

Day1に開催された、 "S.P.E.C. - Serverless Performance Empowerment Challenge" というワークショップをご存じでしょうか?
※開催概要はこちら
ざっくり言うとISUCONのようなパフォーマンスチューニングコンテストのサーバーレス版です。参加者にお題となるアプリケーションが配られ、時間内にアプリのパフォーマンスを改善します。ベンチマーカーへの応答性能によって獲得スコアが算出され、スコアの合計をチーム間で競い合います。
私はこの企画のお手伝いとして、ランキング表示をリアルタイムに行うごく簡単な参加者向けポータルの実装をやっていました。
こんなの↓
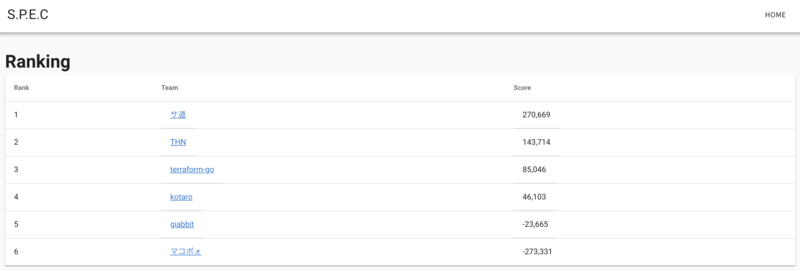
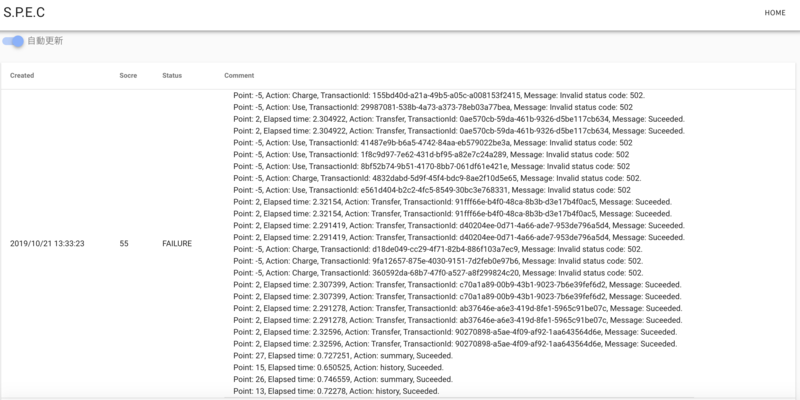
実装はAWS Amplify & Amplify CLIを使っています。バックエンドはAppSync(GraphQL)です。
AmplifyもGraphQLも経験ほぼ皆無の状態からのスタートでしたが、なんとかイベント自体が成立するところまで持っていけたのは中山さん(@k1nakayama)の多大なサポートによるところが非常に大きいです。ありがとうございます。
レポートブログはこのWorkshopの主催である弊社の照井(@marcy_terui) が以下の記事を書いているので、そちらをご覧ください。
ServerlessDaysでServerlessなパフォーマンスチューニングコンテストを開催しました #ServerlessDays
このブログでは、ポータルサイトの実装をやってみての感想とか、技術的な面での振り返りをレポートしようと思います。
追記 (2019.11.22)
コンテストに使用したソースを公開しました。
アプリ概要
構成図はこちら。
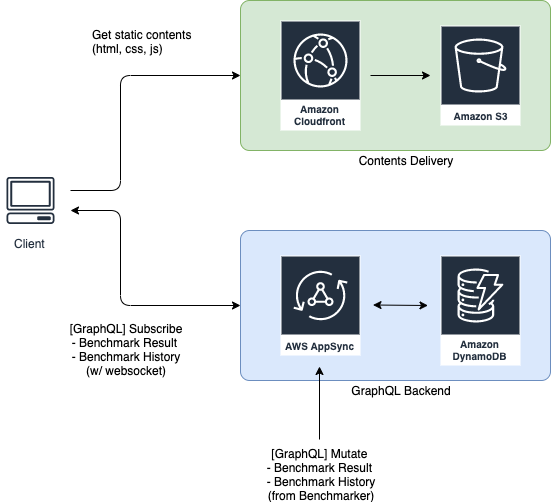
ごくごくシンプルな構成になっています。ポータル側ではMutationを行わず、ベンチマーカーが各チームに対して実行したベンチマークの結果を書き込みます。ポータル側ではそれをSubscribeして画面に反映します。
データアクセスの要件と(開催日時点での)設計
ランキングポータルから見ると、データアクセスの要件は以下の2通りです。
- チームごとに獲得点数の集計結果を表示
- チームごとにベンチマークの各試行ごとの結果を表示
ベンチマーカーは 「APIリクエストN回を1つのセットとして、各チームごと、一定間隔ごとに1セットを実行」 という挙動をします。競技時間を通して継続的に実行されます。
ベンチマークのランキングポータルなので、当然ベンチマーク結果を集計してランキング表示する仕組みが必要です。また、競技者が今のアプリの問題点を考察するためにはベンチマーカーが各試行で出力した結果が閲覧できることも(限りなく必須に近い)要件と言えます。よって、ベンチマークの各試行に関するデータとその集計結果をデータストアは持っている必要があります。
開催日時点の設計は以下のようになっています。
- 集計済みデータとベンチマークヒストリを管理するテーブルをそれぞれ用意し、独立に管理する
- 各チームごとのベンチマークの集計を格納するためのテーブル
- ベンチマークのヒストリを格納するためのテーブル
- ベンチマーカーは1セット分の結果を2回に分けてMutationsする
- 結果集計に反映するためのMutation
- 1セット分のベンチマーク結果のヒストリを投げるためのMutation
苦労したこと
上記のデータアクセスの要件に基づいて、GraphQLのスキーマやデータストアをどう設計するのか?という部分に苦慮しました。また、Amplify CLIでいい感じに構築できる範囲にも限りがあり、事前検証の段階でかなり難儀しました...。そのへんの検討事項・制約(あと時間的な猶予)と戦いつつどう現実的な実装に落とすかというのが大きな課題であったように思います。
前述の設計はおそらく一番手短にやれる現実解だったのかなと思いますが、設計としてはまだまだ改善余地があると思っています。以降で「どうあるべきだったか」の所感を述べます
どのような改善が考えられるか
まだ私も自信があるわけではありませんが、改善案を挙げるとするなら以下のように考えると思います。
案1 - パイプラインリゾルバを使う
ベンチマーカーから「1回分のベンチマーク結果」を「集計更新用のMutation」「ヒストリ追記用のMutation」の2つに分けて投げる実装になっているのは無駄な感じがあります。1回で済ませられる設計の方がベターに見えます。
手っ取り早い方法としては、パイプラインリゾルバを使うのが良さそうです。
ヒストリ追加のMutationと集計反映用のMutation、いずれも入力の引数はほぼ共通なので、Mutationを統合してパイプラインリゾルバの1段目に集計用のVTL、2段目にヒストリ追加用のVTLを挟むことでベンチマーカーからのMutationが1回で済むようになります。
案2 - DynamoDBテーブルを1つに統合する
裏のDynamoDBテーブルは、集計結果用とヒストリ用で分離していました。これを単一のテーブルに統合します。テーブルを統合することでパーティションごとのI/Oが均され、キャパシティの利用効率改善が見込めます。
インデックスの設計どうするのかは悩みどころではありますが...おそらくは「集計結果」のアイテムと「ヒストリ」のアイテムを "RecordType" のようなキーで区別する仕様とし、GSIのうちひとつはRecordTypeをHASH KEYに持つような設計を採ることになると思います。
これ、設計案としては念頭にあったのですが、リゾルバのマッピングテンプレートをはじめとするGraphQL側を合わせる手間を含めたら割と面倒くさそうなので、時間的な猶予から採用は見送りました(負け惜しみ)
まとめ
今回のイベントを通しての感想です。
開発経験が豊富なわけでもなく、採用する技術スタックにも明るくない状態からのスタートでしたが、実際にアプリを立ち上げて使ってもらうところまでの体験を通せたのは非常に良い経験になりました。
繰り返しになりますが、曲りなりにも開発をやり仰せたのは中山さん(@k1nakayama)のご助力あってのことです。本当にありがとうございました。
また、照井さん(@marcy_terui)も素晴らしい企画をありがとうございました。次回もこの企画があるかはまだわからないですが、あれば是非また携わりたいなと思える企画でした。次回までに作問にも関われるくらいのスキルを身に着けたい...!
最後に、S.P.E.Cにご参加いただいた参加者の皆様、本当にありがとうございました。この場をお借りして感謝申し上げます。 決して良いUI/UXのアプリではなかったと思いますが、企画としてご満足いただけたならば運営側の人間としては幸甚です。今回開発したポータルのソースはなる早で公開したいのですが、まだ整備が行き届いておらず、もうしばしお待ち下さい..🙏
余談
余談として、設計改善案の(3)を追記しておきます。
見解としては却下寄りのなので余談扱いとしましたが、この案に近い話って割とよくあるパターンだろうなと思いましたので参考までに。
サーバーレスの世界、まだまだ私には難しい...。
※ ... 今回のアプリの事情だと以下で述べる案(3)はあまりイケてないだろう...というだけの話なので、要件や構成が違えばこれも正解のひとつになりうるとは思ってます
案3 - 集計計算と結果の永続化処理を専用のlambdaに切り離して追加実装する
集計処理は、ヒストリテーブルを外部のscheduled lambdaから定期的に叩いて計算し、lambdaから集計結果テーブルに格納するようにしよう、という考え方です。
計算開始をトリガーする役目と集計の実処理が集計用lambdaに切り出されます。このため、ベンチマーカー側からのmutationは集計更新用Mutationが不要になりヒストリ追記の1回分だけで済むようになります。
この案の是非については照井にも見解を聞いてみましたが「微妙」とのことです。「AppSyncも含めフロントエンドはできるだけシンプルに利用すべきであり、ロジックの複雑さはできるだけバックエンドサービスに寄せていく設計のほうが正解なのではないか?」との回答もありました。なるほど、さもありなん...。
※ ... 知ってる方にとっては割と当然かと思いますが、このlambda functionの中でDynamoDBをscanするのはアンチパターンです。計算量がデータ量に比例する実装になってしまい大変非効率ですし、無駄なscanはするべきではありません。設計次第でscanは回避可能です。
私なりの見解としては、この案のメリットは以下の通りと考えます。しかし、代替案があったり、本アプリの要件に照らしてさほどマッチしなさそうだったりで、採用の意義が薄いと思っています。
- UI側で「ランキングとヒストリの更新頻度を個別に扱いたい」という追加要件を想定し得る場合に柔軟性がある
- DynamoDBの負荷が軽減できる(ヒストリが1件追加されるごとに集計処理を実行する実装と比べた場合)
(1)は、もし本当にこの要件が想定されるのなら集計lambdaの検討価値もあると思います。が、実際には「想定する必要のない過剰想定」でしょう。「ユーザーが目で追える程度の、適度な速度で」描画が更新できていればUIとしては最低限OKだと思ってます。また、描画更新の頻度をコントロールしたければ「ベンチマーカー側でkinesisを噛ませてバッチ単位にまとめてからmutationを投げ込むようにする」というアプローチも考えられます。集計lambdaを噛ませる必然性はないです。
(2)は、今の実装と比べた場合だとさほど大きなメリットが感じられません。よって却下です。
※ ... 今の実装は「集計処理」自体が不要になるように設計しています。チームの獲得スコアの更新は、UpdateItemで「合計スコアの差分更新」を行うことによって実現しています。
橋本 拓弥(記事一覧)
プロセスエンジニアリング部
業務改善ネタ多め & 開発寄りなコーポレートエンジニアです。普段は Serverless Framework, Python, Salesforce あたりと遊んでいます