

こんにちは、マツシタです。
みなさん、ご存知ですか?当社の「カスタマーポータル」というAWS請求代行サービス利用のお客様がAWS利用料を確認できるサイトの名前が「AWS利用料金確認ページ」と変わりました。確かに、利用料金の確認や利用明細のダウンロードが主な機能なので、新名称「AWS利用料金確認ページ」の方が名前と機能はマッチします。ただ、私はその名称を覚えるのに少し時間がかかりそうです。
はじめに
さて、カスタマーポータル改め「AWS料金確認ページ」の改名にちなんで、そこからダウンロードした利用明細をAthenaに取り込む手順を紹介しようと思います。Athenaに取り込むことで、それを分析したり、Quicksightを使って見える化することもできますので、分析や見える化の前準備に当たる部分です。
今回は当社のAWS料金確認ページからダウンロードした利用明細でのAthena取り込みを中心に書きますが、AWSマネージメントコンソールの請求ダッシュボードからダウンロードした利用明細でも、できるだけ応用できるように書いていきますが、少し足りない部分はご容赦ください。
また、2種類の利用明細を用いますので、呼び方を整理します。ここではAWS利用料金確認ページからダウンロードした利用明細を「当社の利用明細」、AWS請求ダッシュボードからダウンロードした利用明細を「AWS利用明細」と呼ばせてください。また、「利用明細」と呼んだ場合にはその双方を指します。
| ここでの呼称 | |
|---|---|
| 当社の利用明細 | AWS利用料金確認ページからダウンロードした利用明細 |
| AWS利用明細 | AWS請求ダッシュボードからダウンロードした利用明細 |
| 利用明細 | 上記の双方 |
当社の利用明細とAWS利用明細の違い
まずは、当社の利用明細とAWS利用明細の違いを少し説明します。どちらもCSV形式でダウンロードができ、利用明細は1行ごとに記載される点は共通です。違いは列の数です。当社の利用明細は、情報量を少なく、列数を少なくなっています。利用料を分析する上で必要な情報は網羅されているのでご安心ください。
実際に比較します。
| AWS利用明細 | 当社の利用明細 | 補足説明 |
|---|---|---|
| InvoiceID | ||
| PayerAccountID | ||
| LinkedAccountID | AccountId | 対象AWSアカウントID |
| RecordType | ||
| RecordID | ||
| BillingPeriodStartDate | ||
| BillingPeriodEndDate | ||
| InvoiceDate | InvoiceDate | 該当月1日. AWS利用明細の場合は[YYYY/MM/1 00:00:00], 当社の利用明細の場合は[YYYY/MM/1] |
| PayerAccountName | ||
| LinkedAccountName | ||
| TaxationAddress | ||
| PayerPONumber | ||
| ProductCode | ProductCode | サービス名の略称(例 : Amazon EC2) |
| ProductName | ProductName | サービス名(例 : Amazon Elastic Compute Cloud) |
| SellerOfRecord | ||
| UsageType | ||
| Operation | ||
| RateId | ||
| ItemDescription | ItemDescription | 詳細説明 |
| UsageStartDate | ||
| UsageEndDate | ||
| UsageQuantity | UsageQuantity | 利用量 |
| BlendedRate | ||
| CurrencyCode | ||
| CostBeforeTax | CostBeforeTax | 税抜き利用料 |
| Credit | ||
| TaxAmount | ||
| TaxType | ||
| TotalCost | ||
| InvoiceStatus |
分析に必要な項目を中心に補足コメントを入れました。「InvoiceDate」だけはそれぞれの利用明細で表記が異なります。当社の利用明細の場合は「2021/9/1」のように年月日、AWS利用明細の場合は「2021/9/1 00:00:00」と時間まで含まれます。それ以外は項目数に違いはありますが、表記に違いはなく、Athenaに取り込む処理ではほぼ同じように扱うことができます。
当社の利用明細をExcelで開いた際の状態を参考までに共有します。

利用明細のS3アップロード
さて、準備を始めていきましょう。お手元にCSV形式の当社の利用明細、もしくはAWS利用明細は用意してください。その利用明細を一切加工はせずに、S3にアップロードします。アップロード先、S3バケットとフォルダを作成します。
AthenaからS3にあるファイルを取り込む際には、フォルダを指定します。すると、Athenaは指定したフォルダにある全てのファイルをクロールします。バケットは他の情報と混在していても問題ありませんが、フォルダは利用明細格納専用に作る必要があります。
なので、既存のバケットを利用しても問題ありません。新規でバケットを作成する場合、マネージメントコンソールから作成するのであれば、デフォルト設定で問題ありません。
今回はあるバケットに[rawdata]というフォルダを作成し、それを利用明細専用フォルダとします。同じフォーマットのデータファイルであれば複数のファイルをアップロードしても問題ありませんので、先月分の利用明細だけではなく、先々月分、それ以前のデータを合わせてアップロードしても処理できます。ただ、違うフォーマットのファイルはアップロードしないようにしましょう。
もし、当社の利用明細とAWS利用明細の両方で分析した場合はデータのフォーマットは異なりますので、別のフォルダにアップロードしてください。
利用明細のアップロードが終わりましたら、最後に、このアップロードしたフォルダのURI(例えば、s3://<バケット名>/rawdata/)をメモ帳などに書き残しておいてください。(*1)
Athenaへの取り込み
ここからが今回のメインとなります。 Amazon Athenaにアクセスします。初めてアクセスする場合には、こちらの画面が表示されますので、[クエリエディタを詳しく確認する]をクリックします。
[クエリエディタを詳しく確認する]をクリックした場合、もしくは初めてのアクセスではない場合には以下の画面が表示されます。右上の青い四角の部分にクエリを記入します。下にスクロールする実行ボタンがあります。クエリでデータベースを作成すると左側のデータベースというプルダウンリストに追加されます。同じくクエリでテーブルやビューを作成すると左下に表示されるようになります。
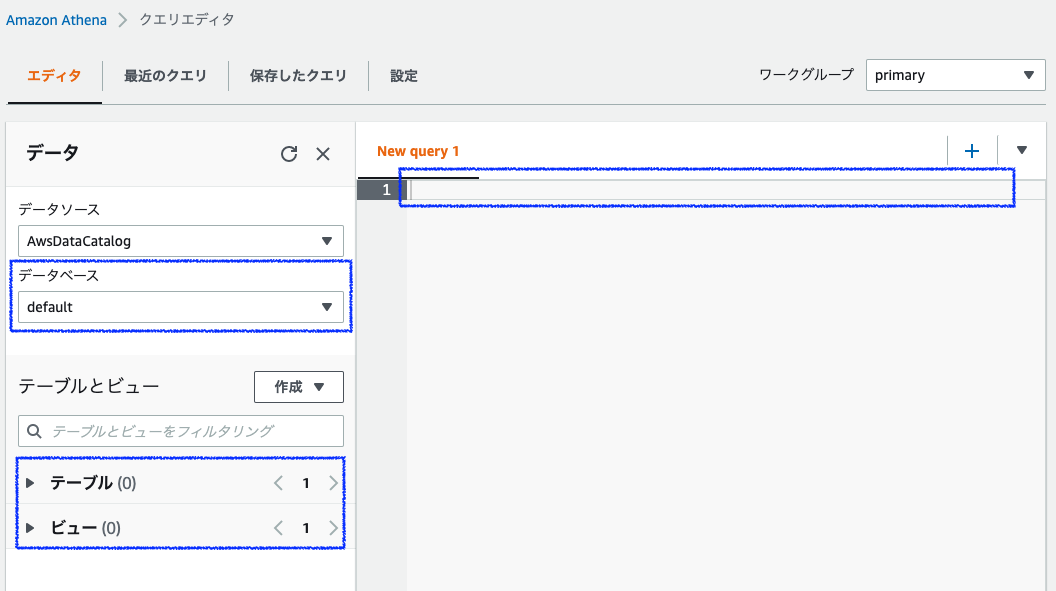
左ペインにある[作成]をクリックし、[S3バケットデータ]をクリックします。
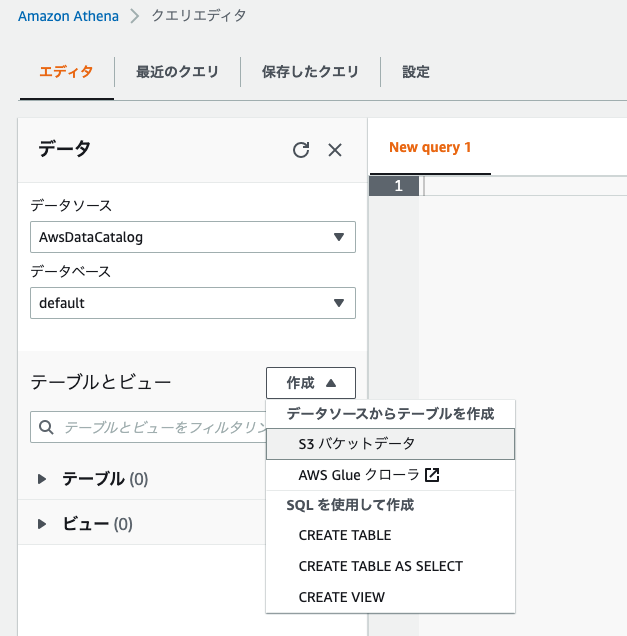
Athena側のテーブルの詳細(作成するテーブル名)、データベース設定(データベース名)、データセット(S3側のロケーション)、データ形式と列の詳細を指定します。今回は以下の設定で進めます。
| 項目 | 入力内容 |
|---|---|
| テーブル名 | billing_table |
| 説明 | |
| データベース設定 | ○既存データベースを選択 ● データベースを作成 |
| データベース名 | billing |
| データセット | s3://<バケット名>/rawdata/ |
| データ形式 | CSV |
フォームのデータベース名を[billing]、テーブル名を[billing_table]と入力します。
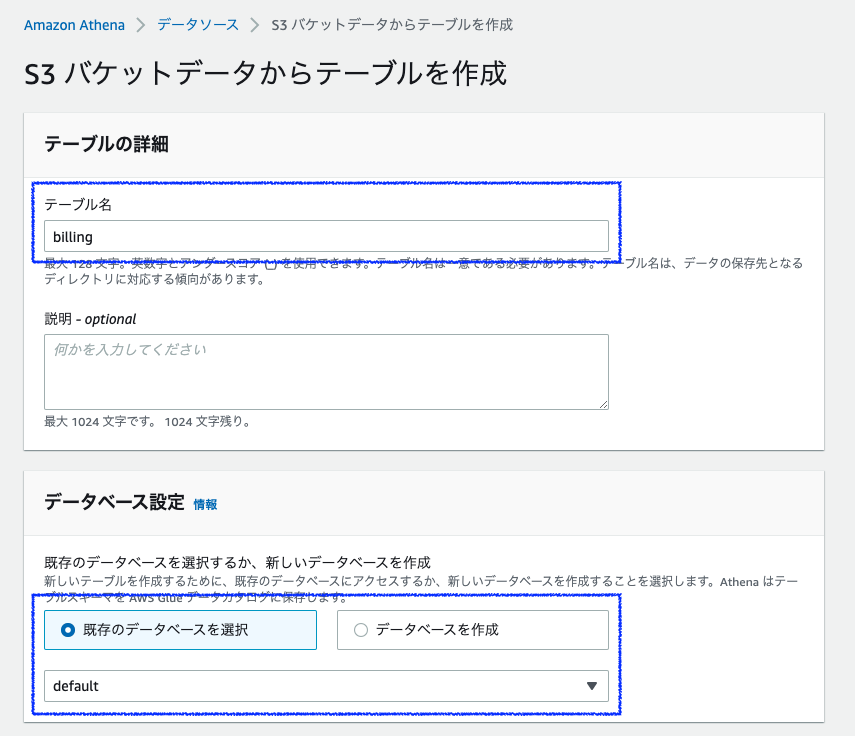
下にスクロールし、データセットはメモ帳に残しておいてURI s3://<バケット名>/rawdata/(*1)を転記します。データ形式はプルダウンリストからCSVを選択します。
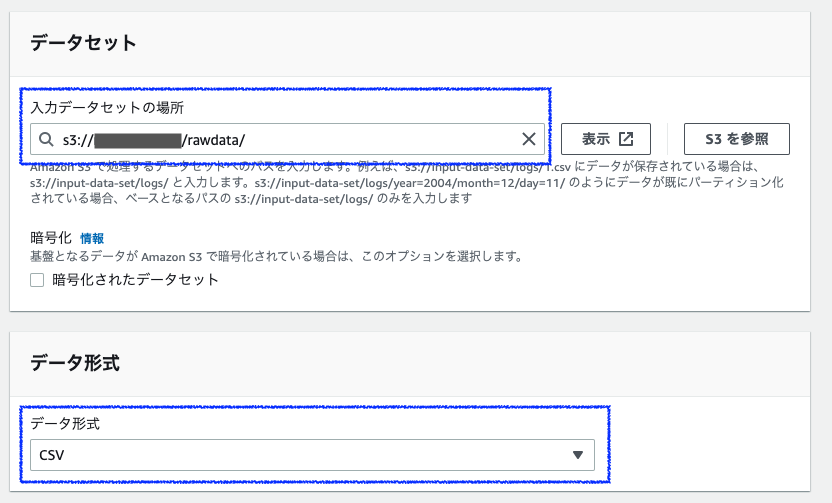
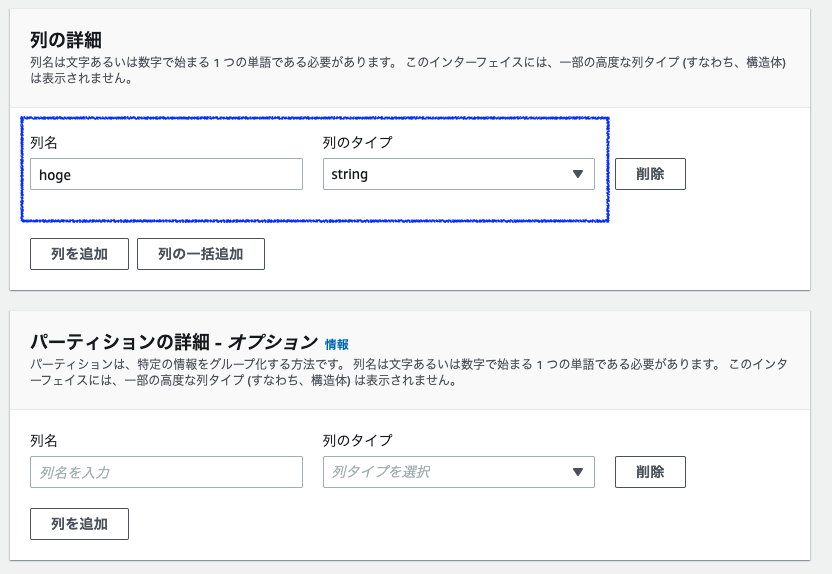
下にスクロールし、列の詳細は一旦、列名を「hoge」、列のタイプを「string」と入力します。(ここは今は、なんでも良いです。)
そして、下にスクロールすると、ここまでで設定した項目に沿ったクエリが作られています。ここで「テーブルを作成」をクリックすると、このクエリが実行されます。しかし、今回は列の詳細を正しい値を入力していないので、このまま実行することはできません。
では、列の詳細を正しく入力した場合に、実行して期待するデータの取り込みに成功できるかというと、残念ながら成功できませんでした。
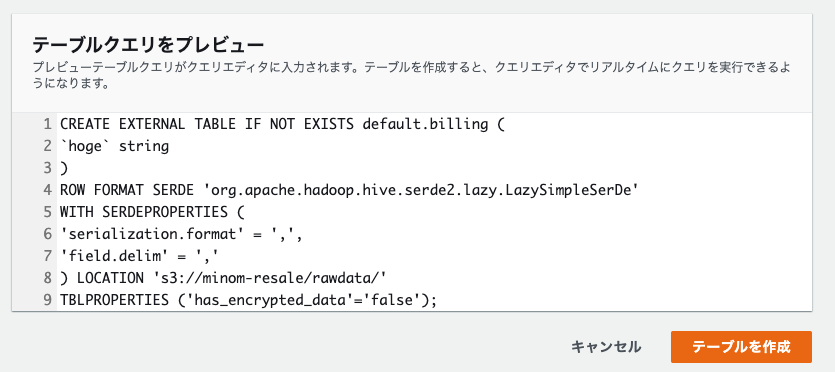
では、このクエリをコピーしメモ帳などに書き残して、キャンセルをクリックし、クエリエディタの画面に戻ります。クエリエディタで「CREATE TABLE...」というS3からデータを取り込むクエリを記入し実行することもできます。先に答えから言うと、当社の利用明細を取り込む場合のサンプルクエリが以下になります。
CREATE EXTERNAL TABLE IF NOT EXISTS billing.billing_table ( `accountid` string, `invoicedate` string, `productcode` string, `productname` string, `usagetype` string, `operation` string, `itemdescription` string, `usagequantity` double, `costbeforetax` double, `invoicestatus` string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( 'serialization.format' = ',', 'field.delim' = ',' ) LOCATION 's3://*<バケット名>*/rawdata/' TBLPROPERTIES ( 'has_encrypted_data'='true', 'skip.header.line.count'='1' );
先ほどの自動生成されたクエリと比較していきます。
項目名をhogeとしただけだった部分を当社の利用明細に従って整えています。それ以外に2点注意するポイントを紹介します。
一つ目は先頭行は無視するかどうかの設定です。利用明細の1行目は項目名なので無視することが適切なので自動生成クエリではなかった、この一文が必要です。
'skip.header.line.count'='1'
二つ目は、まず、前置きの説明をします。CSV形式のデータはカラム内に「,(カンマ)」や改行コードが含まれている場合に「"(ダブルコーテーション)」で囲むことで区切り文字のカンマではないことを示す記法があります。例えば、今回のデータの場合、利用明細の利用量などでは「1000000」とは表記せずに「1,000,000」と表記されるので先述したダブルコーテーションを無視すると「1」「000」「000」が別々のデータとして処理されてしまいます。
前置きが長くなりましたが、自動生成の場合は、ROW FORMAT SERDEはLazySimpleSerDeとなっています。今回の利用明細を扱うためにはサンプルで記載したOpenCSVSerdeを指定する必要があります。
自動生成クエリ ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
サンプルクエリ ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
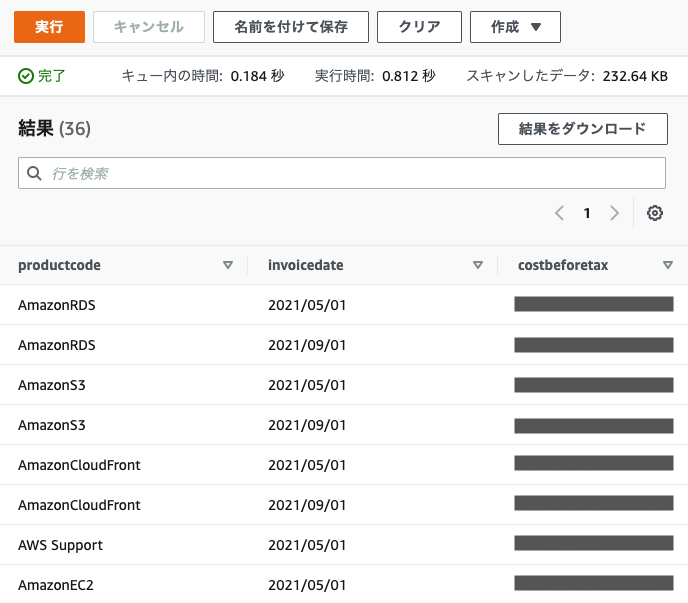
さて、これで利用明細がAthenaに取り込まれたはずです。早速、確認をかねてクエリを実行してみましょう。
SELECT productcode, invoicedate, sum(costbeforetax) AS costbeforetax FROM default.blog_rawdata GROUP BY productcode, invoicedate ORDER BY costbeforetax desc, invoicedate LIMIT 50;
クエリの実行結果はクエリエディタ画面を下にスクロールすると表示されています。5月と9月の利用明細をアップロードしていたので、このような結果が表示されています。利用明細の取り込みは成功したようです。
AWS利用明細を扱う場合の注意事項
最後にAWS利用明細を取り込む場合の注意事項を共有します。
サンプルクエリの「列の詳細」に該当する部分を修正することでCREATE TABLEクエリ自体は成功するかもしれませんが、確認クエリを実行すると失敗すると思います。原因は複数あります。
まず、invoicedateなどの日付データが当社の利用明細と違って時間(00:00:00)も含まれているためにdate型では取り込めません。string型にすることでCREATE TABLEクエリは成功しますが、日付として扱うには変換処理が必要です。
また、usagequantityが空になっていることがあります。その状態で確認クエリで参照しようとすると以下のエラーで失敗します。
HIVE_BAD_DATA: Error parsing column 'n': empty String
これもdouble型の変数で処理する場合にも変換処理が必要です。これらについては、また、別の機会に書こうと思っています。
松下 稔 (Minoru Matsushita) 記事一覧はコチラ
クラウドインテグレーション部SRE3課
かれこれ入社8年目を迎えました。
数字集計をExcelからAthenaに置き換えられないか模索中。