@ip-10-200-1-135 ~]# shutdown -h now [root@ip-10-200-1-135 ~]# Broadcast message from ec2-user@ip-10-200-1-135 (/dev/pts/0) at 8:25 ... The system is going down for halt NOW! Connection to 10.200.1.135 closed by remote host. Connection to 10.200.1.135 closed.
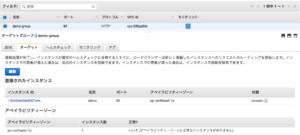
EC2インスタンスが停止した時には、ALBのヘルスチェックステータスが「unused」となり、
Apahceのデーモンが停止したり、ヘルスチェックパスに設定しているページのリネームを行った場合は「unhealthy」の状態へと遷移する点に違いがあります。
「unhealthy」扱いになるのは、ALBの振り分け先となるEC2上のデーモンが停止してたり、ヘルスチェックコンテンツのファイル名が変わってしまったりといった事態が当てはまることになります。
Route53のDNSフェイルオーバー対処
EC2インスタンスが停止した時、ALBのヘルスチェックステータスが「unused」となり、Apahceのデーモンが停止したり、ヘルスチェックパスに設定しているページのリネームを行うことで「unhealthy」の状態へと遷移する点に違いがあります。
このようなステータスが関係してくる場面の1つとして、Route53のDNSフェイルオーバーがあると思います。私も実際に試してみたところ、ALB配下のEC2が停止してもDNSフェイルオーバーは発生せず、EC2内のApacheを停止させた場合、DNSフェイルオーバーが発生しました。
従来のClassic Load Balancer(CLB)のようにEC2を停止した場合、DNSフェイルオーバーが発生しない点にALBとCLBの間に動作仕様の差異があるため、注意が必要です。
ただ、ALB配下のEC2が停止してもRoute53のDNSフェイルオーバーを実施する場合、別の仕組みを作りこむ必要があります。
その手段の1つとして私が動作確認を行った、弊社のCloud Automatorを使った対処について紹介します。
以下の図では、東京リージョンのEC2が停止した後、CloudWatch Alarmが発動してSNSによる通知が飛びます。
次に、Cloud AutomatorのジョブによりRoute53のレコードをソウルリージョンのALBのDNS名にレコードに書き換え、トラフィックを別リージョンに制御しています(赤の矢印が該当の処理です)。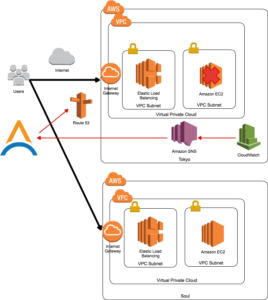
Cloud AutomatorでのRoute53レコード書き換え設定方法については、こちらを合わせてご覧ください。尚、私の設定は以下のようにしました。

AWS側で肝となるのは、CloudWatchのAlarm設定です。
通知の条件として、状態が「警告」と「不足」を指定しているのですが、前者がターゲットヘルスステータスの「unhealthy」時、後者が「unused」時の状態となります。
どちらもCloudWatch Alarmとして定義しておけば、どちらの状態でもDNSフェイルオーバーを実施できます。
それでは、東京リージョンのEC2を停止して、動作確認を行います。尚、フェイルオーバー前のdigの結果については以下の通りです。
;; ANSWER SECTION: www.xxxx-example.com. 205 IN CNAME demo-alb-xxxxxxxxx.ap-northeast-1.elb.amazonaws.com. demo-alb-xxxxxxxxx.ap-northeast-1.elb.amazonaws.com. 36 IN A 52.193.118.116 demo-alb-xxxxxxxxx.ap-northeast-1.elb.amazonaws.com. 36 IN A 52.198.206.86
AWSマネージメントコンソールより対象のEC2を停止します。


CloudWatch Alarmの画面でもステータスが「OK」から「不足」に遷移してSNS通知の条件となりました。


Cloud Automatorの後処理設定で処理結果をメール通知する機能があり、それを有効化していたため、メールでも処理が成功したというメッセージが確認できました。

DNSフェイルオーバー後のdigの結果を見ると、ソウルのALBのDNS名が返されています。
;; ANSWER SECTION: www.xxxx-example.com. 202 IN CNAME demo-alb-xxxxxxxxx.ap-northeast-2.elb.amazonaws.com. demo-alb-xxxxxxxxx.ap-northeast-2.elb.amazonaws.com. 23 IN A 52.79.185.254 demo-alb-xxxxxxxxx.ap-northeast-2.elb.amazonaws.com. 23 IN A 52.78.206.27
まとめ
ALBのターゲットグループにおけるヘルスチェックステータスについて動作確認した内容をレポートしました。
※尚、本レポートは2017年2月7日時点のものになります。
この記事が何かの参考になれば、幸いです。それでは!