

技術2課の白鳥です。
AWS Lambda が発表されて以後、クラウド界隈ではサーバレスアーキテクチャという考え方が広まっています。で、私はとりあえず、学生時代に研究していた流体画像処理をサーバレスにしてみました。最近は遺伝的アルゴリズムをサーバレス分散処理で動かそうと目論んでいます。まだサーバレスにも分散処理にもできていないのですが orz これまでの進捗をまとめてみます。
用語の説明
巡回セールスマン問題 とは
あるセールスマンが、いくつかの都市を1回ずつ訪問して、スタート地点の都市に戻ってくるとします。各都市間の距離は分かっているので、なるべく総移動距離が短くなるように、都市を回る順番を決めたい、みたいな問題です。
この問題の厄介な点は、「訪問する都市の数が増えると急激に難しくなっていく」というところです。例えば、A, B, C, Dという4つの都市しかなく、セールスマンのスタート地点がAの場合は、都市を回る順番は実質
- A - B - C - D - A
- A - B - D - C - A
- A - C - B - D - A
の3通りしかありません。3通りくらいであれば「3通り全て調べて、総移動距離が最短になる順番で訪問しよう」と思えます。しかし、都市数が増えると、この順番のパターン数が
| 都市数 | 都市を訪問する順番 |
|---|---|
| 5 | 12通り |
| 7 | 360通り |
| 10 | 約18万通り |
| 12 | 約2000万通り |
| 15 | 約400億通り |
と、狂ったように増えていきます。したがって都市数が増えると、たとえ計算をコンピュータにやらせたとしても「全て調べて、総移動距離が最短になる順番を見つける」という方法は現実的ではなくなります。そこで「一部のみを調べて、そこそこ移動距離が短くなる順番を見つける」という方法をとることになります。ちなみにこれは じゅず順列 のケースとなるので、都市数が N のとき都市を訪問する順番は (N - 1)!/2 通りになります。
遺伝的アルゴリズム とは
このように、膨大な組み合わせの中から、そこそこ良さそうなものを短時間で見つける際に使われる手法の一つが、遺伝的アルゴリズム(Genetic Algorithm, 以下 GA )です。巡回セールスマン問題を例にすると、以下のようにして「そこそこ良さそうなもの」を見つけてきます。
- 都市を回る順番をランダムに何パターンか生成する
- それぞれの総移動距離を計算する
- 移動距離が比較的短いもの同士を組み合わせ、都市を回る順番を新たにに何パターンか生成する
- 2. 3. を繰り返す
こうすることで、膨大な組み合わせのうちの一部を調べるだけで、そこそこ妥当な結果を見つけてくることができます。このアルゴリズムを達人たちが使うと、スーパーマリオをクリアしたり、ブランコの漕ぎ方を学習させたりできるようです。
実際にやってみた
ここからは静岡理工科大学 菅沼義昇先生の研究室のWebページ を参考に、GAで巡回セールスマン問題を解いてみます。4.4.3に、GAを使って解く例題として巡回セールスマン問題が挙げられており、詳しいパラメータも公開されているので、これに条件を合わせて試してみます。
都市の生成
上記の例題では、都市の位置の座標データまでは公開されていないようので、都市の位置を適当に決めるところから始めます。今回は random_cities.py というスクリプトをつくり、ランダムに都市の位置を決めました。 都市数は例題に合わせて50都市とし、-1 < x < 1 および -1 < y < 1 の範囲で (x, y) を各都市にランダムに与えました。その結果を city_info.json として書き出しました。これに記載の50個の点(= 都市)を効率よく巡回する経路をGAに探してもらいます。
先ほどの式(N - 1)!/2 に N = 50 を代入してみると、答えは約 3.04 × 1062 になります。3の後ろに0が62個ついている数になります。日本語の数の数え方では300那由多というそうです。
とりあえず例題に近い条件で実行
今回実行させたGAは traveling_salesman.py になります。ただし、計算結果をS3に保存するため、実行するEC2にS3への十分なアクセス権限のあるIAM Roleが与えられている必要があります。またこのまま実行すると、GAによる計算履歴が 1GB くらいの json で書き出されるので注意してください。
まずは例題に近い条件として
population = 100 #集団サイズ
generation = 10000 #世代数 elite_rate = 0.1 #次世代の個体のうち、エリート選択で生成される割合
mutation_rate = 0.03 #次世代の個体のうち、突然変異で生成される割合
で実行してみます。例題では集団サイズは200ですが、将来的にLambdaで並列化することを夢見ているので、Lambdaの同時実行数の上限に合わせて100にしてあります。この計算条件で、r3.large を使って実行してみたところ、30分ほどで計算が終わり、S3に計算結果ファイルが出力されました。
図1のグラフは、横軸が世代の進行、縦軸が見つけ出された最短ルートの距離を示しています。世代が進むにつれて、どんどん短い経路を見つけ出せている様子を表しています。
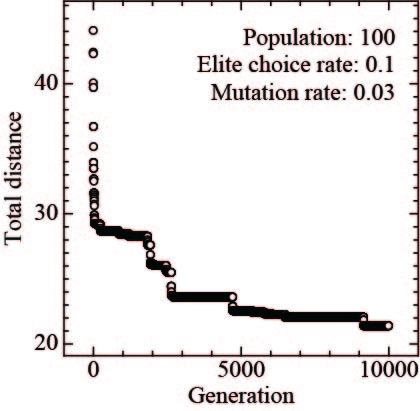
図1 各世代における最短経路の長さ (elite_rate = 0.1, mutation_rate = 0.03)
実際に学習が進んでいる様子をビジュアルに見てみます。一気に学習が進んでいる最初の200世代について、各世代の最短経路を図示してアニメーション化すると、図2のようになります。

図2 第1世代から第200世代までの最短経路の変遷 (elite_rate = 0.1, mutation_rate = 0.03)
正直「イマイチな結果だなぁ」という感想なんですが、一応学習が進んで、より短い経路を探し出せているように見えます。10000世代計算し終えたときの、見つけ出された最短経路を図3に示します。
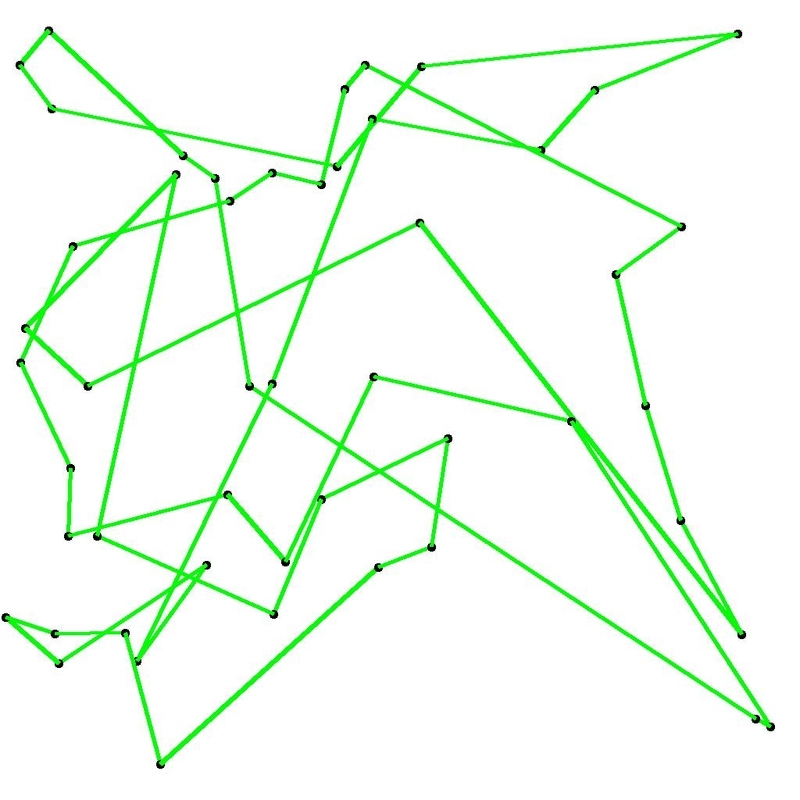
図3 10000世代計算後の最短経路 (elite_rate = 0.1, mutation_rate = 0.03)
まだまだ短い経路はありそうですが、300那由多通りもあるうち100万通りしか調べていないので、こんなもんなのかもしれません。100万通り調べるのに30分かかったということは、300那由多通り調べるには1.7恒河沙年かかることになります。
パラメータを変えてみる
もっと結果を改善できそうな気もするので、 elite_rate と mutation_rate を変えて学習させてみました。elite_rate は 0.1 から 0.4, mutation_rate は 0.03 から 0.44 の範囲で変えました。下の表は、それぞれの条件で、10000世代計算後に見つけられた最短経路の長さを示しています。数字が小さいほど、良い学習結果を出せたことを示しています。空欄の部分は、あまり良い結果を出せそうになかったので、実行していません。
| elite_rate | |||||
| 0.1 | 0.2 | 0.3 | 0.4 | ||
| mutation_rate | 0.03 | 21.38067 | 21.76859 | 23.55104 | |
| 0.06 | 18.25715 | 22.46208 | 19.34803 | 21.21988 | |
| 0.09 | 16.48598 | 17.54395 | 18.90339 | 21.04513 | |
| 0.12 | 16.21287 | 17.712 | 20.25113 | 19.90232 | |
| 0.16 | 16.03337 | ||||
| 0.2 | 17.08978 | ||||
| 0.24 | 17.08734 | ||||
| 0.28 | 16.38403 | ||||
| 0.32 | 15.21627 | ||||
| 0.36 | 16.70714 | ||||
| 0.4 | 17.03979 | ||||
| 0.44 | 13.61474 | ||||
elite_rate を変えても学習結果はあまり変わらない一方、mutation_rate を 0.03 から上げていくと、 0.16 くらいまでは学習結果が改善されていくことが分かります。 0.16 以上に mutation_rate をあげても、学習結果はほぼ変化なしです。0.44 まで上げると突然結果が改善しましたが、偶発的な結果であると考えています。 elite_rate = 0.1, mutation_rate = 0.16 の条件での計算結果について、図4 ~ 図6 に結果を示します。
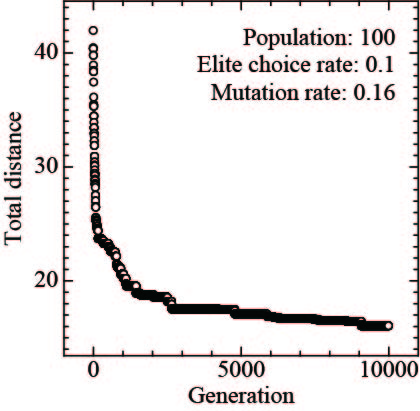
図4 各世代における最短経路の長さ (elite_rate = 0.1, mutation_rate = 0.16)
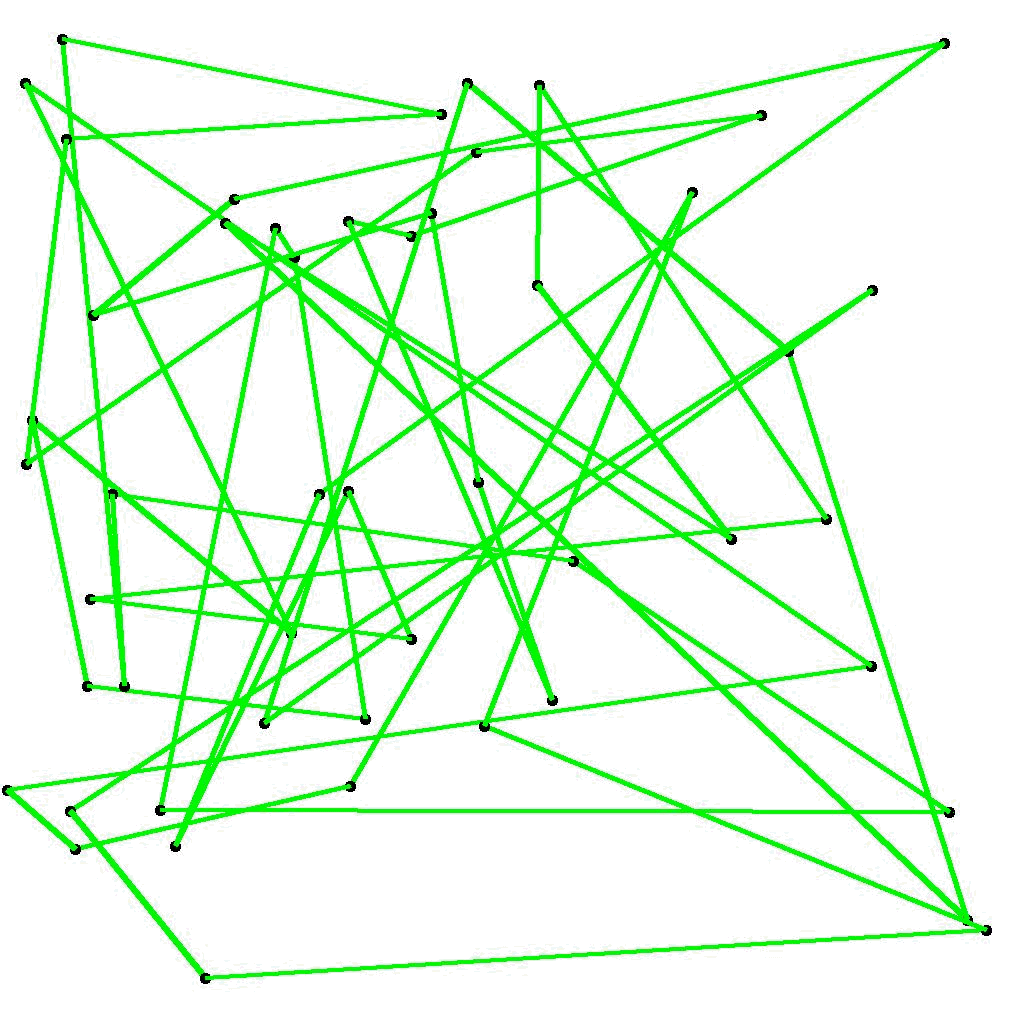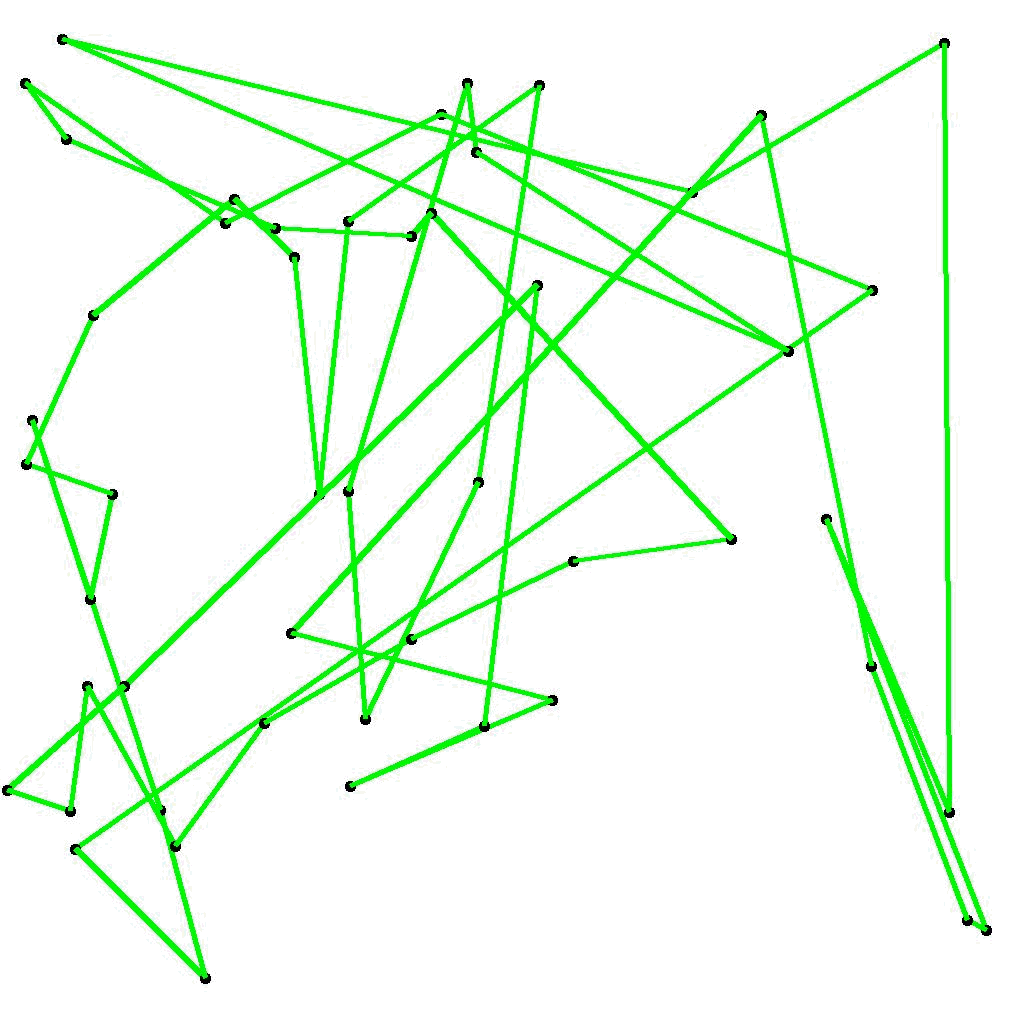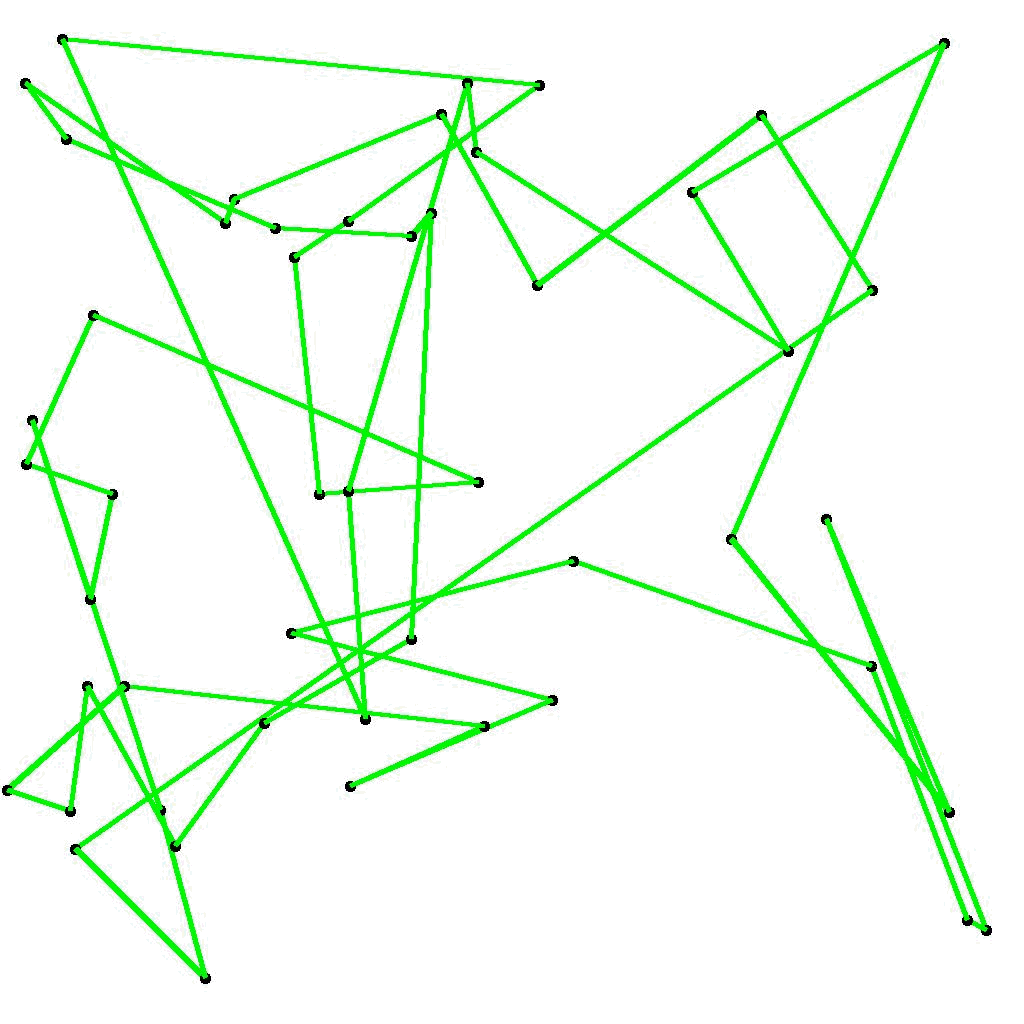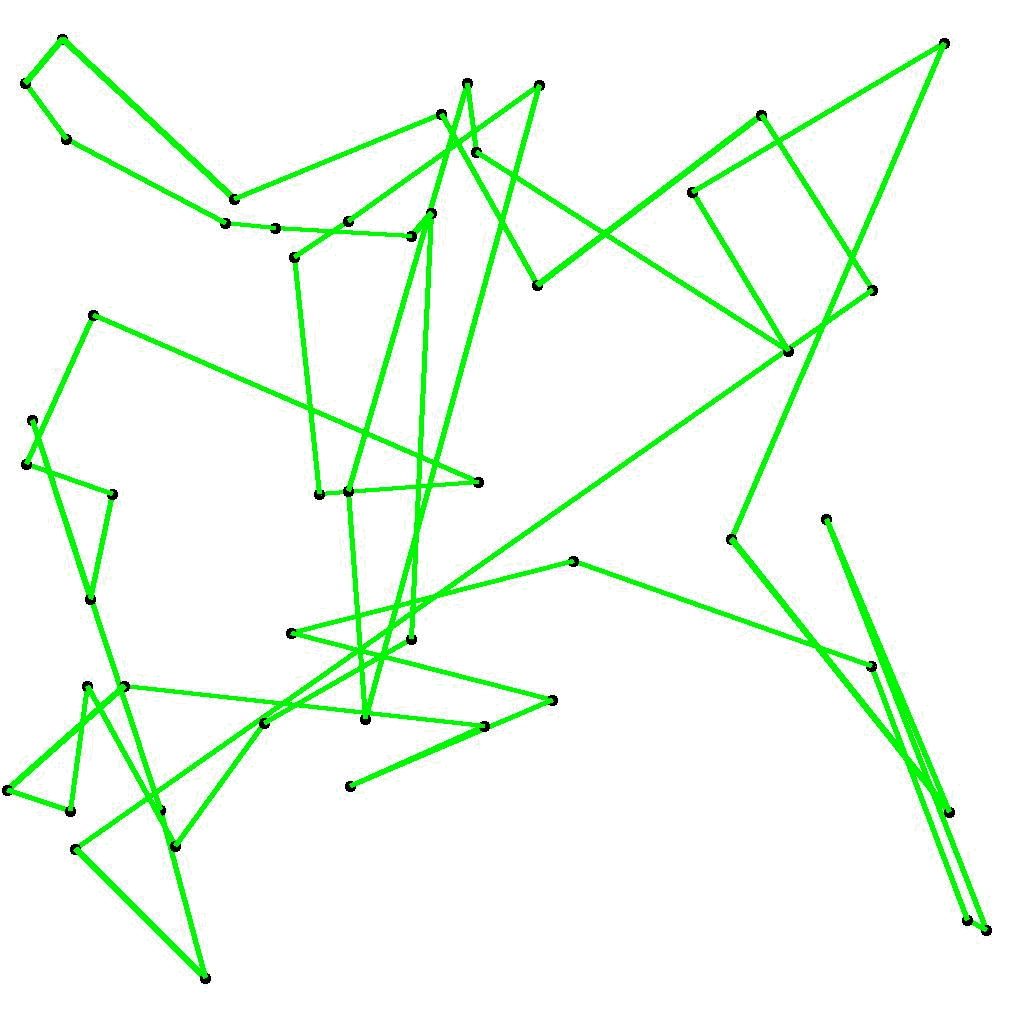
図5 第1世代から第200世代までの最短経路の変遷 (elite_rate = 0.1, mutation_rate = 0.16)

図6 10000世代計算後の最短経路 (elite_rate = 0.1, mutation_rate = 0.16)
図3と図6を比較すると、学習結果が改善したことが直観的に分かります。
まとめと感想
サーバーレスで遺伝的アルゴリズムを実現したい今日この頃ではありますが、とりあえずEC2で実行してみました。巡回セールスマン問題を解かせてみたところ、300那由多通りの経路がある中から100万通りを調べるだけで、そこそこ良さそうなものを見つけてきてくれました。エリート選択の割合(elite_rate)や突然変異の発生割合(mutation_rate)を適切にチューニングすると、学習結果が改善する様子を観察できました。
今回、elite_rate と mutation_rate を変えて計算してみましたが、これにはスポットインスタンスを使用しました。elite_rate と mutation_rate を変えた各条件での計算に、1台づつスポットインスタンスを割り当てて実行しました。大量の計算を行いたいときに、必要に応じた量のサーバを柔軟に調達できるクラウドは素晴らしいと思いました。
Lambdaを使ってこれを実現するとなると、
- 各経路の距離計算をLambdaで100通り並列計算させ、それがすべて終わったら次世代を生成する関数を発火させる設計とする必要がある
- タイムアウト時間内に距離計算を終わらせなければならない
- どこかで処理の引渡が失敗したときの対策が必要
などのハードルがあります。まだまだLambdaでの実装まで道のりは長そう(というか実現可否すら不明)ですが、もし実現できたら報告します。