

Serverworks Sonic #006 にお越し頂きありがとうございました!
こんにちは技術2課・大阪メンバーの柏尾です。
先日8/20にサバソニ(Serverworks Sonic #006)が開催されました。たくさんの方にご参加いただき大盛況のうちに終わることができました。
僕もパネルディスカッションに参加しましたが、少しでもサーバーワークスという会社の魅力がお伝えできていれば幸いです。 今回参加出来なかった方も、次回のサバソニにはゼヒお越しください!
「Talend Open Studio」でRedshiftへのデータ登録処理を開発する
前回エントリの続きになりますが、
・S3からデータを取得
・取得したデータをフィルタリング
・Redshiftに登録
という一連の処理を「Talend Open Studio」を使って実装してみたいと思います。
※今回の処理ぐらいだと、Redshiftに直接S3のデータをBulkコピーしてゴニョゴニョすればいけるかもしれませんが、説明のために上記のようなフローで処理をしたいと思います。
ファイルからデータを読み込む「tFileInputDelimited」
前回のS3からのデータ取得ジョブにファイル読み込みのジョブを追加していきます。S3からダウンロードしたファイルから1行つづデータを読み出すための処理になります。
右メニューのパレットの検索ボックスに「tFileInputDelimited」と入力します。 表示されたコンポーネントをドラッグ&ドロップでDesigner領域に配置します。
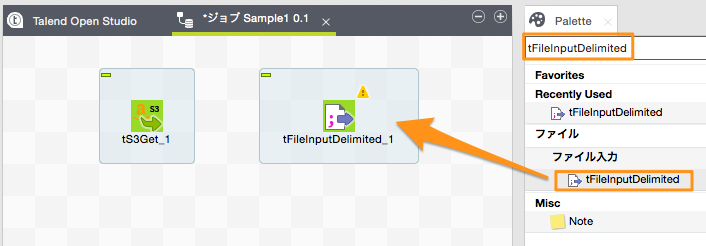
「t3Get」コンポーネントを右クリックし、「トリガ」→「サブジョブがOKの場合」を選択すると、接続線が出現しますのでこれを「tFileInputDelimited」コンポーネントに接続します。
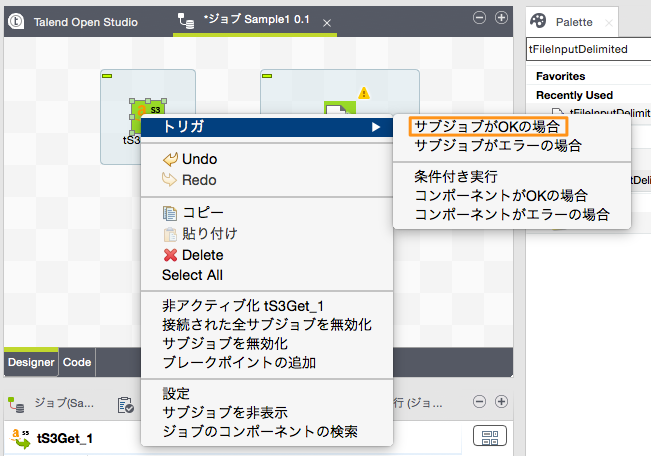
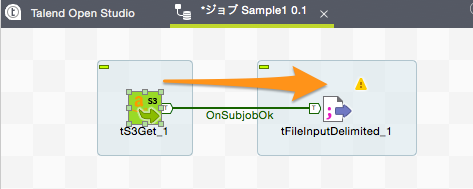
※「サブジョブ」というのはいくつかのコンポーネント処理の集まりなのですが、今回は「t3Get」コンポーネントだけなので「コンポーネントがOKの場合」を選択しても良いです。幾つかのコンポーネントの処理をまとめてサブジョブとしている場合で、それら一連の処理が終わってから次の処理に移りたい場合は、「サブジョブがOKの場合」とする必要があります。
「tFileInputDelimited」コンポーネントはカンマやタブ区切りのデータファイルを1行づつ読み込んで処理するためのコンポーネントです。このコンポーネントを選択して下部に表示される「基本設定」に設定を行います。
| 設定名 | 設定値 | 補足 |
|---|---|---|
| ファイル名/ストリーム | "/Users/kasshy/allusers_pipe.txt" | 処理対象ファイルのファイルパス |
| フィールド区切り記号 | "|" | 区切り記号(今回のファイルはパイプ区切り) |
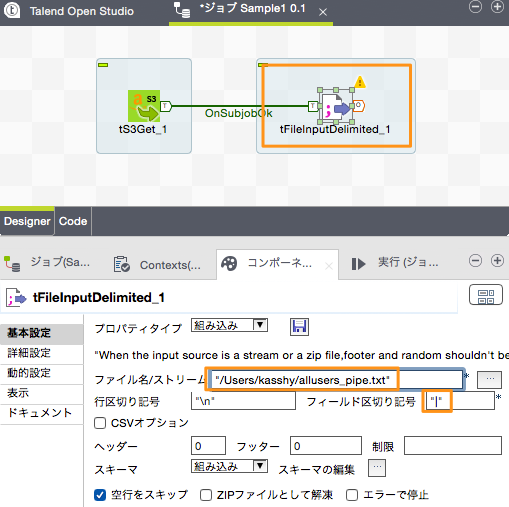
その他の設定はデフォルトのままです。行区切りの記号やヘッダーフッターがある場合はその行数の指定を「基本設定」で、ファイルの文字コードを指定したい場合は「詳細設定」から行うことができます。
次に読み込むデータのスキーマ設定を行います。スキーマ設定はリポジトリに作成しておいてそれを使う方法と、コンポーネントに直接設定する方法があります。今回は直接コンポーネントに設定する方法で設定します。
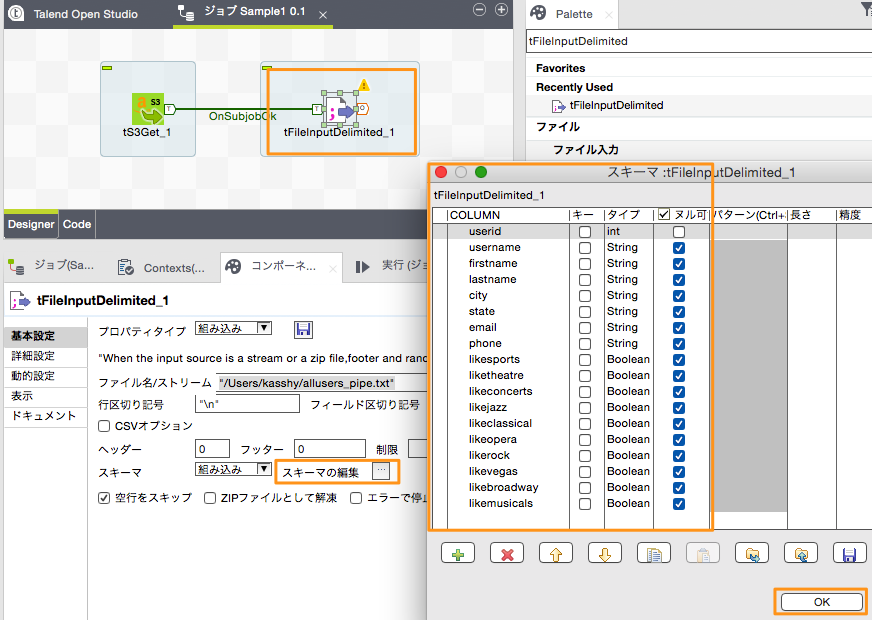
スキーマの情報はAWS入門ガイドで提供されているS3上のサンプルデータの「users」テーブルの情報を元に設定しています。
| 項目名 | Javaデータ型 | NOT NULL |
|---|---|---|
| userid | int | ◯ |
| username | String | |
| firstname | String | |
| lastname | String | |
| city | String | |
| state | String | |
| String | ||
| phone | String | |
| likesports | Boolean | |
| liketheatre | Boolean | |
| likeconcerts | Boolean | |
| likejazz | Boolean | |
| likeclassical | Boolean | |
| likeopera | Boolean | |
| likerock | Boolean | |
| likevegas | Boolean | |
| likebroadway | Boolean | |
| likemusicals | Boolean |
Rowデータのフィルタリングを行う「tFilterRow」
読み込んだデータから不要なデータを取り除くようなフィルタ処理を作成したいと思います。「tFilterRow」コンポーネントをパレットから検索しDesigner領域にドラッグアンドドロップします。
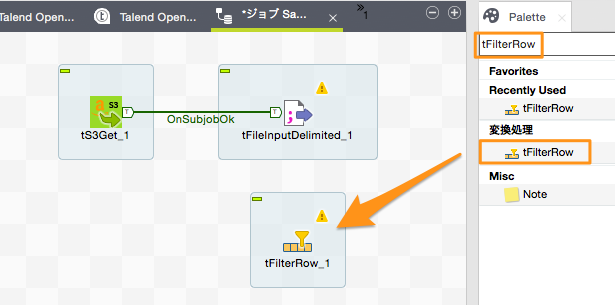
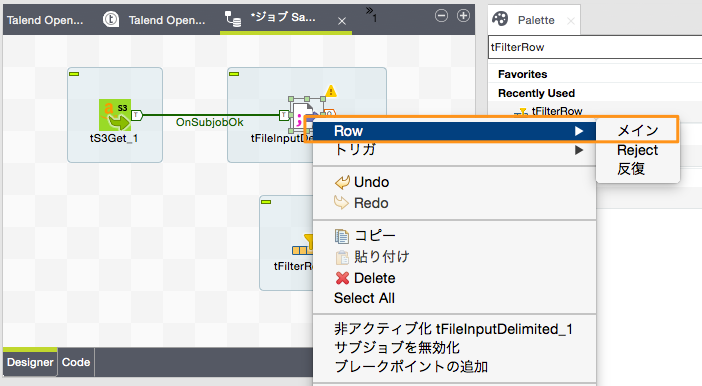
「tFileInputDelimited」コンポーネントを右クリックし、「Row」→「メイン」を選択すると接続線が出現しますので、これを「tFilterRow」コンポーネントに接続します。ファイルから読み込まれた1行1行のデータが「tFilterRow」コンポーネントに渡されることになります。
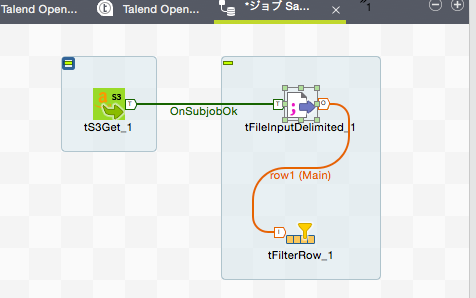
「tFilterRow」コンポーネントの基本設定には入力されてくる1行データの各カラムデータを評価するための条件を複数設定することができます。今回は『「likesports」がtrueのレコードかつ、「userid」が100以下のデータ』のみを次の処理に通すように設定したいと思います。

条件1
| 設定名 | 設定値 | 補足 |
|---|---|---|
| 入力カラム | likesports | |
| オペレータ | == | |
| 値 | true |
条件2
| 設定名 | 設定値 | 補足 |
|---|---|---|
| 入力カラム | userid | |
| オペレータ | <= | |
| 値 | 100 |
※基本設定の下部にある「詳細モード」をつかえばデータの評価処理をJavaコードを直接記述できるので、より複雑な条件のフィルタ処理も可能です。
Rowデータの表示を行う「tLogRow」
これらフィルタされたデータをコンソールに表示してみたいと思います。右メニューのパレットで「tLogRow」で検索します。「tLogRow」コンポーネントをDesigner領域にドラッグアンドドロップします。
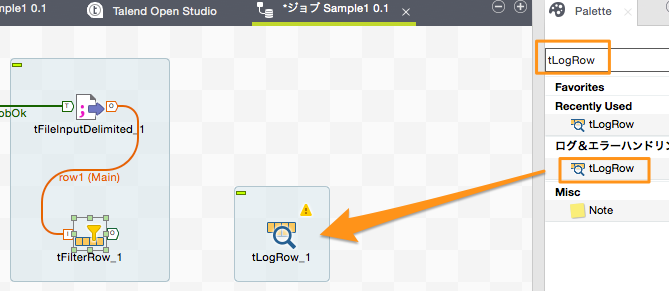
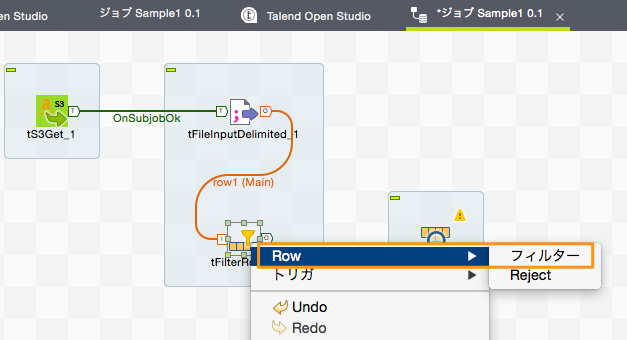
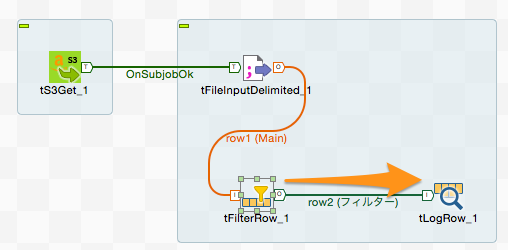
「tFilterRow」コンポーネントを右クリックし、「Row」→「フィルター」を選択すると接続線が出現しますので、これを「tLogRow」コンポーネントに接続します。「tFilterRow」のフィルター条件に合致した1行1行のデータが「tLogRow」コンポーネントに渡されることになります。
※「Row」→「Reject」でつないだ場合は、条件に一致しなかったデータが後続の処理に流れることになります。これを利用することで条件に一致するデータ、しないデータを仕分けするといったこともできます。
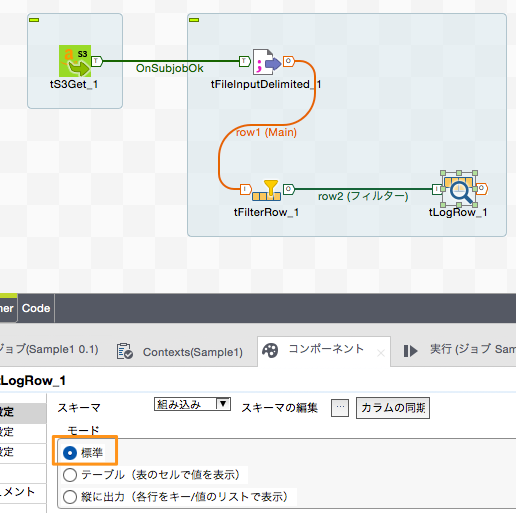
「tLogRow」コンポーネントの設定では、どういう形式でデータをコンソールに表示するかを指定します。今回は「標準」で出力します。
一旦プロジェクトを保存し、作成したジョブを実行してみたいと思います。
プロジェクト名を右クリックして「実行」もしくは下部メニューからジョブを実行します。
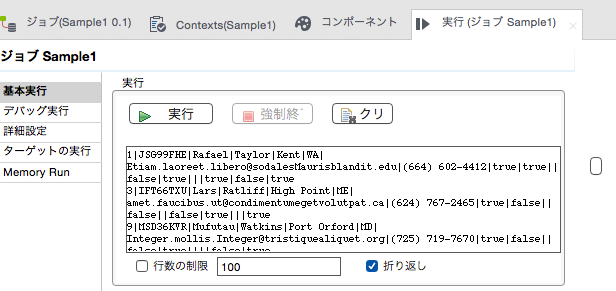
下部のコンソールにフィルタされたデータが表示されればOKです。
データをRedshiftに投入する「tRedshiftOutput」
最後にフィルタリングされたデータをRedshiftに投入する処理を作成したいと思います。
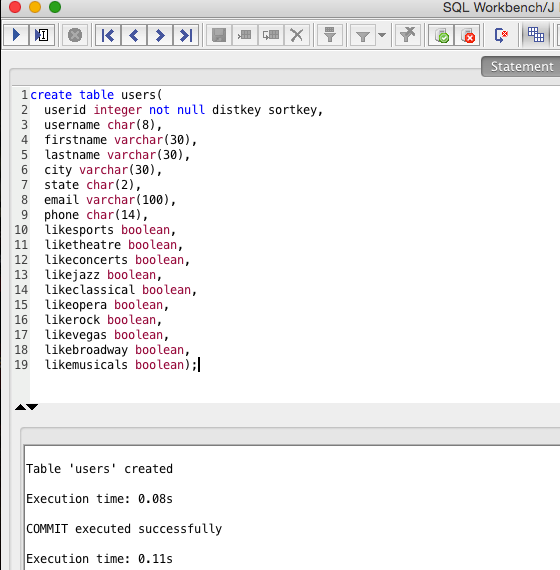
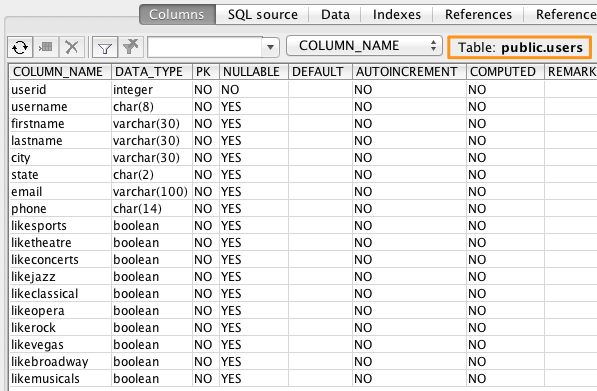
usersテーブルの作成
事前に、AWS入門ガイドで提供されているS3上のサンプルデータの「users」テーブルを「SQL Workbench/J」などを利用し、Redshift上に作成しておきます。SQL Workbench/Jの利用手順はSQL Workbench/J を使用するクラスターに接続するを参考にしてください。
tRedshiftコンポーネント
パレットで「tRedshift」と検索するとRedshift関連のコンポーネントが幾つか表示されると思います。
それらのうち、「tRedshiftOutput」コンポーネントをDesigner領域にドラッグ&ドロップします。「tRedshiftOutput」コンポーネントはデータをRedshiftに出力するためのコンポーネントです。
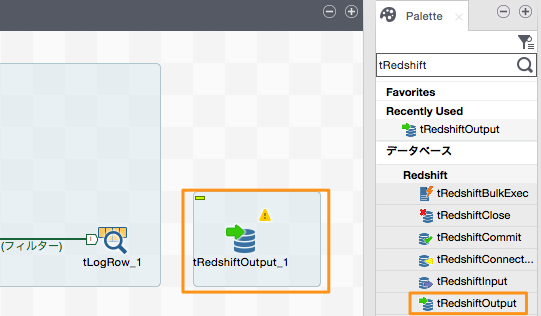
「tLogRow」コンポーネントを右クリックし「Row」→「メイン」を選択すると接続線が出現しますので、これを「tRedshiftOutput」コンポーネントに接続します。
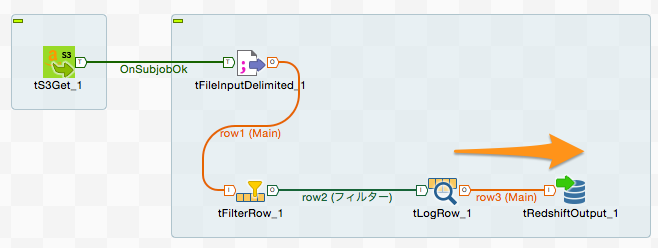
「tRedshiftOutput」コンポーネントの「基本設定」にはRedshiftへの接続情報やスキーマ情報を入力します。
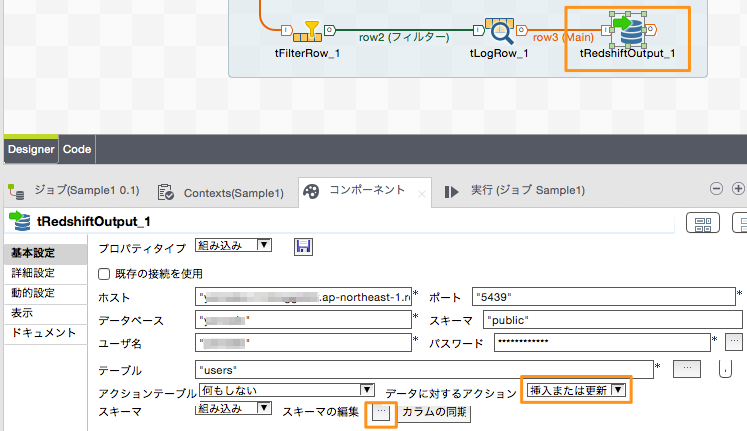
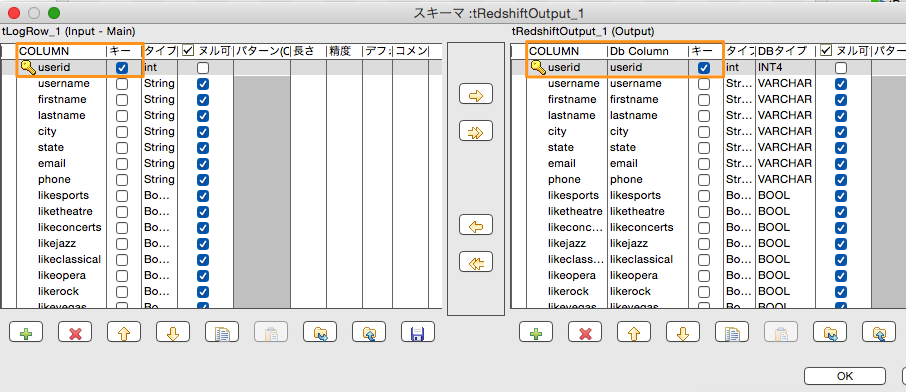
| 設定名 | 設定値 | 補足 |
|---|---|---|
| ホスト | "xxxxx.xxxxxxxxxxxx.ap-northeast-1.redshift.amazonaws.com | Redshiftのホスト |
| ポート | "5439" | Redshiftへの接続ポート番号 |
| データベース | "xxxxx" | データベース名 |
| スキーマ | "public" | スキーマ名 |
| ユーザ | "xxxxx" | 接続ユーザ名 |
| パスワード | "xxxxxx" | パスワード |
| テーブル | "users" | テーブル名 |
| データに対するアクション | 挿入または更新 | 下記(※)参照 |
※Redshiftの注意点としてプライマリーキー制約が効かないため、プログラムなどで同じキーのデータが入らないように制御する必要があります。「tRedshiftOutput」コンポーネントのスキーマ設定でプライマリキーとなる項目を設定しておき、なおかつ「データに対するアクション」を「挿入または更新」にしておくことで、同じプライマリーキーのデータがテーブルに存在する場合は更新、そうで無い場合は挿入という動きをしてくれるようになっています。
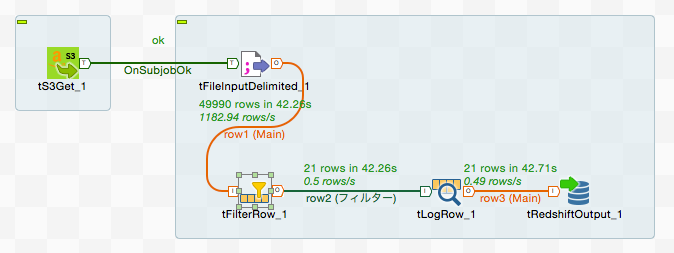
ジョブの実行と結果の確認
最後にtalend上でジョブを実行して、実際にデータが登録されるかを確認します。 ジョブを実行する環境からRedshiftに接続する際に、セキュリティグループで接続が許可されている必要がありますので事前に許可をしておいてください。
フィルター条件に合致する21件のレコードが挿入されていることが確認できました。
デザイナ上でも何件データが処理されているかが確認できるのが親切ですね。
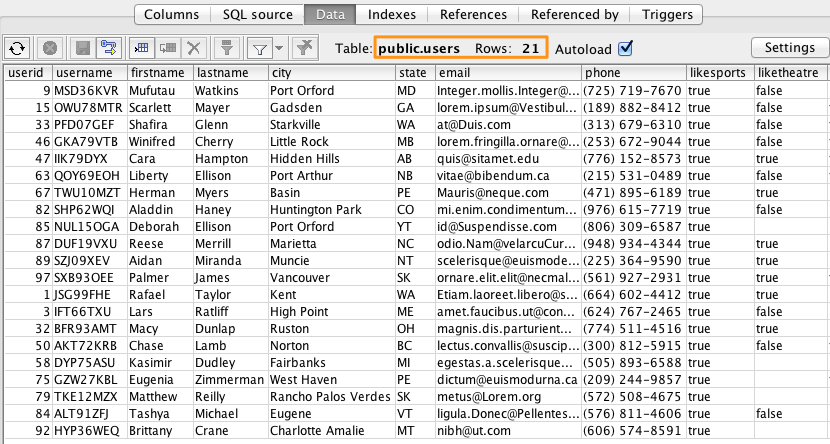
SQL Workbench/J上でもデータが挿入されていることが確認できました。
まとめ
いかがでしたでしょうか?S3からデータをダウンロードし、そのデータを加工し、Redshiftに登録するという一連の処理を実装してみました。
Talend Open Studioを使うことでコードを書かなくても、talendコンポーネントの組み合わせでAWSの環境に接続し、ETL的な処理が実装できることがお分かりいただけたかと思います。