

こんにちは。
寒い夜には芋焼酎のお湯割りもいいけど、芋焼酎の燗もいいよね、と思うセールスチーム 永淵(@Nagafuchik)です。
さて、前回のエントリーに続きAmazon Redshiftをテーマに投稿します。
今回は自身のPCにあるSQL WorkbenchからAmazon Redshiftに接続してサンプルデータを取り込んでみます。
SQL Workbenchのセットアップ方法はこちらのリンクに詳しく記載されています。
1. SQL Workbenchのインストール
こちらのページ:http://www.sql-workbench.net/からパッケージをダウンロードし、ローカルにインストールします。
インストールしたSQL Workbenchを起動すると、こんな画面が表示されます。
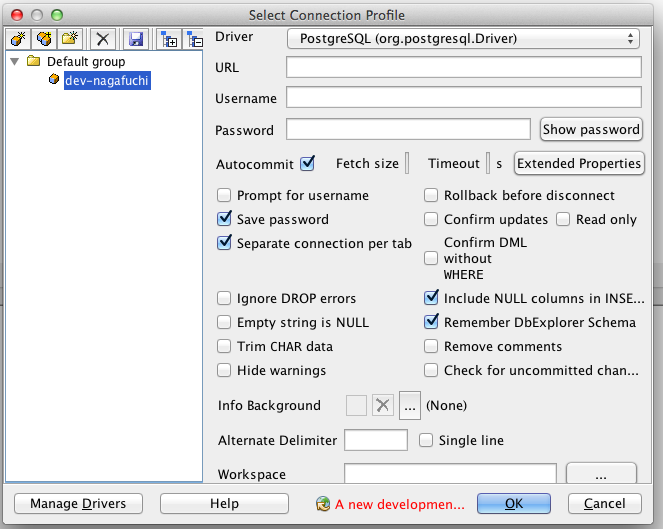
2. SQL Workbenchの起動
「Manage Drivers」から「PostgreSQL」のドライバーを選択します。
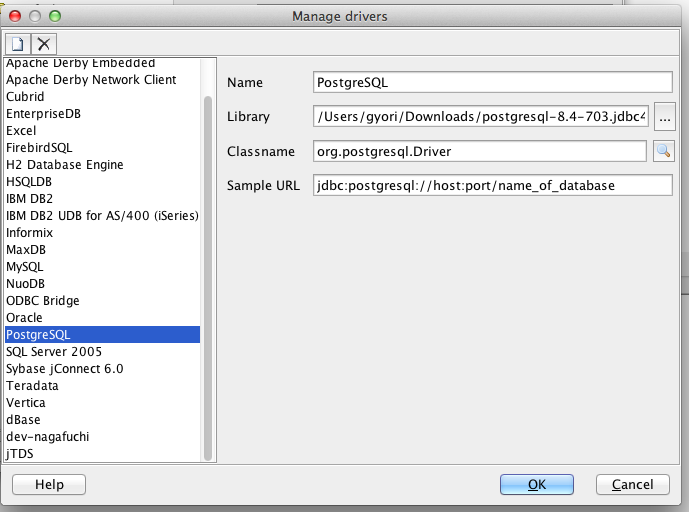
※PostgreSQLのJDBCドライバーが無い場合は別途セットアップしてください。(参考:http://www.postgresql.jp/document/7.4/html/jdbc.html)
ドライバーを選択したら、次はRedshiftの接続情報を入力します。
AWS Management ConsoleのClusterをクリックすると、詳細情報が表示されます。
JDBSのURLをクリックするとコピーできますのでコピーしましょう。
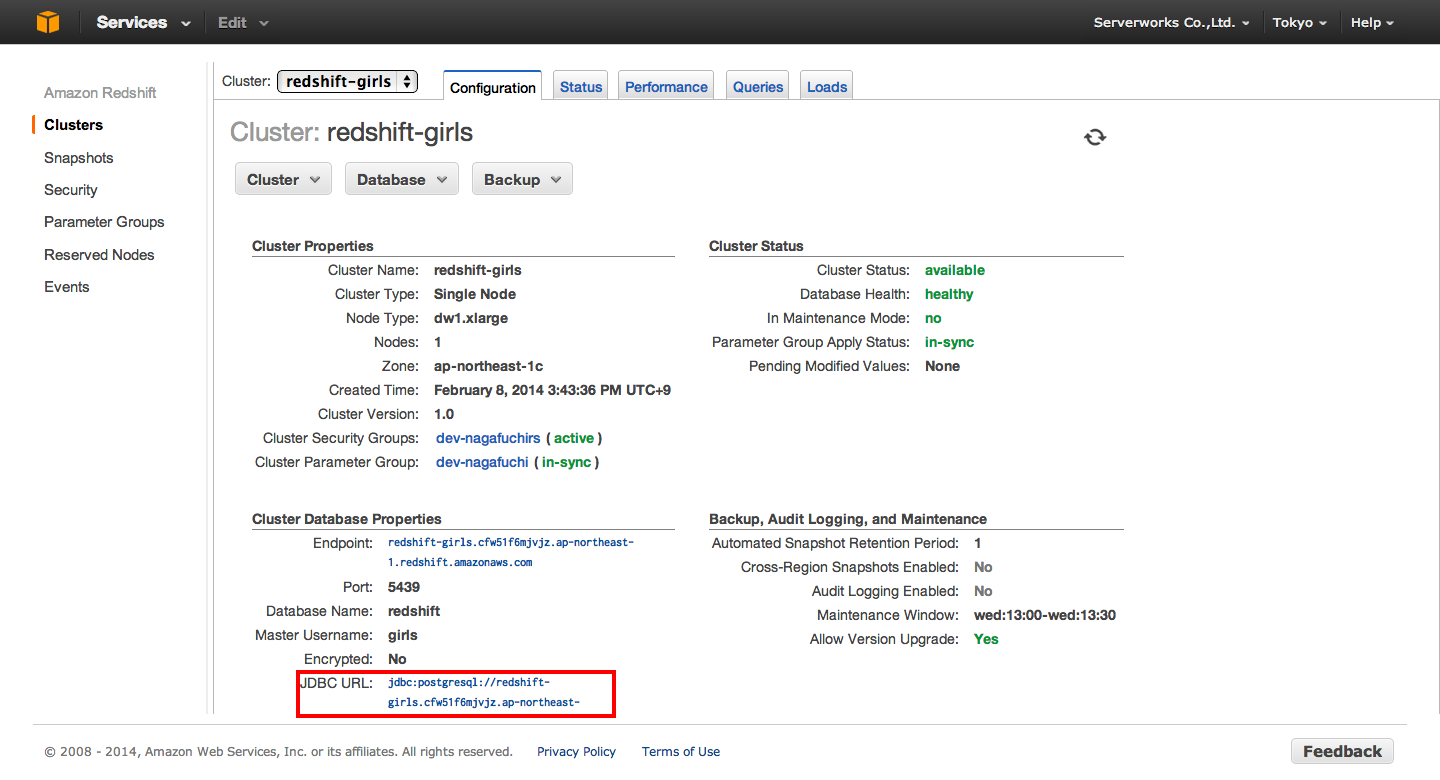
コピーしたURLをSQL Workbenchの「URL」にペースト。RedshiftのClusterを作成したときに設定した、DBのユーザー名とパスワードを入力します。
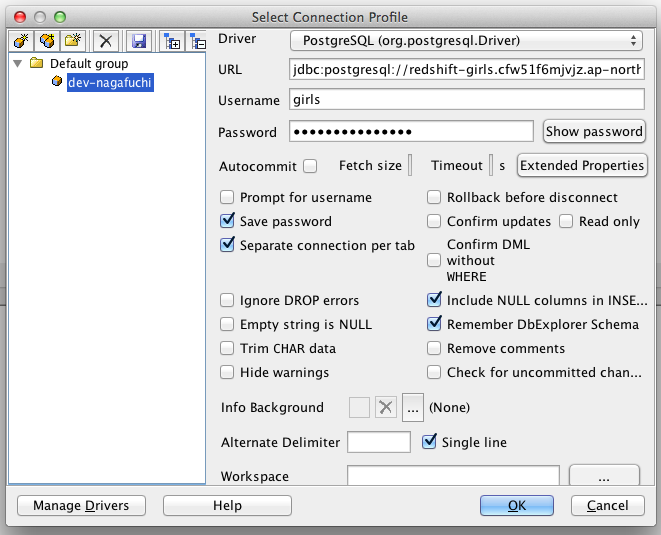
これで完了。
少しドキドキしながら「OK」をクリック
「connecting...」と表示され・・接続できました。
3. サンプルデータを投入する
無事、Redshiftに接続できましたので、次はサンプルデータを投入してみます。
どんなデータでもかまいませんが、AWSがこちらのページでサンプルを提供しているので今回はこれを利用してみたいと思います。
まずはテーブルを作成します。
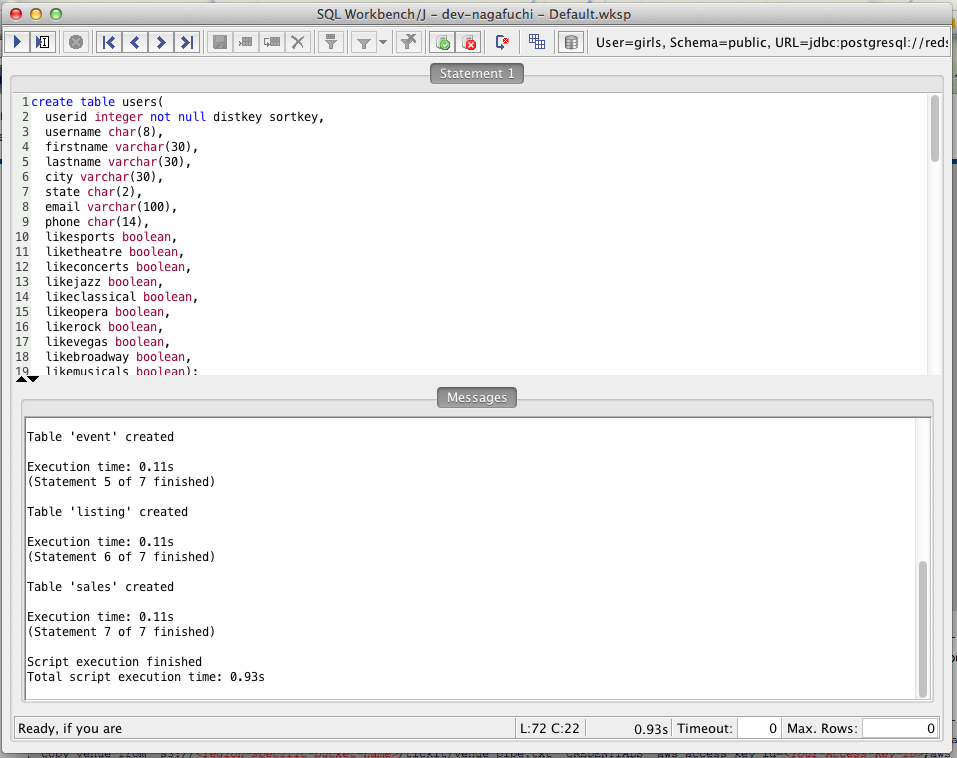
次にS3上に置かれているサンプルデータを投入します。
サンプルデータのフォーマットは下記を参考に編集してください。
copy users from 's3://<東京リージョンのサンプルデータをひっぱっt"awssampledbapnortheast1"を入力>/tickit/allusers_pipe.txt' CREDENTIALS 'aws_access_key_id=<アクセスキーIDを入力>;aws_secret_access_key=<シークレットアクセスキーを入力>' delimiter '|';
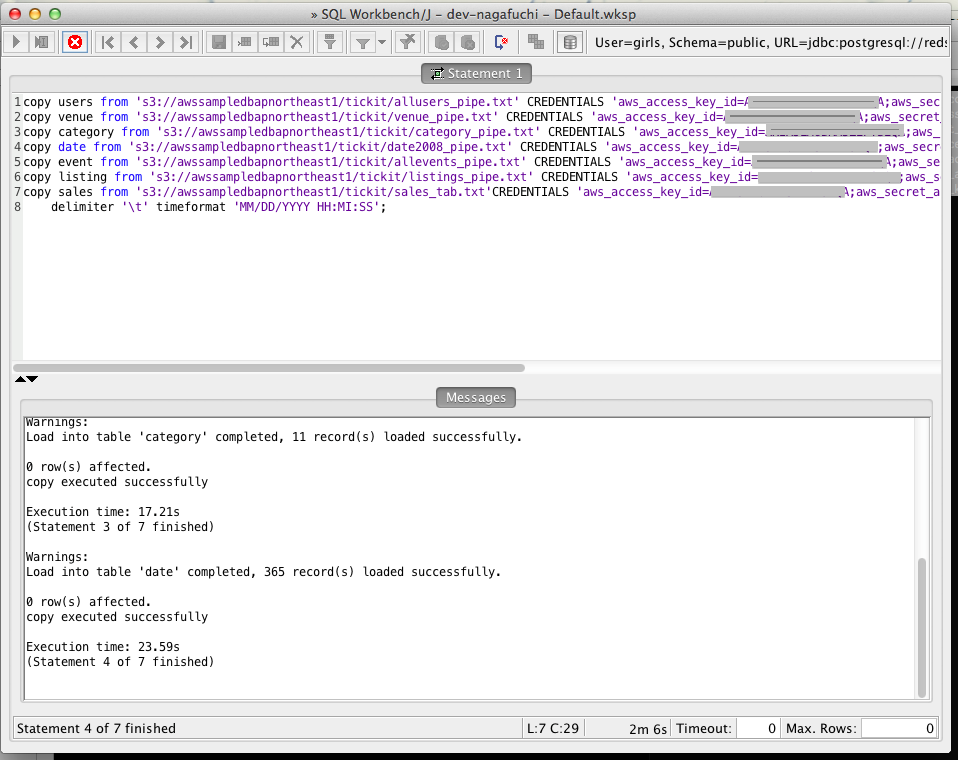
だん。
4. SELECT文をたたいてみる
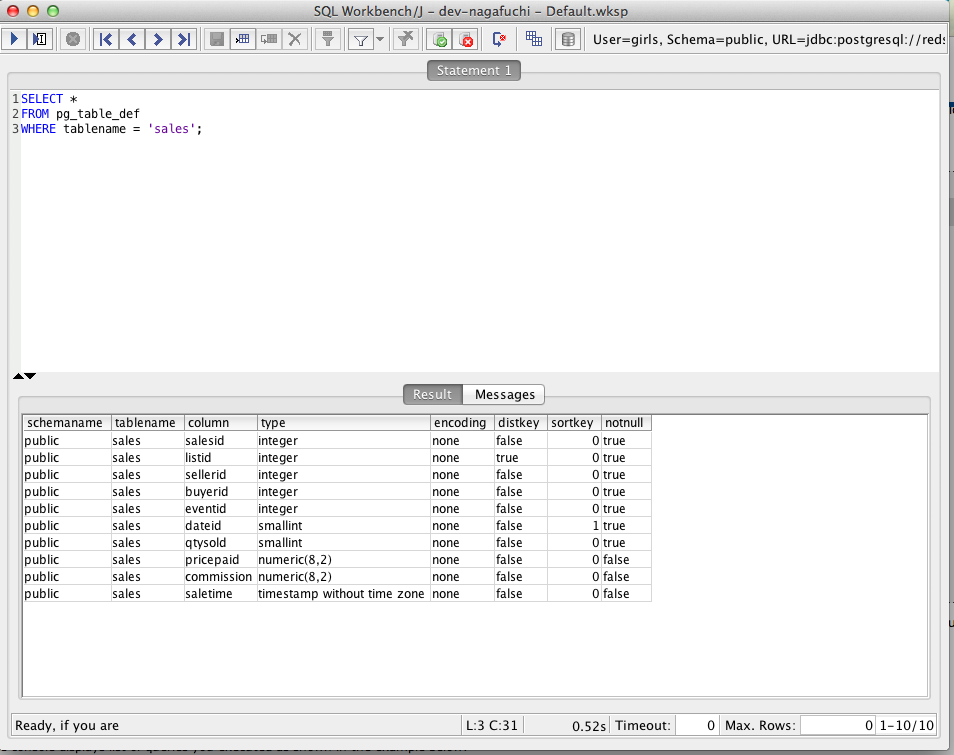
データが投入できましたので、どんなデータが入っているのかのぞいてみましょう。
- table名に「sales」が含まれるデータをセレクト(およそ1秒)
- 上客(違ww)を抽出(およそ8秒)
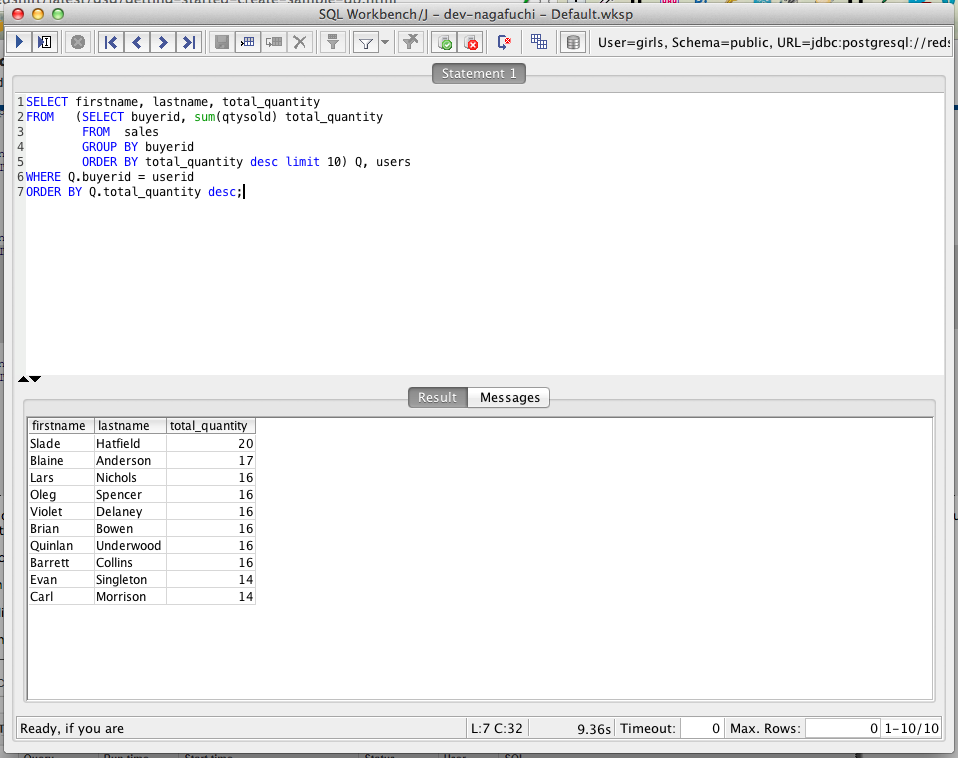
速い、速いぞRedshift!!!
こんな感じで、RedshiftにSQL Workbenchから接続することができました。
データはS3やDynamoDBからも引っ張ってくることができます。DynamoDBを活用していらっしゃるような方にはぜひ、Redshiftと組み合わせて使っていただきたいですね。
まとめ
今回紹介したSQL Workbench以外にもRedshiftに接続するためのクライアントツールは用意されています。今までも使ってきたような慣れた方法でRedshiftを活用することができそうですね。
でもでも、データを投入するで終わってはせっかくのビッグデータも台無しです。ということで次はいろいろなBIツールと接続することで、データの可視化の方法を探ってみたいと思います。
次はJaspersoftとTableauとの連携について書きます(予定で未定)