

はじめに
2015年4月入社の白鳥です。
前回の記事では、出費を減らしたい私が、過去の支出データをAmazon Machine Learning (Amazon ML)に分析させようとした話をしました。ただ、いろいろつまづいてしまったので、とりあえずつまづきポイントだけを挙げました。今回の記事ではいよいよ本題に入り、Amazon MLに家計分析をさせてみます。まず、家計分析をネタに、Amazon MLで回帰分析をする手順を示します。そして、分析の結果得られた出費予測を見ながら、なぜそのように予測されたのかを考えてみます。
Amazon ML では、以下3種類の分析を行うことができます。
- 二項分類 結果が2種類の選択肢に分かれる予測を行う
(例:○月×日に、私は△△にて買い物をするかしないか) - 多項分類 結果が3種類以上の選択肢に分かれる予測を行う
(例:○月×日に私が昼食をとるのは、コンビニAかコンビニBか食堂Cか) - 回帰分析 結果が数値となる予測を行う
(例:○月×日に私はいくら出費するか)
今回は3.の回帰分析を使って、私がこの先数カ月、毎日いくらずつ出費するのかを予測させます。
回帰分析の手順
Amazon ML による回帰分析の手順を、下図のフローチャートにに示します。まず、このフローチャートを使って全体の分析の流れを紹介します。そのあと、スクリーンショットを交えながら、分析の手順を詳しく紹介します。
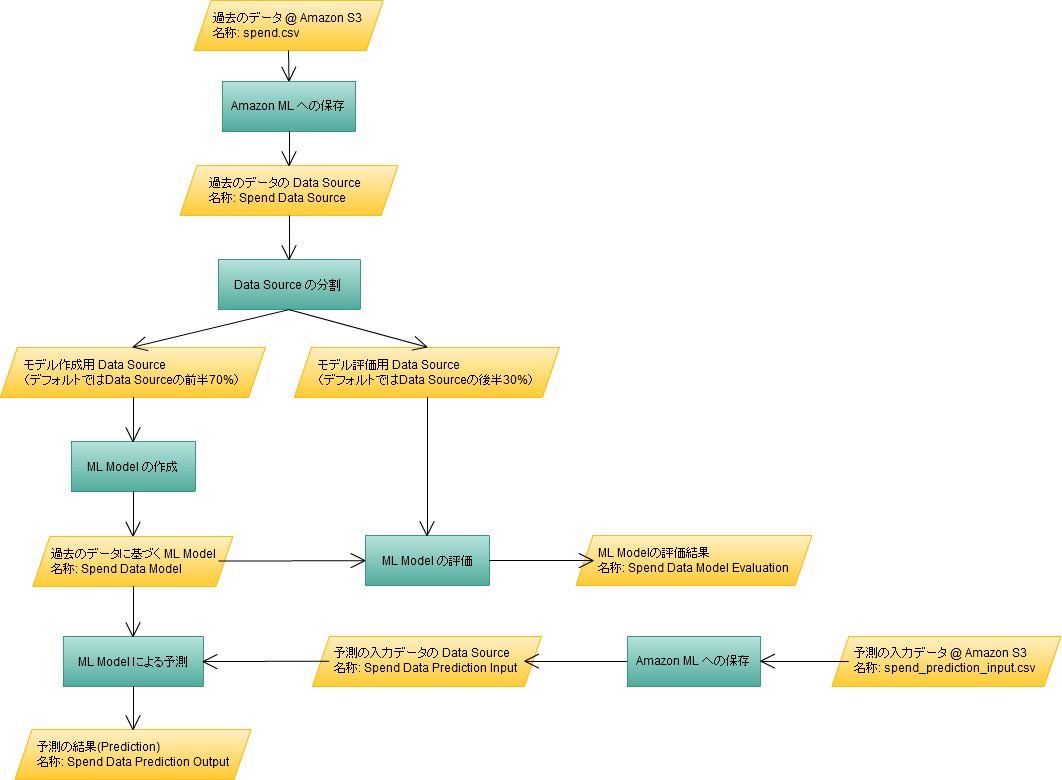
全体の分析の流れ
Amazon MLを使うには、モデルの構築に使用する過去の実績データを用意する必要があります。このデータは、S3に保存されたcsv、またはAmazon Redshift から読み込むことができます。今回は、Money Forwardから過去の支出データをcsvとして書き出し、S3に保存しておきます。次に、このcsvファイルをAmazon MLに取り込みます([1] Amazon ML への保存)。取り込まれたデータは"Data Source"としてAmazon ML内に保存されます。Data Source の保存時に、「過去の実績データに記録されている量のうち、どの量を予測するか」を設定します。例えば過去の支出データには、年・月・日・支出額などの量が記録されていますが、このうち支出額がモデルで予測する量として設定します。
この保存した Data Source を、モデル作成用とモデル評価用の2つに分けます([2] Data Source の分割)。デフォルトでは、前半70%のデータをモデル作成用、後半30%のデータをモデル評価用に使用するよう設定されています。モデル作成用 Data Source は、 "ML Model" と呼ばれるモデルを作成するのに使われます([3] ML Model の作成)。今回の例の場合、ML Modelは、年・月・日などの量から支出額を予測するモデルです。Amazon MLは、モデル作成用 Data Source として保存された過去の支出データから、年・月・日と支出額がどのような関係になっているかを分析し、式で表せるようにします。ML Model を作成できたら、モデル評価用 Data Source を使って、 ML Model の評価を行います([4] ML Model の評価)。ML Model が本当に支出額を予測できるかを確かめるため、 ML Model で予測した支出額と、モデル評価用 Data Source に記録された過去の支出額を比較します。
ML Model が支出額を適切に予測できることが確かめられたら、未来の支出額の予測を行います。そのためにはまず、予測の入力となるデータを Data Source として保存する必要があります([5] Amazon ML への保存)。今回の例の場合、年・月・日などの情報が、予測の入力データとなります。最後に、先ほど作成したML Modelを使うことで、入力されたデータから支出を予測することができます([6] ML Model による予測)。
分析の手順
ここからは具体的に、スクリーンショットを使いつつ回帰分析の手順を紹介します。今回は、下図のようなcsvファイル(spend.csv)を、過去のデータとして使います。

これは、Money Forwardから書き出したcsvファイルを編集して作成したものです。毎日いくら支出したかが、2014年12月1日~2015年10月9日の期間で記録されています。5列目には"city"という項目を設定しています。私は今年3月に札幌から東京に引っ越しました。引越の前後で支出の傾向が変わると考えたため、この行を追加しました。札幌に住んでいた期間は"Sapporo"、引っ越し後の期間には"Tokyo"と入力されています。また旅行などに出かけた日には、旅行先の都市名を入力してあります。このcsvファイルを、Amazon S3に作成したbucketに保存します。Amazon MLは、現在のところ、US East (N. Virginia) と EU (Ireland)のリージョンでのみ提供されています。S3からAmazon MLへのデータ読み込み時間を短くするため、bucketはUS StandardかEUに作成すると良いでしょう。私はUS Standardにbucketを作成し、US EastでAmazon MLを使いました。
さて、いよいよAmazon MLを立ち上げます。

Get startedをクリックすると、Data Sourceとして取り込むデータを選択する画面が立ち上がります。ここからの作業が「[1] Amazon ML への保存」にあたります。

今回はS3から取り込んだデータをData Sourceとするので、ラジオボタンは"S3"を選択します。S3 Locationの欄では、S3に保存したcsvを選択します。Bucket名を途中まで入力すると、csvファイルをサジェストしてくれます。Datasource nameの欄では、保存するData Sourceの名前を決めます。ここでは"Spend Data Source"という名前で保存することにします。"Verify"をクリックすると、Amazon MLがS3にアクセスするのを許可するか聞かれるので、"Yes"をクリックします。取り込みに成功すると、次のような画面が表示されます。"Continue"をクリックして、Data Sourceの設定を続けます。

次にData Sourceの設定を行う画面が立ち上がります。
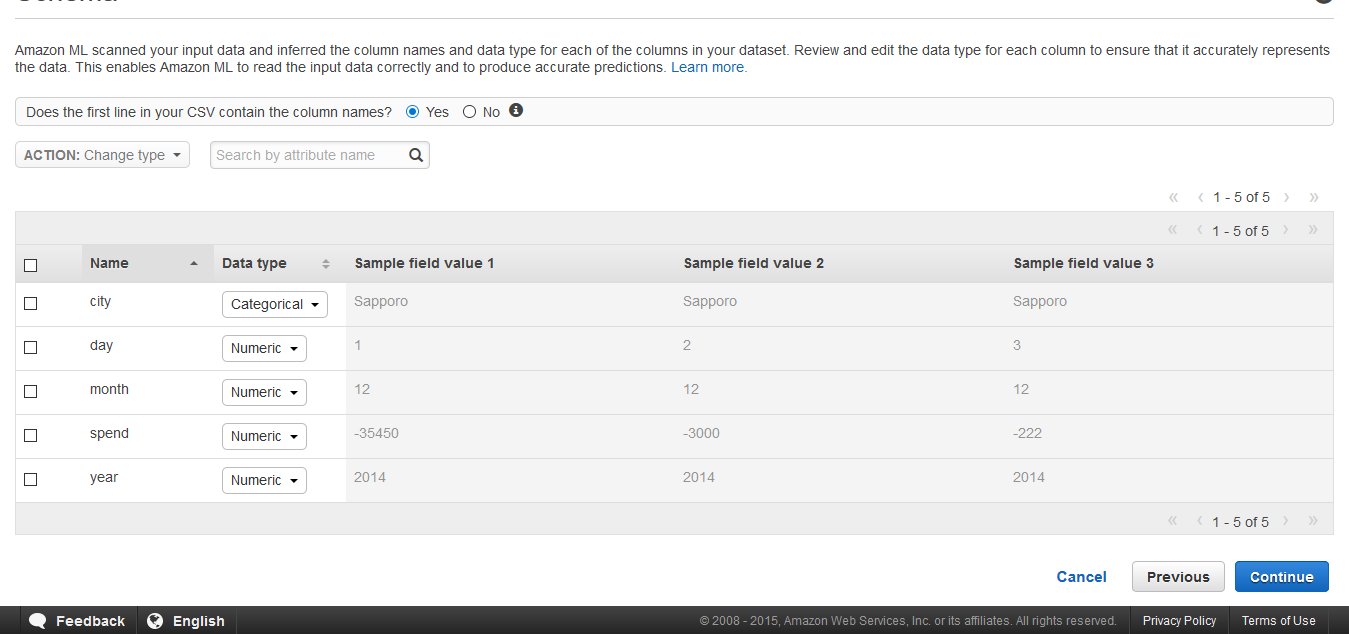
ここでは、csvの各列がどのような意味を持っているのか指定します。まず、1番上の行が各列の名前になっているかを聞かれます。今回のcsvの1行目には、先ほど示した通り、year, month, day, spend, cityなど各列の名前が書かれているので、"Yes"のボタンを選択します。その下の表では、各列に対してData typeを指定します。Data typeには、以下の表に示す4種類があります。今回の例では、"city"のみがCategorical, 他の列はNumericとなります。
| Data type | 説明 | 今回該当するattribute |
| Numeric | 数値データ | year, month, day, spend |
| Categorical | 各行のデータを分類するための文字や数字 | city |
| Binary | Yes/No などの2つに分類する値 | なし |
| Text | スペースで区切られた文字列 | なし |
各列のData typeを指定できたら、"Continue"をクリックします。すると、target attributeの設定に移ります。
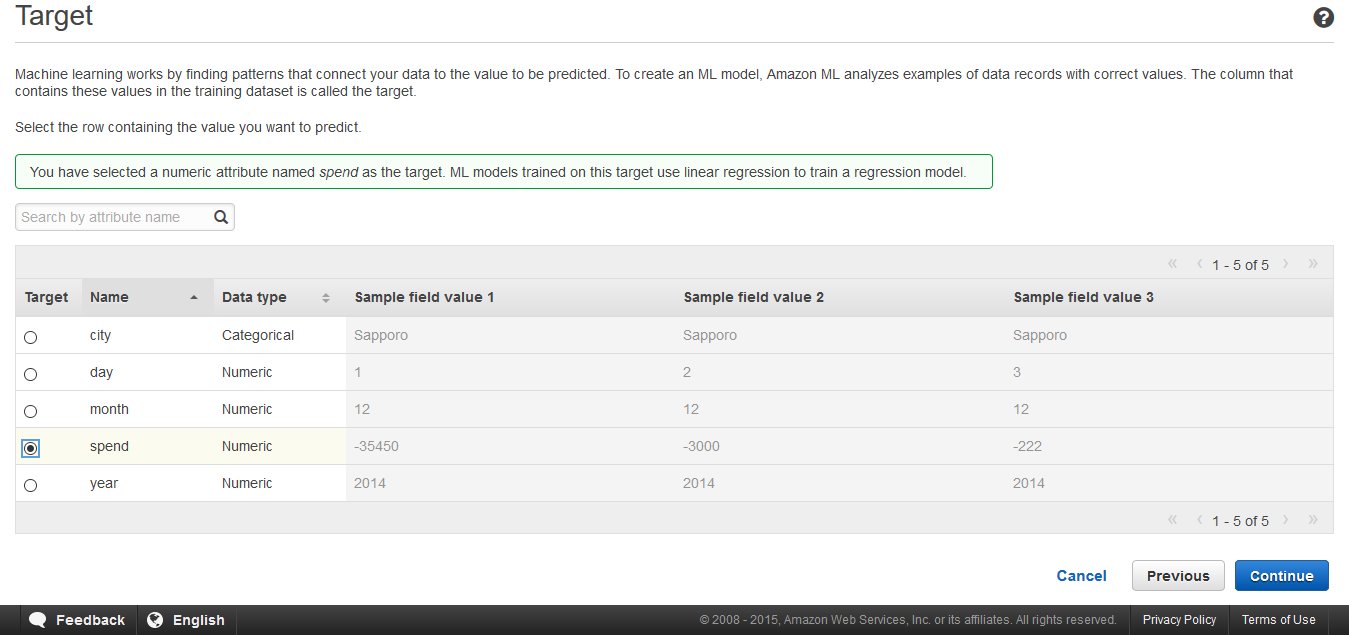
Target attributeとは「モデルを使って予測させたい量」を指します。今回は、支出を予測させようとしているので、"spend"がtarget attributeとなります。よって、上図のようにボタンを選択し、"Continue"をクリックします。
次の画面でRow identifierの有無を聞かれるので、"No"をクリックします。最後にReview画面が表示され、Data Sourceの作成は完了となります。
次に、「[2] Data Source の分割」 「[3] ML Model の作成」 「[4] ML Model の評価」の設定を一気に行います。Data Source作成のReview画面で"Continue"をクリックすると、自動的にモデル作成の設定画面に移ります。先ほど作成した"Spend Data Source"が、モデルの素になるData Sourceとして既に選択された状態で設定を進めることができます。
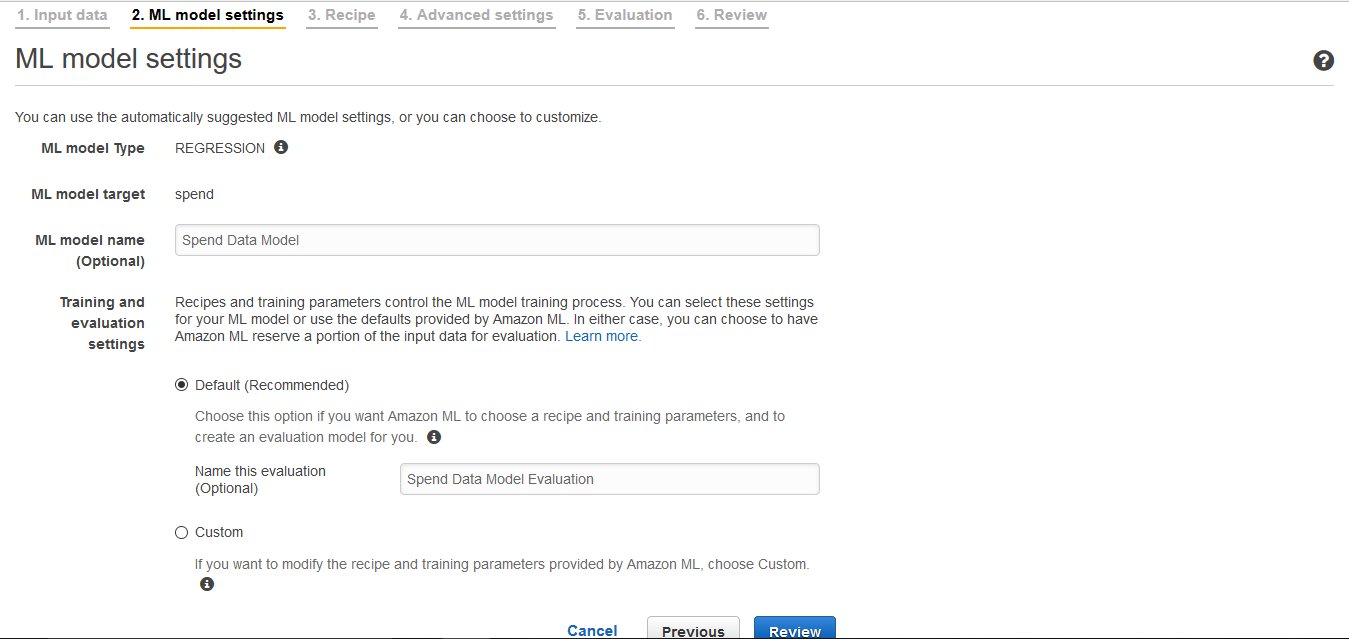
ここで設定する項目は、作成するML Modelと、Modelの評価結果の保存時の名前のみです。ML Modelには"Spend Data Model", 評価結果には"Spend Data Model Evaluation"と名前を付けることにします。
自動的に設定されている項目についても説明しておきます。まず、ML model Typeの欄には、二項分類、多項分類、回帰分析のどれを行うかが示されています。今回はREGRESSION(= 回帰分析)が選択されています。このML model Typeは、target attributeのData typeによって自動的に決定されます。Target attributeがNumericであれば回帰分析、Categoricalであれば多項分類、Binaryであれば二項分類に自動的に設定されます。Training and evaluation settingsでは、「[2] Data Source の分割」での分割の割合を設定できます。今回はDefaultを選択したので、「[3] ML Model の作成」に70%、 「[4] ML Model の評価」に30%のデータが使われます。またCustomにすると、この割合以外のモデル作成パラメータを変更することができます。
"Review"をクリックすると、Review画面に移ります。設定に間違いがないか確認し、"Finish"をクリックします。
ここまでの設定を終えると、「[2] Data Source の分割」 「[3] ML Model の作成」 「[4] ML Model の評価」の処理が一気に行われます。Amazon MLのダッシュボードを見てみましょう。

今回のData Sourceはわずか300件ほどしかデータがないため、10分足らずでEvaluationまで全て"Completed"になりました。
さて、いよいよ「[5] Amazon ML への保存」 「[6] ML Model による予測」を行います。まず、予測の入力データとなるcsvファイル (spend_prediction_input.csv) を用意します。今回の例の場合、このcsvファイルは以下のような内容になります。

基本的な構造は、最初に用意したcsv(spend.csv)と同じです。ただしspendの列はありません。またyear, month, dayには支出を予測したい日の日付を入力し、cityにはそれらの日、主にどこにいるかを入力してあります。日付は、2015年11月1日~2016年1月31日の3か月間を入力してあります。city欄は、2015年12月30日~2016年1月4日までは"Numazu"、他の日は"Tokyo"としています。つまり、年末年始は私の実家のある静岡県沼津市で過ごし、他の日は通常通り東京で過ごすと仮定しています。このようなcsvファイルを、S3のbucketに保存しておきます。
csvファイルを用意できたら、Amazon MLのダッシュボードから"Create new Batch prediction"を選択します。

まず、予測に使うML Modelを選択します。ここでは先ほど作成した"Spend Data Model"を選択します。ML Modelのリストから"Spend Data Model"を選択すると、"Continue"をクリックできるようになるので、クリックして次の画面に移ります。
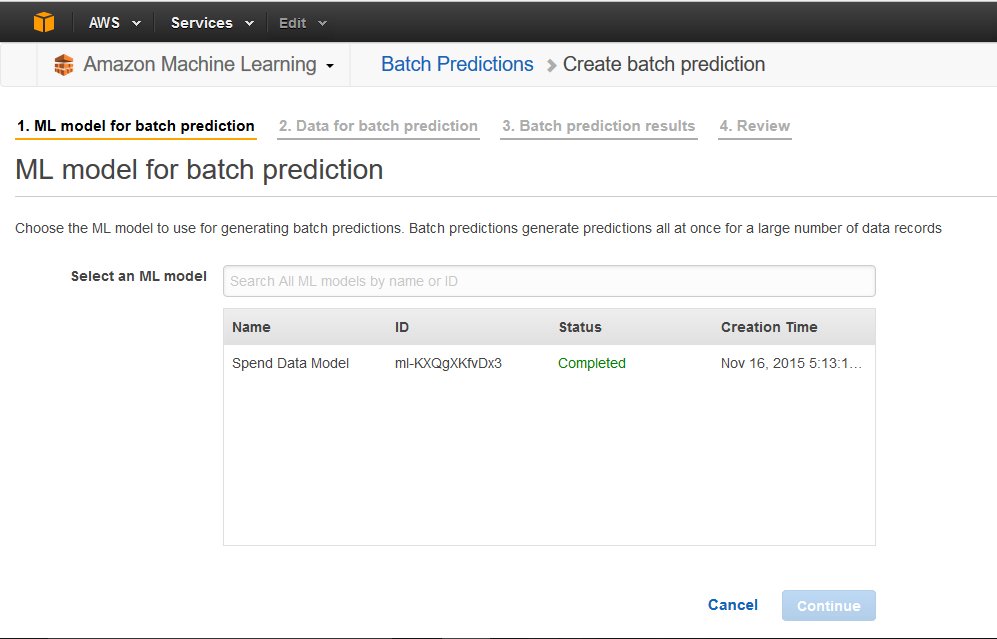
次に、予測の入力データをAmazon MLに取り込みます。今回はS3に保存されたcsvからData Sourceを作成するので、"My data is in S3, and I need to create a datasource"を選択します。このData Sourceの保存時の名前を決め、S3に保存したcsvファイル(spend.csv)を指定します。今回用意したcsvの1行目には各列の名前が書かれているので、"Does the first line...?"の答えはYesを選択します。"Verify"をクリックすると、Amazon MLがS3にアクセスするのを許可するか聞かれるので、Yesを選択します。
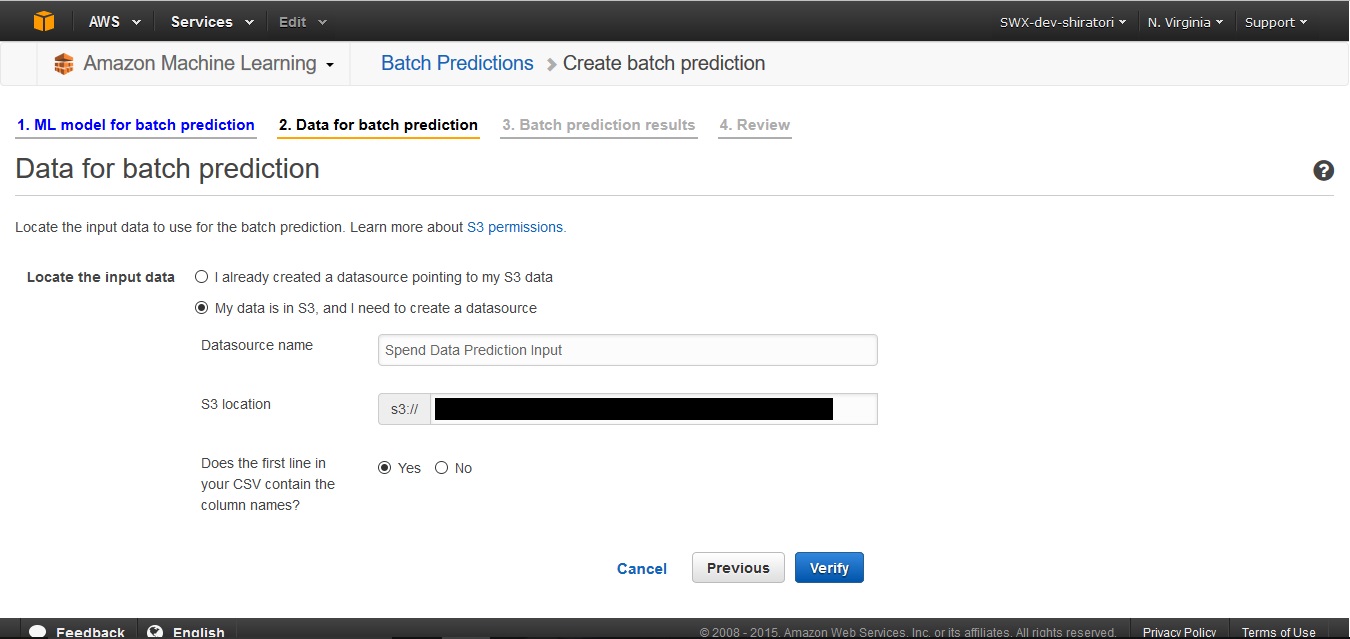
最後に、モデルによる予測結果の保存に関する設定をします。予測結果のcsvを保存するS3のbucketと、Amazon ML内に保存する予測結果(Prediction)の保存名を入力します。この例では、Predictionに"Spend Data Prediction Output"という名前を付けて保存します。
以上で、ML Modelでの予測を行うのに必要な設定は全て完了です。設定内容をReviewする画面が表示されるので、"Finish"をクリックします。今回予測するデータは92個(92日分)ですが、この程度であれば5分ほどで予測が完了します。先ほど指定したS3のbuctetに予測結果がgzip形式で保存されています。解凍すると、予測結果が記録されたcsvファイルが得られます。
予測結果を見てみる
今回の例で得られた予測結果を、下図のグラフに示します。棒グラフは過去の支出実績、折れ線グラフはAmazon MLによる未来の支出予測です。2015年7月~2015年9月の実績データと、2015年11月~2016年1月の予測データを示しています。横軸は各月の1日~31日を意味しています。
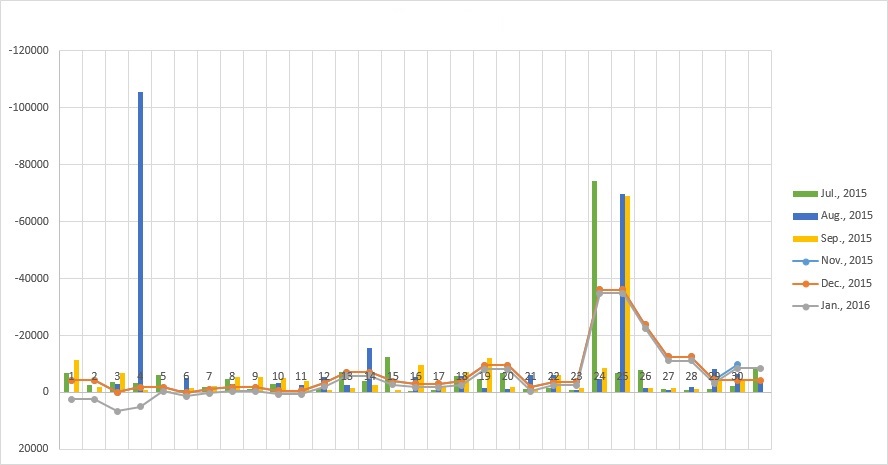
まず、過去の支出データ(棒グラフ)を見ると、いくつか突出して支出額が大きい日があるのが分かります。8月4日、7月24日、8月25日、9月25日などです。このうち、8月4日については、AWSのトレーニングに申し込みをしたため、支出が大きくなっています。7月24日、8月25日、9月25日は家賃の支払日であったため、支出が大きくなっています。他の日の支出額は1日当たり数百円~数千円くらいで、たまに1万円を超える日がある程度です。毎月14日頃と19日頃は、出費額が多くなる傾向があるようです。
次に、予測された支出データ(折れ線グラフ)を見てみます。まず、毎月24日~28日に支出が多くなると予測されています。過去の支出データにおいてこの時期に家賃の支払いが発生しているため、この傾向をもとにAmazon MLが予測した結果だと考えられます。一方で、8月4日の大型出費については、予測にほぼ影響していません。この支出は1度きりのものなので、Amazon MLはうまく判断してくれています。毎月14日頃と19日頃に出費が増える傾向についても、予測に反映されています。この時期は無駄遣いしている可能性が高いので、財布のひもを引き締めようと思います。最後に、実家に帰ると仮定した時期(12月30日~1月4日)については、他の月の同じ時期よりも出費が少なくなっています。過去のデータにて、実家に帰ると出費が減る(=食事を作ってもらってグダグダしている)傾向があるので、これを反映した結果と思われます。ここまで予測されるとちょっと困りますね。
まとめ
今後数カ月の出費を予想させるというネタを使って、Amazon MLで回帰分析をさせる手順を示しました。みなさんがAmazon MLを使うときの参考になれば幸いです。個人的な感想や教訓としては、
- そこそこよく予測できている
- 毎月14日頃と19日頃は出費しがちなので注意しよう
- 実家でグダグダしているのを見透かされて悔しい
といったことが挙げられます。11月については、実績データも溜まってきているので、予測と実績を比べてみるのも面白いかなと思っています。