

[MSP/AWS運用代行] チケットシステムのデータから、異常事態にある案件or環境を検出する
こんにちは、マネージドサービス課の橋本です。
先日執筆した[MSP/AWS運用代行] 簡単なデータ集計と可視化を使って運用の改善を考えるの関連記事です。データで運用を改善しようぜ、っていう趣旨のシリーズとして御覧いただけると幸いです。
今回も運用現場の方が対象読者です。
この記事では、ごく簡単な外れ値検出を実際の運用現場のデータに応用してみました。
前置き
CPUやメモリ、ディスクなど、所謂「リソース系」のアラートって多いですよね。当社のMSPサービスでもそうです。
リソース系アラートにおいて、即応レベルの事象が発生することは(発生頻度的に)稀です。本当にアラートして欲しいのは真に対応の必要な障害事象、もしくは深刻なリソース不足を引き起こす「予兆」などであり、リソース状況そのものではないはずなのですが、そうした理想の監視(業務フローへの反映まで含めて)実装するのはハードルあるよねぇ、などなど諸般あって簡単にはいかないことも多いかと思います。
依然として、「大量発生する緊急度低のリソースアラート」とは当面お付き合いを続ける必要がありそうです。とはいえ、それらを毎日全部パトロールする...というのも、進んでやりたいことではないです。緊急度が低いアラートであれば、必要がありそうなときだけチェックするという感じで処理できると実務的にはありがたいのかなと思います。
この「必要がありそうなときだけ」というシーンを、機械的にうまいこと判別できないだろうか?というのが本記事のテーマです。
やったこと
上で述べた前置きを実現するひとつのアプローチとして、今回はアラート発生件数の時系列データを使った外れ値検出をやってみました。平常時よりもアラートが多く発生している状態を検知します。
このネタは、「平常時より明らかに多くのアラートが挙がっている状態」を「何らかの異変の可能性」として仮定しています。大量のリソースアラートをノーヒントで眺めるよりは、見るべき対象を絞り込むのに役立つかなと。一方で、アラート件数を一度集計する必要があることから即時性には欠けます。障害対応の用途で役立つものではないので、そこはまた別な議論が必要かなと思っています。
使用したデータですが、案件ごとに日次アラート発生件数をカウントした時系列データを使っています(※)。データの粒度は好きなように設定して良いです。当社はMSPベンダーなのでひとまずは「案件ごと」を集計単位としましたが、システム単位で見ても同じ理屈は成立します。ただし、0件ばかりが並ぶ時系列データになってしまうようだと機能しづらいので、ある程度コンスタントに件数が取れる粒度であるほうが望ましいです。
※ ... 厳密にはアラート件数そのものではなく、チケット管理システム(Zendesk)上に起票されたアラートのチケットを数え上げています。このあたりは以前の記事でもご紹介した、S3+Athenaを中心とするデータ基盤の存在が前提となっています。
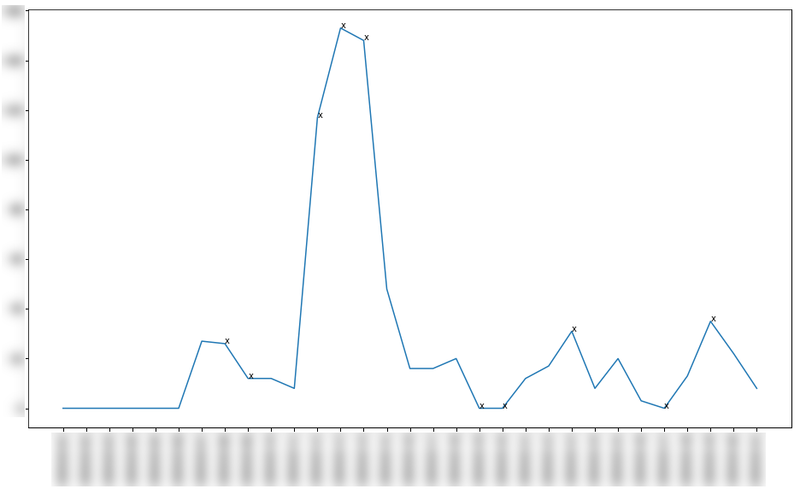
判定ロジックはかなりシンプルです。判定対象日から起算して過去N日(Nは任意の非負整数)のチケット発生数を抜き取り、その平均と標準偏差を出します。平均±標準偏差×α (αは偏差の許容範囲を意味する任意の実数)の範囲を正常値とし、実際の観測値がその範囲外であれば外れ値として扱う。これだけです。
下記が実際の図。横軸は日付、縦軸はアラートの発生数です。 x がついている場所が外れ値判定された日を示します。ここではN=7としており、8日目以降に対して外れ値判定を適用しています。
プロトタイピング
上記のような感じで、検知のロジック部分は実装することができました。次は現場に見える形でそれをアウトプットする必要があるので、ごく簡単なプロトタイピングを行ってみました。
時系列のデータ収集&整形と検知ロジックを実装したローカル用のコマンドラインツールを作成し、そのツールが生成する結果をSlackにポストしてみました。遡る過去期間の幅や外れ値判定の範囲などは引数でコントロール可能な作りになっています。
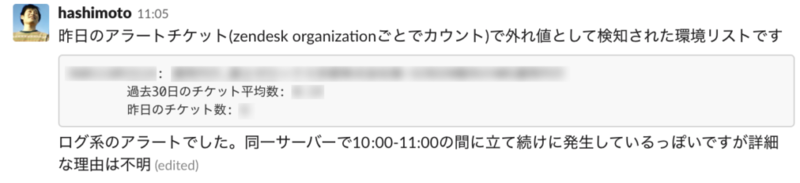
検知された環境についてはできるだけ実際のアラート本文を確認し、簡単に私なりのコメントを入れてみるようにしています。関係者のアンテナに引っかかりやすくなったらいいな、という意図です。
理想的には全部LambdaやらDynamoやらに乗せて全自動にしたいところですが、有用性が示せないうちから実行環境に手をかけすぎてもしょうがないので、今は手作りの感あふれるスクリプトを片手に毎日手作業で検知と通知を行っています。
所感とあとがき
気持ち程度に数学要素を書いておきます(はいえ筆者は数学にさほど明るくないので、識者の方からのツッコミがあればぜひお伺いしたいです)。
まずは外れ値の判定部分について。
執筆当時のやり方では、対数系列をベースにして平均と分散を算出し、分散値を元に正常範囲を上下で決めていました。対数系列を取ったのは観測値が(上方向に)ピーキーな変動を取ることが割とあることを鑑みたものですが、今はまた違うやり方になっています。
今のロジックでは、使用するのは原系列です。外れ値判定には 観測値 >= (平均 + 許容偏差) という式を使っています(「許容偏差」は平均値の平方根に対して任意の実数係数を掛けたもの)。この式にした意図は次の2点です。
- 関心があるのは「普段より異常に多い」状態のみなので、下側(減少)の変動を判定に加味する必要がない
- 発生頻度の分布がポアソン分布に近いことを仮定した(許容偏差の部分に反映されている)
※ポアソン分布の分散は平均に等しいです。よって標準偏差は「平均値の平方根」となり、これを「許容偏差」の部分に当てはめています。
きれいなポアソン分布にならない環境も多々ありましたが・・・とりあえず今はこの仮定のもとでやっています。サンプルによってはパラメータの異なるポアソン分布を重ねたような、多峰性の分布が得られることもあります。
今後のアクションですが、とりあえず最低限のプロトタイピングは作ってしまったのでしばらくは様子見です。検知されるのを待ちつつ実際の現場にフィットするかどうか、実地検証で有用性を測ってみようと思います。