

こんにちわ。技術3課のすぎたにです。
入社して半年がたちましたが、次から次へと新しいAWSプロダクトに触れる日々を過ごしております。
そんな中で、今回は AWS Data Pipeline を使うことになりました。 まずは、初めのいっぽ・・・的な例をブログにしてみたいと思います。 # AWS Data Pipeline って何よ・・・ プロダクトのTOPページ AWS Data Pipeline にもある通り、 > 指定された間隔で、信頼性のあるデータ処理やデータ移動(AWS のコンピューティングサービスやストレージサービス、ならびにオンプレミスのデータソース間)を行うことができるウェブサービス ・・・との事です。
またそれだけでは無く、AWS Data Pipelineでデータ処理やデータ移動を行った場合、耐障害性のある繰り返し機能を利用できたり、処理が失敗するか正常終了するとAmazon SNS 通知メッセージを送信できるので、AWS Lambdaなどの他のサービスと連携したシステムを構築することができます。
いわゆる ETL(Extract,Transform,Load)を行うサービスのようです。 # 簡単なところから試してみた〜 ということで、まずは簡単に特定のS3バケットにあるCSVファイルのデータを取得し、RDS MySQLの特定のテーブルに insert するという事を試してみました。 ## S3バケットにあるcsv形式のデータをRDS MySQL のテーブルにロードしてみる。  とーっても簡単な例ですが、まずはこのあたりから AWS Data Pipelineをつかってみたいと思います。 ## テストに使うデータのレイアウト - 入力側(S3 Backet) | csvレコードレイアウト(ファイル名:test.csv) |--- |日付文字列 |ID文字列 |DATA1 |DATA2 |DATA3 - 出力側(RDS MySQL) | テーブルレイアウト(テーブル名:tbl_test_datapipeline)
とーっても簡単な例ですが、まずはこのあたりから AWS Data Pipelineをつかってみたいと思います。 ## テストに使うデータのレイアウト - 入力側(S3 Backet) | csvレコードレイアウト(ファイル名:test.csv) |--- |日付文字列 |ID文字列 |DATA1 |DATA2 |DATA3 - 出力側(RDS MySQL) | テーブルレイアウト(テーブル名:tbl_test_datapipeline)
プライマリーキー:entry_date+entry_id |--- |entry_date varchar(64) |entry_id varchar(64) |data_1 int |data_2 int |data_3 int ## Pipelineの定義をする(お手軽にテンプレートからの定義) ### テンプレートの選択 ここから目的の処理を行うためのPipeline定義をしていきます。まずは、マネージメントコンソールのホームから Data Pipelineを選択して、Create New Pipeline クリックしてください。 以下の様な画面が表示されると思います。  上記画面にて、次の操作を行います。
上記画面にて、次の操作を行います。
| Name | テキストボックスに今から作成するPipelineにつける名称を入力して下さい。 |
| Source | `Build using a template` のラジオボタンを選択して、その下にあるプルダウンメニューから、`Load S3 data into RDS MySQL table` を選択して下さい。 (ここに各種のテンプレートがあり、目的に近いテンプレートを選べば、後にPipelineの定義を修正して目的の処理を完成させる事が出来ます。) |
テンプレート選択後は Parameters の入力内容が変わります。そのそれぞれに以下の内容を設定します。 ※datapipeline-test-data は例となるバケット名です。
| RDS MySQL password | RDS MySQL を作成したときに設定したパスワードを入力します。 |
| Input S3 file path | S3のファイルパスを入力します。 |
| RDS MySQL username | RDS MySQL作成時のusername |
| Insert SQL query | S3にあるcsvデータをテーブルにinsert するときのSQL文 |
| RDS MySQL table name | S3にあるcsvデータをinsertするテーブル名 |
| RDS Instance ID | RDS MySQL作成時 `DB Instance Identifier` に設定した名称。End Point名の初めのドットから左側の部分と同じ。 |
| Create table SQL(optional) | Create table するときのSQL文。(手動などの方法で作るならば、ここの設定は不要) |
上記画面 Parameters のところは次の様に設定されています。 | parameter名称 | 値 | | ------ | -------- | |RDS MySQL password|RDSインスタンス作成時に設定したマスターパスワード| |RDS MySQL security group(s) (optional)|なし| |Input S3 file path|例)s3://datapipeline-test-data/data/mini_SampleData_1.csv| |RDS MySQL username|RDSインスタンス作成時に設定したマスターユーザの名前| |Insert SQL query|例)※1 下記参照
プレースホルダ「?」でvaluesの部分を記述する| |RDS MySQL table name|例)tbl_test_datapipeline| |RDS Instance ID|例)kensyou-201701| |Create table SQL query (optional) |例)※2 下記参照| - ※1 Insert SQL query sql insert IGNORE into tbl_test_datapipeline ( entry_date, entry_id, data_1, data_2, data_3 ) values ( ?, ?, ?, ?, ? ); - ※2 Create table SQL query sql CREATE TABLE IF NOT EXISTS `tbl_test_datapipeline` ( `entry_date` varchar(64) NOT NULL DEFAULT '', `entry_id` varchar(64) NOT NULL DEFAULT '', `data_1` int(11) DEFAULT NULL, `data_2` int(11) DEFAULT NULL, `data_3` int(11) DEFAULT NULL, PRIMARY KEY (`entry_date`,`entry_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; - テストデータとなるcsvファイルの例 2017-03-16T19:59:25+09:00,testId_142,6448,10204,11819 2017-03-16T19:59:26+09:00,testId_574,9276,1731,551 2017-03-16T19:59:27+09:00,testId_556,14736,17093,9847 2017-03-16T19:59:28+09:00,testId_317,27081,25735,27526 2017-03-16T19:59:29+09:00,testId_303,15312,21387,20216 2017-03-16T19:59:30+09:00,testId_477,8051,25501,25646 2017-03-16T19:59:31+09:00,testId_533,19930,179,23426 #### Parametersより下のその他の設定
| Schedule | 定期的な期間の特定の時間にパイプラインの処理を動かすときは `on a schedule` に設定します。今回はこちらのタイミングで都度パイプラインを動作させたいので `on activation` にしました。この後、パイプラインに対して `Activation`ボタン押下での実行時のみパイプラインが動作します。 |
| Pipeline Configuration | Logging の部分を`Enable`にするとData PipelineのログをS3に保存することが出来ます。とりあえずトラブルシューティングに役立てることができるかもしれないので設定します。 例)s3://datapipeline-test-data/logs |
| Security/Access | とりあえず、S3とRDSを使うぐらいなら `Default`で問題無しです。 |
| Tags | 必要に応じて設定して下さい。(今回はなし) |
設定がおわったら 画面右下に Edit on ArchitectボタンとActivateボタンがあります。
| Edit on Architect | Data Pipelineの詳細設定をする画面に移ります。 |
| Activate | 設定した項目のバリデーション後、問題がなければ設定したData Pipelineが実行されます。 |
今回は続きの細かい設定が必要だったので、Edit on Architectを選択します。 #### Data Pipelineの詳細設定画面 次に以下の様なData Pipelineの詳細設定をする画面が表示されます。 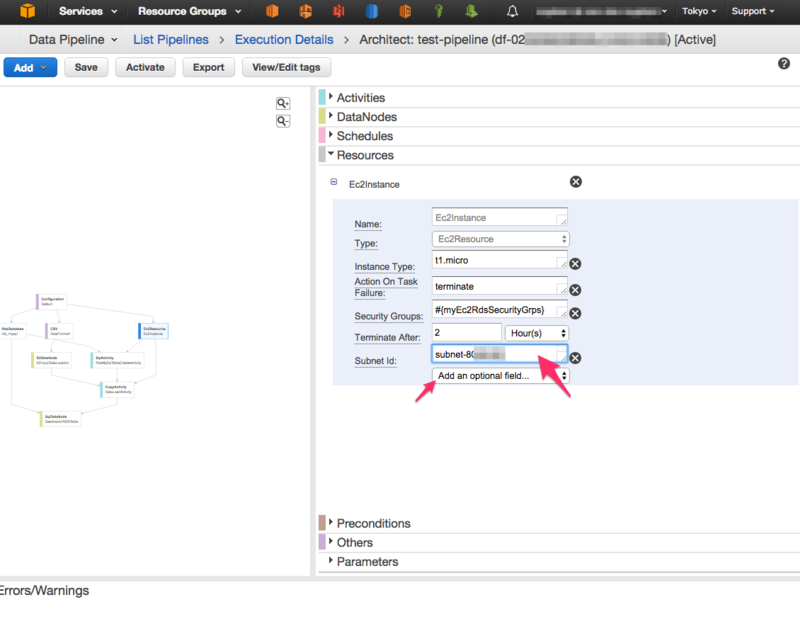 ここで今回1つの追加設定が必要でした。 RDSはVPC内のsubnetに作成しているのですが、Data PipelineをActivateして動かしたときに、Data Pipelineの作業をするリソースが必要となります。(Data Pipeline の概念 » リソース )
ここで今回1つの追加設定が必要でした。 RDSはVPC内のsubnetに作成しているのですが、Data PipelineをActivateして動かしたときに、Data Pipelineの作業をするリソースが必要となります。(Data Pipeline の概念 » リソース )
今回はEC2をリソースとして使うわけですが、EC2がRDSに接続できる環境にある必要があります。ですので、今回は簡易的にRDSのサブネットにEC2が自動的にLaunchされるようにしました。
上記画面の様に Resources → Ec2instance の最下部にある Add an optional field...をクリックし Subnet Idを選択します。そして新たに作成されたSubnet Idフィールドに、RDSの存在するSubnet IDを設定しました。これでRDSインスタンスの存在するサブネットにEC2が作成されることになります。
画面最下部にはErrors/Warningsが表示される画面があります。設定を保存する為のsaveを行った時などに表示される場合があります。今回、Roleに関するWarningがありましたが、問題無しとして進めています。
saveボタンを押してDataPipelineの実行に問題が無いなら以下の様な確認画面が表示されます。 
Activateボタンを押下するとData Pipelineが実行されます。
ListPipelinesの画面に移り、Schedule StateがSCHEDULED On Demandになっているパイプラインがありますので、そのパイプライのPipeline IDリンク部分をクリックするとExecution Detailsが表示され動作状況が確認できます。
以下の様にStatusがFINISHEDになれば処理が完了したことになります。  Data Pipelineの動作が始まった後・・・ * EC2のLaunch * 実際のデータの処理 * 処理後、EC2インスタンスのターミネート 以上が完了して処理終了となるので、少量のデータ処理でも
Data Pipelineの動作が始まった後・・・ * EC2のLaunch * 実際のデータの処理 * 処理後、EC2インスタンスのターミネート 以上が完了して処理終了となるので、少量のデータ処理でもFINISHEDが表示されるまで3〜5分かかる感じです。 # 最後に・・・ いろいろ手間取った部分もありますが、無事にRDSにデータがロードされたようです。
各種クライアントツール(MySQL Work Benchなど)や、コマンドラインなどでRDSにアクセスして確認してください。  > csvテストデータとして日時データを扱っている部分はISO 8601形式ですが、MySQLテーブルのフィールドを文字型
> csvテストデータとして日時データを扱っている部分はISO 8601形式ですが、MySQLテーブルのフィールドを文字型varchar(64)にしていますので、csvデータと同じ文字が表示されています。
このフィールドをdatetime型にすると、YYYY-MM-DD HH:mm:ssのフォーマットでデータが格納されます。
さて・・・これだけでは面白く無いこと確実なような気がするので、次回はもうすこし発展させた形で使う、AWS Data Pipelineの続きのブログを書きたいとおもいます〜